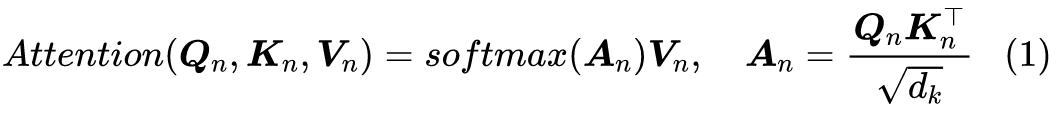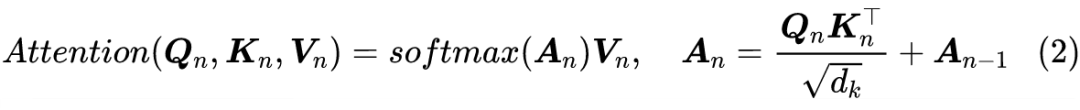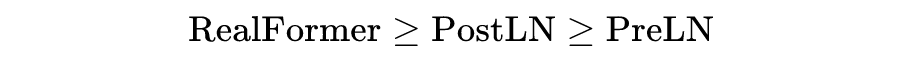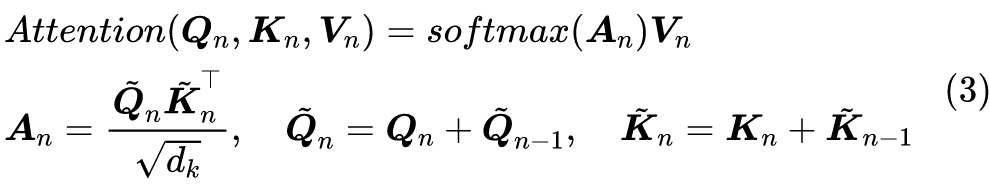©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
大家知道 Layer Normalization 是 Transformer 模型的重要组成之一,它的用法有 PostLN 和 PreLN 两种,论文 On Layer Normalization in the Transformer Architecture [1] 中有对两者比较详细的分析。简单来说,就是 PreLN 对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN 的性能似乎总略差于 PostLN。
最近 Google 的一篇论文提出了 RealFormer 设计,成功地弥补了这个 Gap,使得模型拥有 PreLN 一样的优化友好性,并且效果比 PostLN 还好,可谓“鱼与熊掌兼得”了。
论文标题:
RealFormer: Transformer Likes Residual Attention
论文链接:
https://arxiv.org/abs/2012.11747
形式
RealFormer 全称为“Re sidual A ttention L ayer Transformer ”,即“残差式 Attention 层的 Transformer 模型”,顾名思义就是把残差放到了 Attention 里边了。
关于这个名字,还有个小插曲。这篇文章发布的时候,RealFormer 其实叫做Informer,全称为“Resi dual Atten tion Transformer ”,原论文名为 Informer: Transformer Likes Informed Attention [2] ,显然从 Informer 这个名字我们很难想象它的全称,为此笔者还吐槽了 Google 在起名方面的生硬和任性。
隔了一天之后,发现它改名为 RealFormer 了,遂做了同步。不知道是因为作者大佬看到了笔者的吐槽,还是因为 Informer 这个名字跟再早几天的一篇论文 Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
[3]
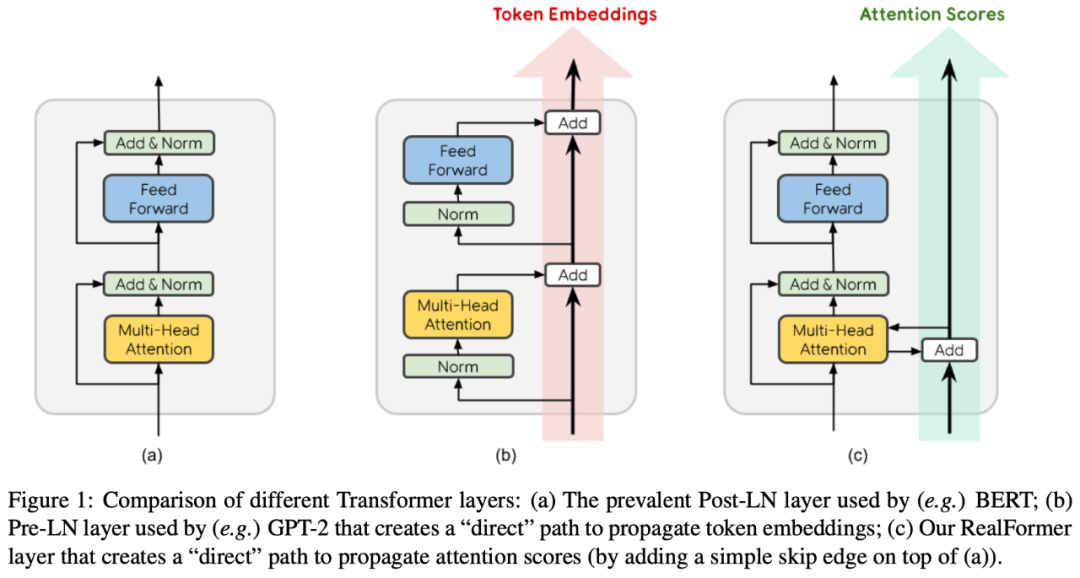
▲ PostLN、PreLN和RealFormer结构示意图
说回模型,如上图所示,RealFormer 主要是把残差放到了 Attention 矩阵上面了,而整体依然保持了 PostLN 的结构,因此既保持了 PostLN 的性能,又融合了残差的友好。具体来说,就是原来第 n 层的 Attention 为:
实验
当然,那么快就“全文终”是不可能的,好歹也得做做实验看看效果,但只看改动的话,确实已经终了,就那么简单。原论文做的实验很多,基本上所有的实验结果都显示在效果上:
看来,这次 PostLN 可能真的需要退场了。部分实验结果如下:
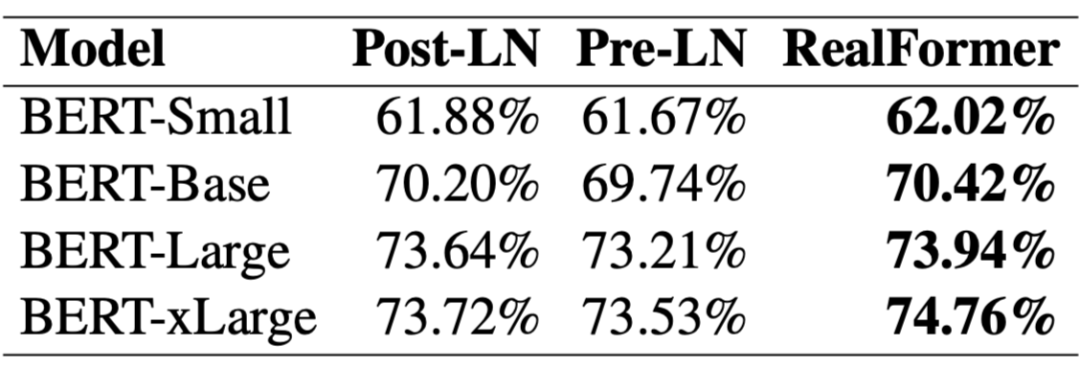
▲ MLM准确率对比
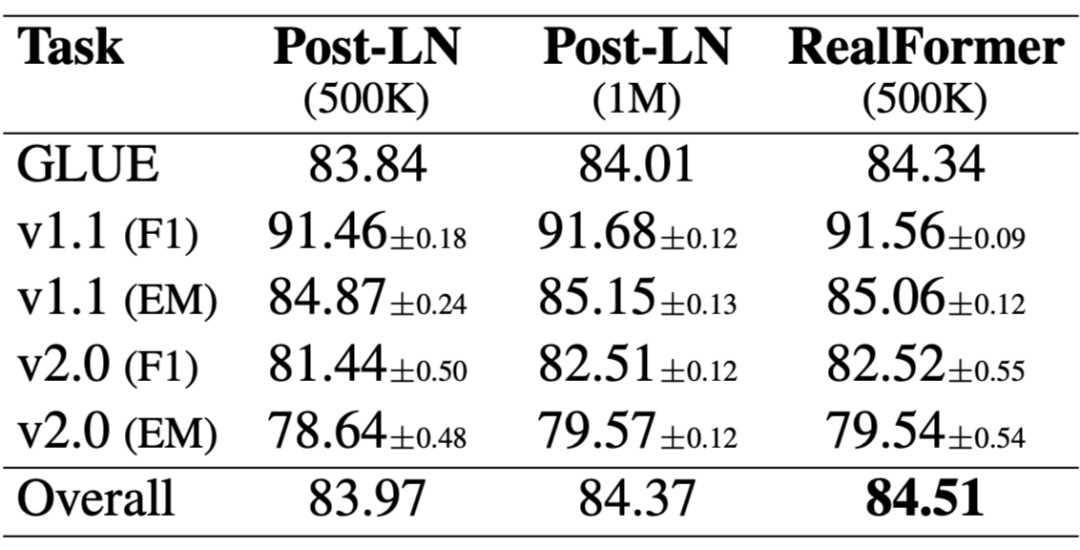
▲ SQuAD评测对比
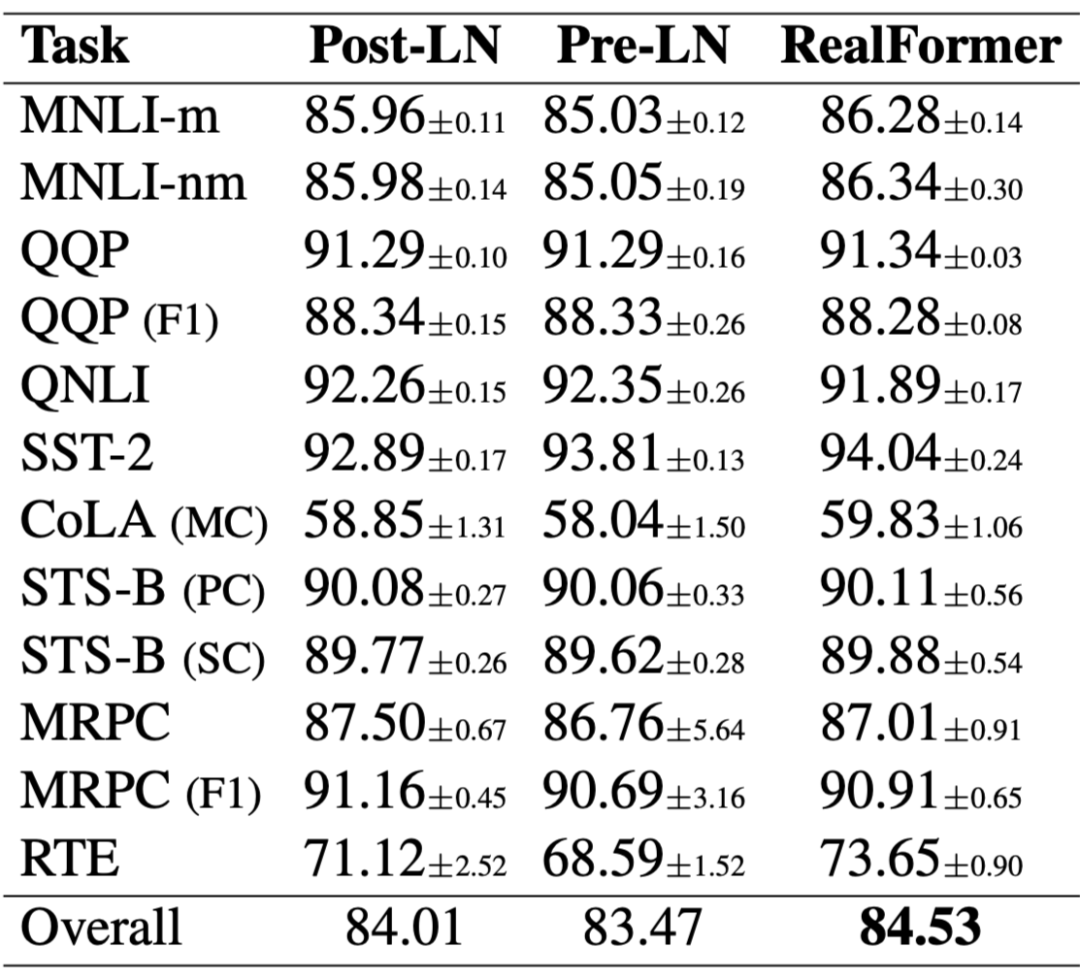
▲ GLUE评测对比
▲ 不同训练步数效果对比
值得特别指出的是第一张图和第四张图。从第一张图我们可以看到,对于 RealFormer 结构,加大模型规模(large 到 xlarge)可以带来性能的明显提升,而 ALBERT 论文曾经提到加大 BERT 的模型规模并不能带来明显受益,结合两者说明这可能是 PostLN 的毛病而不是 BERT 的固有毛病,换成 RealFormer 可以改善这一点。
从第四张图我们可以看到,RealFormer 结构训练 50 万步,效果就相当于 PostLN 训练 100 万步,这表明 RealFormer 有着很高的训练效率。
除了上述实验外,论文还对比了不同学习率、不同 Dropout 比例的效果,表明 RealFormer 确实对这些参数是比较鲁棒的。原论文还分析了 RealFormer 的 Attention 值分布,表明 RealFormer 的 Attention 结果更加合理。
这一节我们对 RealFormer 做一个简单的思考分析。
RealFormer 对梯度下降更加友好,这不难理解,因为
的设计确实提供了一条直通路,使得第一层的 Attention 能够直通最后一层,自然就没有什么梯度消失的风险了。
相比之下,PostLN 是
的结构,看上去
防止了梯度消失,但是
这一步会重新增加了梯度消失风险,造成的后果是初始阶段前面的层梯度很小,后面的层梯度很大,如果用大学习率,后面的层容易崩,如果用小学习率,前面的层学不好,因此 PostLN 更难训练,需要用小的学习率加 warmup 慢慢训。
那么 PreLN 改善了梯度状况,为什么又比不上 PostLN 呢?按照笔者的猜测,PreLN 每一步都是
的形式,到了最后一层就变成了
的形式,一层层累加,可能导致数值和方差都很大,所以最后“迫不得已”会强制加一层 Layer Norm 让输出稳定下来。这样,尽管 PreLN 改善了梯度状况,但它本身设计上就存在一些不稳定因素,也许这就是它效果略差的原因。
事实上,很早就有人注意到残差的这个特点会造成不稳定,笔者之前研究 GAN 的时候,就发现 Which Training Methods for GANs do actually Converge?
[4]
一文中的实现就把
换成了
。受到他们实现的启发,笔者也试过将
换成
,其中
是初始化为 0 的可训练标量参数,也取得不错的效果。
今年年初的论文 ReZero is All You Need: Fast Convergence at Large Depth
[5]
则正式地提出了这个方法,命名为 ReZero,里边的实验表明用 ReZero 可以干脆去掉 Layer Norm。遗憾的是,ReZero 的论文没有对 Transformer 做更多的实验,而 RealFormer 也没有比较它与 ReZero 的效果差别。
读者可能会反驳,既然 PreLN 存在问题,那 RealFormer 的
不也是存在同样的叠加问题吗?如果只看
,那么确实会有这样的问题,但别忘了
后面还要做个 softmax 归一化后才参与运算,也就是说,模型对矩阵
是自带归一化功能的,所以它不会有数值发散的风险。
而且刚刚相反,随着层数的增加,
的叠加会使得
的元素绝对值可能越来越大,Attention 逐渐趋于 one hot 形式,造成后面的层梯度消失,但是别忘了,我们刚才说 PostLN 前面的层梯度小后面的层梯度大,而现在也进一步缩小了后面层的梯度,反而使得两者更同步从而更好优化了;
另一方面,Attention 的概率值可能会有趋同的趋势,也就是说 Attention 的模式可能越来越稳定,带来类似 ALBERT 参数共享的正则化效应,这对模型效果来说可能是有利的,直觉上来说,用 RealFormer 结构去做 FastBERT
[6]
之类的自适应层数的改进,效果会更好,因为 RealFormer 的 Attention 本身会有趋同趋势,更加符合 FastBERT 设计的出发点。
此外,我们也可以将 RealFormer 理解为还是使用了常规的残差结构,但是残差结构只用在
而没有用在
上:
这在一定程度上与
是等价的,而 PreLN 相当于
都加了残差。
为啥
“不值得”一个残差呢?从近来的一些相对位置编码的改进中,笔者发现似乎有一个共同的趋势,那就是去掉了
的偏置,比如像 NEZHA 的相对位置编码,是同时在 Attention 矩阵(即
)
和
上施加的,而较新的 XLNET 和 T5 的相对位置编码则只施加在 Attention 矩阵上,所以,似乎去掉
的不必要的偏置是一个比较好的选择,而 RealFormer 再次体现了这一点。
总结
实验结果表明,RealFormer 同时有着 PostLN 和 PreLN 的优点,甚至比两者更好,是一个值得使用的改进点。
[1] https://arxiv.org/abs/2002.04745
[2] https://arxiv.org/abs/2012.11747v1
[3] https://arxiv.org/abs/2012.07436
[4] https://arxiv.org/abs/1801.04406
[5] https://arxiv.org/abs/2003.04887
[6] https://arxiv.org/abs/2004.02178
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。