FX2TRT-Pytorch转TensorRT新方式-实践torch.fx第三篇

极市导读
实践torch.fx第三篇,Pytorch转TensorRT新方式,附详细代码。 >>算法offer直通车、50万总奖池!高通人工智能创新应用大赛等你来战!
接着唠嗑FX~
拖了一阵子没有更新,就发生了两件大事儿:
-
torch-tensorrt仓库移动到Pytorch主仓库下,更名为pytorch/TensorRT -
Pytorch仓库将fx2trt分支由主仓库移到了
pytorch/TensorRT仓库
因为和我之前跑通的版本变动较大(毕竟隔了几个月hh),决定先观察观察再写,然后就一直拖啊一直拖。然后拖到了现在,随后也看到了官方的FX2TRT的 User Guide(https://github.com/pytorch/TensorRT/blob/master/docsrc/tutorials/getting_started_with_fx_path.rst) :

Pytorch仓库的fx2trt代码库转移到pytorch/TensorRT中,变为了其中的一部分:FX Frontend。pytorch/TensorRT也就是之前的Torch-TensorRT库,现在统一了,除了可以将torchscript的模型转化为TensorRT模型,也可以将FX模型转化为TensorRT模型。
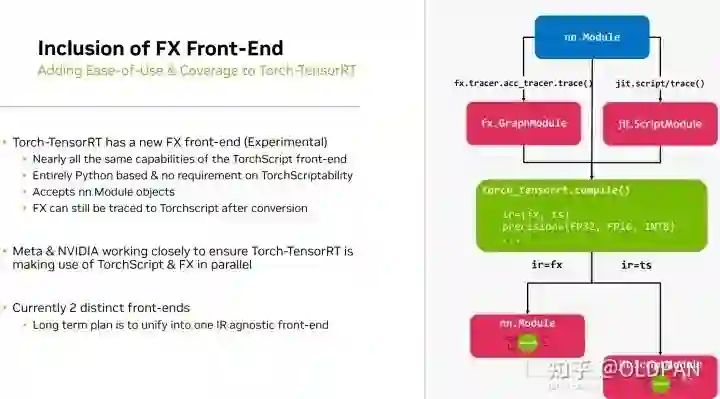
Pytorch/TensorRT
这个库区别于NVIDIA官方的TensorRT仓库,是Pytorch自己的 TensorRT仓库(https://github.com/pytorch/TensorRT) ,简单介绍如下:
PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT
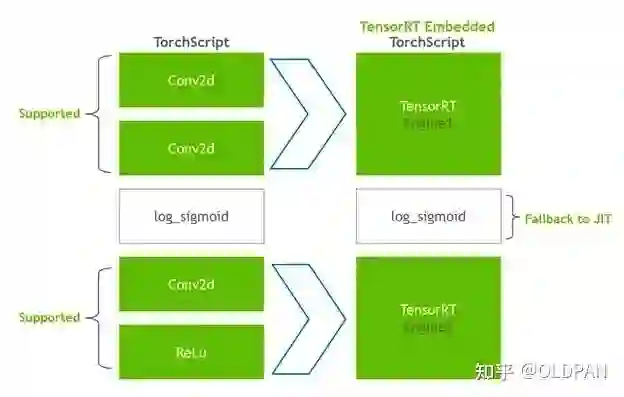
其实前身是TRtorch也叫作torch-TensorRT,我之前也写过篇关于这个的回答(https://www.zhihu.com/question/436143525/answer/2267845251) 。这个库的主要功能是无缝将torchscript的模型引入TensorRT的加速,使用最接近Pytorch的torchscript的生态去加速模型,充分利用TensorRT和TVM等优秀的工具,不需要把模型拆成好几部分,直接使用torchscript这个运行时去缝合,对于某些模型来说是很合适的:
不过本文的重点不是这个,我们关注的fx2trt这个库挪到了这个仓库中,看来Pytorch是想把这些和TensorRT有关的库都整合在一起,也挺好。这里我只用到了fx2trt,所以只执行以下命令即可:
git clone https://github.com/pytorch/TensorRT/commits/master
cd py
python3 setup.py install --fx-only
看了下其中FX部分的代码结构,基本没什么变动,就是单独拎了出来。
fx2trt这个工具就是为了配合FX,将FX后的模型转化为TensorRT,大概分为四个步骤:
-
先trace模型 -
然后split trace后的模型,分为支持trt和不支持trt的部分 -
将支持trt的部分model转化为trt -
然后得到一个新的nn.module,其中subgraph就是一个trt的engine嵌入进去了
看个例子
可以简单看下官方的示例代码,在TensorRT/examples/fx/lower_example.py有一个resnet18的例子。首先获取resnet18的模型,没什么好说的:
model = torchvision.models.resnet18(pretrained=True)
然后通过compile函数来对model进行编译,这个compile函数内部其实就是调用了一个Lowerer类,Lowerer类会根据config配置创建fx2trt的pipeline,之后的torch_tensorrt会统一这个接口,根据fx和ts(torchscript)模型来分别进行compile,不过这里就只说fx了:
# 这里model是nn.module 来自 torchvision.models.resnet18(pretrained=True)
lowered_module = compile(
module,
input, # input = [torch.rand(128, 3, 224, 224)
max_batch_size=conf.batch_size,
lower_precision=LowerPrecision.FP16 if conf.fp16 else LowerPrecision.FP32,
)
# 其中compile调用了Lowerer,是个help类,搭建fx2trt的pipeline
def compile(
module: nn.Module,
input,
max_batch_size: int = 2048,
max_workspace_size=1 << 25,
explicit_batch_dimension=False,
lower_precision=LowerPrecision.FP16,
verbose_log=False,
timing_cache_prefix="",
save_timing_cache=False,
cuda_graph_batch_size=-1,
dynamic_batch=True,
is_aten=False,
) -> nn.Module:
lower_setting = LowerSetting(
max_batch_size=max_batch_size,
max_workspace_size=max_workspace_size,
explicit_batch_dimension=explicit_batch_dimension,
lower_precision=lower_precision,
verbose_log=verbose_log,
timing_cache_prefix=timing_cache_prefix,
save_timing_cache=save_timing_cache,
cuda_graph_batch_size=cuda_graph_batch_size,
dynamic_batch=dynamic_batch,
is_aten=is_aten,
)
lowerer = Lowerer.create(lower_setting=lower_setting)
return lowerer(module, input)
Lowerer.create的时候,根据传递来的lower_setting参数构建pipeline,传递的参数也很容易理解:
-
比如转换精度,FP16还是FP32 -
示例输入用于trace以及后续测试 -
以及一些其他tensorrt常见的参数,比如workspace大小等等
pipeline的话,存在于pass管理器中。上一篇说过FX就是个AI编译器,而编译器中有个概念叫做pass,代表对代码的各种优化,所以FX中的PASS也一样,只不过变化为对模型的各种优化,看了下大概是以下一些:
# 这些pass
def build_trt_lower_pipeline(
self, input: Input, additional_input: Optional[Input] = None
) -> PassManager:
self._input = input
self._additional_input = additional_input
passes = []
passes.append(self._default_replace_mutable_op_pass())
passes.append(self._const_fold_pass())
passes.append(self.graph_optimization_pass())
passes.append(self._split_pass())
passes.append(self._trt_lower_pass())
pm = PassManager.build_from_passlist(passes)
return pm
上述这些pass操作,其实就是FX中的transform,上一篇也说道过:
Your transform will take in an torch.nn.Module, acquire a Graph from it, do some modifications, and return a new torch.nn.Module. You should think of the torch.nn.Module that your FX transform returns as identical to a regular torch.nn.Module – you can pass it to another FX transform, you can pass it to TorchScript, or you can run it. Ensuring that the inputs and outputs of your FX transform are a torch.nn.Module will allow for composability.
比如replace_mutable_op这个函数,对输入的torch.fx.GraphModule进行修改,修改后recompile()重新构建graphModule,再返回torch.fx.GraphModule:
def replace_mutable_op(module: torch.fx.GraphModule) -> torch.fx.GraphModule:
if not isinstance(module, torch.fx.GraphModule):
return module
# Before any lowering pass, replace mutable ops like torch.fill_
# Because fx cannot deal with inplace ops
for n in module.graph.nodes:
# TODO: add more mutable ops
if (n.op == "call_method" and n.target == "fill_") or (
n.op == "call_function" and n.target == torch.fill_
):
# Replace mutable op only if the modified variable
# is used by the rest of the graph
# only through this op
if set(n.args[0].users.keys()) == {n}:
with module.graph.inserting_after(n):
# TODO: move this outside?
def fill_with_mul_zero_and_add(*args):
return args[0].mul(0.0).add(args[1])
new_node = module.graph.create_node(
"call_function", fill_with_mul_zero_and_add, args=n.args
)
n.replace_all_uses_with(new_node)
module.graph.erase_node(n)
module.recompile()
return module
总之,经过compile的模型内部已经包含trt-engine了,可以直接拿来跑和benchmark:
lowered_module = compile(
module,
input,
max_batch_size=conf.batch_size,
lower_precision=LowerPrecision.FP16 if conf.fp16 else LowerPrecision.FP32,
)
time = benchmark_torch_function(conf.batch_iter, lambda: lowered_module(*input))
benchmark的结果也很显然,trt模型肯定比原始pytorch快很多,尤其是FP16下,resnet18这种小模型可以提升将近4倍多的QPS:
== Start benchmark iterations
== End benchmark iterations
== Benchmark Result for: Configuration(batch_iter=50, batch_size=128, name='CUDA Eager', trt=False, jit=False, fp16=False, accuracy_rtol=-1)
BS: 128, Time per iter: 31.35ms, QPS: 4082.42, Accuracy: None (rtol=-1)
== Benchmark Result for: Configuration(batch_iter=50, batch_size=128, name='TRT FP32 Eager', trt=True, jit=False, fp16=False, accuracy_rtol=0.001)
BS: 128, Time per iter: 21.53ms, QPS: 5944.90, Accuracy: None (rtol=0.001)
== Benchmark Result for: Configuration(batch_iter=50, batch_size=128, name='TRT FP16 Eager', trt=True, jit=False, fp16=True, accuracy_rtol=0.01)
BS: 128, Time per iter: 7.09ms, QPS: 18056.38, Accuracy: None (rtol=0.01)
运行环境
简单介绍了下Torch-TensorRT,接下来进入正篇。因为写第一篇FX文章比较久了,第二篇也挺久了(好吧我太能拖了),所以写第三篇的时候(2022-10-29),为了保证文章内容质量...就更新一下测试fx的环境吧。拉的最新环境,torch和torchvision以及torch-tensorrt全部拉成最新,亲手编译的:
torch 1.14.0a0+gita0c2a7f /root/code/pytorch
torch-tensorrt 1.3.0a0+5a7ac8f3
torch-tensorrt-fx2trt 0.1 /usr/local/lib/python3.8/dist-packages/torch_tensorrt_fx2trt-0.1-py3.8.egg
torchvision 0.14.0a0+d0d7058 /root/code/vision
虽然FX更新挺快,到现在1.14版本为止,FX依然是个beta。但有好的一点,更新了最新的环境后,之前的代码改动稍稍改动(不超2行)就可以运行。可以说明FX的向下兼容做的挺好,大家可以放心使用。
测试模型
因为之前的模型找不到了,所以需要重新找个模型测试FP32(pytorch)和INT8量化后(pytorch-fx以及TensorRT)的精度。
我去年跑fx2trt的时候使用的是resnet50版本的CenterNet,而且修改了Centernet后面的upsample层,将其输入输出通道设为相同:
# 输入in_channels输出通道out_channels必须一致才可以
nn.ConvTranspose2d(
in_channels=planes,
out_channels=planes,
kernel_size=kernel,
stride=2,
padding=padding,
output_padding=output_padding,
bias=self.deconv_with_bias))
# groups必须为1才行
up = nn.ConvTranspose2d(
out_dim, out_dim, f * 2, stride=f, padding=f // 2,
output_padding=0, groups=1, bias=False)
为什么这样搞,因为TensorRT在量化反卷积的时候有bug,必须满足一定条件的反卷积才可以正常解析(当然,不量化的时候没有问题),看了下issue的反馈,大概在8.5版本会解决大部分关于反卷积的问题(反卷积的问题真的多)。相关issue链接:
-
https://github.com/NVIDIA/TensorRT/issues/1699 -
https://github.com/NVIDIA/TensorRT/issues/1519 -
https://github.com/NVIDIA/TensorRT/issues/2280
所以没办法,只能自己训一个模型,我这里采用resnet50为backbone的CenterNet,除了将模型最后部分反卷积改了下通道数,其余和官方的一致。基于自己的数据集训练了个二分类模型,检测人和手的。
FX2TRT
有了模型,开始进入正题!
上文提到过,新版的FX接口略略微微有一些变动,上一篇中prepare_fx参数backend配置名称变为backend_config;以及converter函数封装了一层新的函数convert_to_reference_fx,也就是将is_reference参数挪到里头了,不再使用convert_fx:
def convert_to_reference_fx(
graph_module: GraphModule,
convert_custom_config: Union[ConvertCustomConfig, Dict[str, Any], None] = None,
_remove_qconfig: bool = True,
qconfig_mapping: Union[QConfigMapping, Dict[str, Any], None] = None,
backend_config: Union[BackendConfig, Dict[str, Any], None] = None,
) -> torch.nn.Module:
torch._C._log_api_usage_once("quantization_api.quantize_fx.convert_to_reference_fx")
return _convert_fx(
graph_module,
is_reference=True,
convert_custom_config=convert_custom_config,
_remove_qconfig=_remove_qconfig,
qconfig_mapping=qconfig_mapping,
backend_config=backend_config,
)
其他的没啥变化。
上一篇中,我们将模型通过prepare_fx和convert_to_reference_fx之后(不明白的强烈建议回顾上一篇),得到了最终的reference量化模型。经过convert_to_reference_fx后的模型,其实是simulator quantization,也就是模拟量化版本。并不包含任何INT8的算子,有的只是Q、DQ操作以及FP32的常规算子,以及我们校准得到的scale和offset用于模拟模型的量化误差。实际模型执行的时候是这样:
def forward(self, input):
input_1 = input
# 首先得到量化参数scale和zero-point
backbone_conv1_input_scale_0 = self.backbone_conv1_input_scale_0
backbone_conv1_input_zero_point_0 = self.backbone_conv1_input_zero_point_0
# 然后量化输入
quantize_per_tensor = torch.quantize_per_tensor(input_1, backbone_conv1_input_scale_0, backbone_conv1_input_zero_point_0, torch.qint8);
input_1 = backbone_conv1_input_scale_0 = backbone_conv1_input_zero_point_0 = None
# 然后反量化输入
dequantize = quantize_per_tensor.dequantize(); quantize_per_tensor = None
# 实际输入FP32算子的input是反量化后的
backbone_conv1 = self.backbone.conv1(dequantize); dequantize = None
...
dequantize_80 = quantize_per_tensor_83.dequantize(); quantize_per_tensor_83 = None
head_angle_2 = getattr(self.head.angle, "2")(dequantize_80); dequantize_80 = None
head_angle_2_output_scale_0 = self.head_angle_2_output_scale_0
head_angle_2_output_zero_point_0 = self.head_angle_2_output_zero_point_0
quantize_per_tensor_84 = torch.quantize_per_tensor(head_angle_2, head_angle_2_output_scale_0, head_angle_2_output_zero_point_0, torch.qint8); head_angle_2 = head_angle_2_output_scale_0 = head_angle_2_output_zero_point_0 = None
dequantize_81 = quantize_per_tensor_78.dequantize(); quantize_per_tensor_78 = None
dequantize_82 = quantize_per_tensor_80.dequantize(); quantize_per_tensor_80 = None
dequantize_83 = quantize_per_tensor_82.dequantize(); quantize_per_tensor_82 = None
dequantize_84 = quantize_per_tensor_84.dequantize(); quantize_per_tensor_84 = None
return {'hm': dequantize_81, 'wh': dequantize_82, 'reg': dequantize_83, 'angle': dequantize_84}
这个模型的类型是GraphModule,和nn.Module类似,有对应的forward函数。我们可以直接在Pytorch中执行这个模型测试精度,不过需要注意,这里仅仅是测试模拟的量化模型精度,也是测试校准后得到的scale和offset有没有问题,在转化为TensorRT后精度可能会略有差异,毕竟实际推理框架内部实现的一些算子细节我们是不知道的。简单看一眼上述模型的结构图:
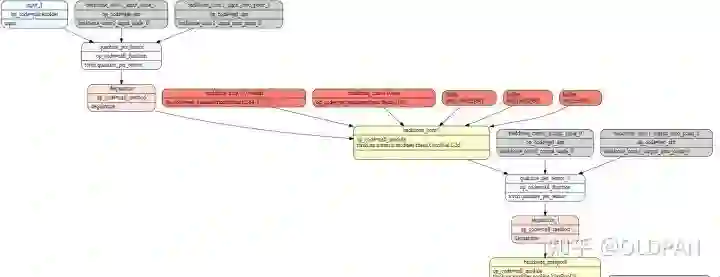
其中,backbone_conv1_input_scale_0和backbone_conv1_input_zero_point_0就是在校准过程中学习到的scale和offset。权重层不需要校准学习,直接就可以算出来(具体细节见上一篇),这里就不赘述了。
这里我对量化后的FX(sim-INT8)和原始的FX模型(FP32)进行了精度的对比,因为Centernet有三个输出:
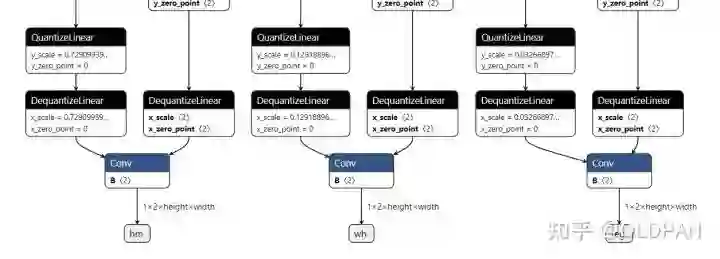
所以我这里对三个输出都进行了简单的精度计算:
original_fx_model.cuda()
res_fp32 = original_fx_model(data)
res_int8 = quantized_fx(data)
for i in range(len(res_fp32)):
print(torch.max(torch.abs(res_fp32[i] - res_int8[i])))
简单粗暴,结果看起来差距有点大,其中wh的最大误差都有26了:
tensor(1.5916, device='cuda:0', grad_fn=<MaxBackward1>)
tensor(26.1865, device='cuda:0', grad_fn=<MaxBackward1>)
tensor(0.1195, device='cuda:0', grad_fn=<MaxBackward1>)
不过如果计算下每个输出的余弦相似度,每个输出的相似度都接近于1:
torch_cosine_similarity: tensor(1.0000)
大家猜猜看,最终的mAP有没有掉点?
acc_tracer
接下来需要acc_tracer来将reference模型转化为acc版本的模型。
Acc Tracer is inherited from FX symbolic tracer Performs tracing and arg normalization specialized for accelerator lowering.
acc的主要作用是将pytorch中reference版本的op转换为相应的acc-op,一共干了这些事儿:
-
首先将要trace的模型所有un-tracable的部分转化为traceable
-
然后干掉所有assertions和exception的wrappers
-
整理模型,去掉dead code
-
对graph中的所有node的args/kwargs做标准化,将部分符合要求的arg移动到kwarg,making default values explicit.
trace前的模型graph:
graph():
%input_1 : [#users=1] = placeholder[target=input]
%backbone_base_base_layer_0_input_scale_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_input_scale_0]
%backbone_base_base_layer_0_input_zero_point_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_input_zero_point_0]
%quantize_per_tensor : [#users=1] = call_function[target=torch.quantize_per_tensor](args = (%input_1, %backbone_base_base_layer_0_input_scale_0, %backbone_base_base_layer_0_input_zero_point_0, torch.qint8), kwargs = {})
%dequantize : [#users=1] = call_method[target=dequantize](args = (%quantize_per_tensor,), kwargs = {})
%backbone_base_base_layer_0_0_weight : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight]
%backbone_base_base_layer_0_0_weight_scale : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight_scale]
%backbone_base_base_layer_0_0_weight_zero_point : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight_zero_point]
%quantize_per_channel : [#users=1] = call_function[target=torch.quantize_per_channel](args = (%backbone_base_base_layer_0_0_weight, %backbone_base_base_layer_0_0_weight_scale, %backbone_base_base_layer_0_0_weight_zero_point, 0, torch.qint8), kwargs = {})
%dequantize_1 : [#users=1] = call_method[target=dequantize](args = (%quantize_per_channel,), kwargs = {})
%backbone_base_base_layer_0_0_bias : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.bias]
%conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%dequantize, %dequantize_1, %backbone_base_base_layer_0_0_bias, (1, 1), (3, 3), (1, 1), 1), kwargs = {})
%relu : [#users=1] = call_function[target=torch.nn.functional.relu](args = (%conv2d,), kwargs = {inplace: True})
%backbone_base_base_layer_0_scale_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_scale_0]
%backbone_base_base_layer_0_zero_point_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_zero_point_0]
%quantize_per_tensor_1 : [#users=1] = call_function[target=torch.quantize_per_tensor](args = (%relu, %backbone_base_base_layer_0_scale_0, %backbone_base_base_layer_0_zero_point_0, torch.qint8), kwargs = {})
...
trace后的模型graph:
graph():
%input_1 : [#users=1] = placeholder[target=input]
%backbone_base_base_layer_0_input_scale_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_input_scale_0]
%backbone_base_base_layer_0_input_zero_point_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_input_zero_point_0]
%quantize_per_tensor_92 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.quantize_per_tensor](args = (), kwargs = {input: %input_1, acc_out_ty: (None, torch.qint8, None, None, None, None, {scale: %backbone_base_base_layer_0_input_scale_0, zero_point: %backbone_base_base_layer_0_input_zero_point_0})})
%dequantize_153 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.dequantize](args = (), kwargs = {input: %quantize_per_tensor_92})
%backbone_base_base_layer_0_0_weight : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight]
%backbone_base_base_layer_0_0_weight_scale : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight_scale]
%backbone_base_base_layer_0_0_weight_zero_point : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.weight_zero_point]
%quantize_per_channel_61 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.quantize_per_channel](args = (), kwargs = {input: %backbone_base_base_layer_0_0_weight, acc_out_ty: (None, torch.qint8, None, None, None, None, {scale: %backbone_base_base_layer_0_0_weight_scale, zero_point: %backbone_base_base_layer_0_0_weight_zero_point, axis: 0})})
%dequantize_154 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.dequantize](args = (), kwargs = {input: %quantize_per_channel_61})
%backbone_base_base_layer_0_0_bias : [#users=1] = get_attr[target=backbone.base.base_layer.0.0.bias]
%conv2d_55 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.conv2d](args = (), kwargs = {input: %dequantize_153, weight: %dequantize_154, bias: %backbone_base_base_layer_0_0_bias, stride: (1, 1), padding: (3, 3), dilation: (1, 1), groups: 1})
%relu_48 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.relu](args = (), kwargs = {input: %conv2d_55, inplace: True})
%backbone_base_base_layer_0_scale_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_scale_0]
%backbone_base_base_layer_0_zero_point_0 : [#users=1] = get_attr[target=backbone_base_base_layer_0_zero_point_0]
%quantize_per_tensor_93 : [#users=1] = call_function[target=torch_tensorrt.fx.tracer.acc_tracer.acc_ops.quantize_per_tensor](args = (), kwargs = {input: %relu_48, acc_out_ty: (None, torch.qint8, None, None, None, None, {scale: %backbone_base_base_layer_0_scale_0, zero_point: %backbone_base_base_layer_0_zero_point_0})})
可以看到原始版本的dequantize转换为了torch_tensorrt.fx.tracer.acc_tracer.acc_ops.dequantize,为什么要这么干呢,有两点原因:
-
将一些相同功能的op( PyTorch ops and builtin ops ),比如 . torch.add, builtin.add and torch.Tensor.add 等等,就可以一并都转化为acc.add -
Move args and kwargs into kwargs only for converting simplicity
acc_op_map的代码主要在:TensorRT/py/torch_tensorrt/fx/tracer/acc_tracer/acc_ops.py 拿一小段代码看看:
@register_acc_op_properties(AccOpProperty.pointwise, AccOpProperty.unary)
@register_acc_op_mapping(op_and_target=("call_function", nn.functional.relu))
@register_acc_op_mapping(
op_and_target=("call_function", torch.relu),
arg_replacement_tuples=[("input", "input")],
)
@register_acc_op_mapping(
op_and_target=("call_method", "relu"),
arg_replacement_tuples=[("input", "input")],
)
@register_acc_op
def relu(*, input, inplace=False):
return nn.functional.relu(input=input, inplace=inplace)
可以看到nn.functional.relu、 torch.relu以及call_method的relu这三种形式,最终都会转化为acc_op.relu。
如果不这样的话,可能需要针对三种情况写三份converter代码,那样就比较麻烦了,代码也会比较冗余。
得到acc版本的model之后,就需要针对acc-op一个一个去转换为trt了。至此,trace的过程就结束了(其实acc_trace的过程细节很多,限于篇幅这里就不说了,之后有机会的话单独介绍下)。
TRTInterpreter
TRTInterpreter继承于torch.fx.Interpreter。
An Interpreter executes an FX graph Node-by-Node. This patterncan be useful for many things, including writing code transformations as well as analysis passes.
关于Interpreter,也在第一篇中介绍过。Interpreter,即解释器,就是以一个比较优雅的方式循环一个Graph的node并且执行它们,并同时顺带完成一些任务。我们可以通过这个实现很多功能,比如替换模型中某个操作,比如模型性能分析等等。而在这里,我们利用TRTInterpreter转换acc_op到trt的op, 首先初始化解释器对象,输入常见的参数,这里我转的是dynamic shape,指定了min、opt和max三个大小,explicit_batch_dimension设为True:
interp = TRTInterpreter(
quantized_fx,
[InputTensorSpec(torch.Size([1,3,-1,-1]), torch.float,
shape_ranges=[((1, 3, 128, 128), (1, 3, 768, 768), (1, 3, 1024, 1024))], has_batch_dim=True)],
explicit_batch_dimension=True, explicit_precision=True,
logger_level=trt.Logger.VERBOSE
)
然后就可以执行了,run的时候传入具体要转换的精度,以及workspace大小:
res = interp.run(lower_precision=LowerPrecision.INT8, strict_type_constraints=True, max_workspace_size=4096000000)
run的时候,对于TRTInterpreter来说,任务就是遍历graph中的node,然后按照注册好的converter一个一个去转换。这里其实比较巧妙,TRTInterpreter继承了torch.fx.Interpreter,重载了其中的这些方法:

而run函数,遍历node的过程是在父类Interpreter中运行:
# torch/fx/interpreter.py
for node in self.module.graph.nodes:
if node in self.env:
# Short circuit if we have this value. This could
# be used, for example, for partial evaluation
# where the caller has pre-populated `env` with
# values for a subset of the program.
continue
try:
self.env[node] = self.run_node(node)
except Exception as e:
msg = f"While executing {node.format_node()}"
msg = '{}\n\n{}'.format(e.args[0], msg) if e.args else str(msg)
msg += f"\nOriginal traceback:\n{node.stack_trace}"
e.args = (msg,) + e.args[1:]
if isinstance(e, KeyError):
raise RuntimeError(*e.args)
raise
if self.garbage_collect_values:
for to_delete in self.user_to_last_uses.get(node, []):
del self.env[to_delete]
if node.op == 'output':
output_val = self.env[node]
return self.module.graph.process_outputs(output_val) if enable_io_processing else output_val
但是run_node因为重载了,所以会调用子类TRTInterpreter中的方法(我们之后也可以通过这种方式实现自己的解释器,去做一些功能),最终会根据不同node的类型,调用不同的node方法,比如call_module、call_function、call_method这仨,表示FX中的三种IR,每个函数中都会调用CONVERTERS来获取转换op:
def call_module(self, target, args, kwargs):
assert isinstance(target, str)
submod = self.fetch_attr(target)
submod_type = getattr(submod, "_base_class_origin", type(submod))
converter = CONVERTERS.get(submod_type)
if not converter:
raise RuntimeError(
f"Conversion of module of type {submod_type} not currently supported!"
)
assert self._cur_node_name is not None
return converter(self.network, submod, args, kwargs, self._cur_node_name)
def call_function(self, target, args, kwargs):
converter = CONVERTERS.get(target)
if not converter:
raise RuntimeError(
f"Conversion of function {torch.typename(target)} not currently supported!"
)
assert self._cur_node_name is not None
return converter(self.network, target, args, kwargs, self._cur_node_name)
def call_method(self, target, args, kwargs):
assert isinstance(target, str)
converter = CONVERTERS.get(target)
if not converter:
raise RuntimeError(
f"Conversion of method {target} not currently supported!"
)
assert self._cur_node_name is not None
return converter(self.network, target, args, kwargs, self._cur_node_name)
转换op的注册代码在TensorRT/py/torch_tensorrt/fx/converters/acc_ops_converters.py中,就拿卷积来说,每一个acc-op对应一个converter,每个converter函数会调用trt的api构建网络:
@tensorrt_converter(acc_ops.conv3d)
@tensorrt_converter(acc_ops.conv2d)
def acc_ops_convnd(
network: TRTNetwork,
target: Target,
args: Tuple[Argument, ...],
kwargs: Dict[str, Argument],
name: str,
) -> Union[TRTTensor, Sequence[TRTTensor]]:
input_val = kwargs["input"]
if not isinstance(input_val, TRTTensor):
raise RuntimeError(
f"Conv received input {input_val} that is not part "
"of the TensorRT region!"
)
if has_dynamic_shape(input_val.shape):
assert input_val.shape[1] != -1, "Channel dim can't be dynamic for convolution."
# for now we'll assume bias is constant Tensor or None,
# and bias being ITensor is not supported in TensorRT api
# right now
if kwargs["bias"] is not None and not isinstance(kwargs["bias"], torch.Tensor):
raise RuntimeError(
f"linear {name} has bias of type {type(kwargs['bias'])}, Expect Optional[Tenosr]"
)
bias = to_numpy(kwargs["bias"]) # type: ignore[arg-type]
if network.has_explicit_precision:
weight = get_trt_tensor(network, kwargs["weight"], f"{name}_weight")
weight_shape = tuple(kwargs["weight"].shape) # type: ignore[union-attr]
# will need to use uninitialized weight and set it later to support
# ITensor weights
dummy_weight = trt.Weights()
layer = network.add_convolution_nd(
input=input_val,
num_output_maps=weight.shape[0],
kernel_shape=weight.shape[2:],
kernel=dummy_weight,
bias=bias,
)
layer.set_input(1, weight)
else:
if not isinstance(kwargs["weight"], torch.Tensor):
raise RuntimeError(
f"linear {name} has weight of type {type(kwargs['weight'])}, Expect Optional[Tenosr]"
)
weight = to_numpy(kwargs["weight"])
layer = network.add_convolution_nd(
input=input_val,
num_output_maps=weight.shape[0],
kernel_shape=weight.shape[2:],
kernel=weight,
bias=bias,
)
set_layer_name(layer, target, name)
layer.stride_nd = kwargs["stride"]
layer.padding_nd = kwargs["padding"]
layer.dilation_nd = kwargs["dilation"]
if kwargs["groups"] is not None:
layer.num_groups = kwargs["groups"]
return layer.get_output(0)
构建好网络之后,设置一些build参数,就可以进行build了。
engine = self.builder.build_engine(self.network, builder_config) build完之后,传入TRTModule,就可以直接调用trt_mod来验证精度了。
engine, input_names, output_names = res.engine, res.input_names, res.output_names
trt_mod = TRTModule(engine, input_names, output_names)
这里我验证了这个模型的精度,一共是两个类别,训练图像4w多,校准用了512张图片,评价的分数阈值是0.1,NMS阈值0.2:量化前指标:
| AP | AP50 | AP60 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 62.745 | 95.430 | 76.175 | 54.004 | 66.575 | 63.692 |
量化后指标:
| AP | AP50 | AP60 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 60.340 | 95.410 | 70.561 | 50.154 | 64.969 | 62.009 |
量化后转化为TensorRT的指标:
| AP | AP50 | AP60 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 60.355 | 95.404 | 70.412 | 50.615 | 64.763 | 61.322 |
嗯,AP降了2个点,但是AP50降得不多,还好还好。再看一下速度,在3080显卡上,一帧需要3.8ms,相比FP16的4.8ms貌似快了一些,但貌似还不够快。
简单跑下trt的隐式量化(implict mode )模式,大概就是先将Centernet模型转化为ONNX,然后再通过使用trtexec强制指定int8(这里不看精度,不传入校准图片,仅仅是为了测试下int8的速度),然后发现速度竟然只需3.1ms。
速度相差了不少,想都不用想可能FX转化为TRT的时候,肯定有些层没有优化到极致。那就对比下两个engine的网络结构图,首先是implict mode下的engine:
[03/07/2022-11:34:20] [I] Conv_101 + Add_103 + Relu_104 16.09 0.0215 0.7
[03/07/2022-11:34:20] [I] Conv_105 + Relu_106 14.89 0.0199 0.6
[03/07/2022-11:34:20] [I] Conv_107 + Relu_108 20.96 0.0280 0.9
[03/07/2022-11:34:20] [I] Conv_109 + Add_110 + Relu_111 15.18 0.0203 0.6
[03/07/2022-11:34:20] [I] Conv_112 + Relu_113 14.31 0.0191 0.6
[03/07/2022-11:34:20] [I] Conv_114 + Relu_115 20.82 0.0278 0.9
[03/07/2022-11:34:20] [I] Conv_116 + Add_117 + Relu_118 15.16 0.0202 0.6
[03/07/2022-11:34:20] [I] Conv_119 40.61 0.0542 1.7
[03/07/2022-11:34:20] [I] ConvTranspose_120 + BatchNormalization_121 + Relu_122 31.20 0.0416 1.3
[03/07/2022-11:34:20] [I] ConvTranspose_123 + BatchNormalization_124 + Relu_125 110.56 0.1476 4.7
[03/07/2022-11:34:20] [I] ConvTranspose_126 + BatchNormalization_127 + Relu_128 509.55 0.6803 21.7
[03/07/2022-11:34:20] [I] Conv_129 + Relu_130 || Conv_132 + Relu_133 || Conv_135 + Relu_136 197.13 0.2632 8.4
[03/07/2022-11:34:20] [I] Reformatting CopyNode for Input Tensor 0 to Conv_131 13.22 0.0177 0.6
[03/07/2022-11:34:20] [I] Conv_131 12.35 0.0165 0.5
[03/07/2022-11:34:20] [I] Reformatting CopyNode for Input Tensor 0 to Conv_134 13.12 0.0175 0.6
[03/07/2022-11:34:20] [I] Conv_134 12.14 0.0162 0.5
[03/07/2022-11:34:20] [I] Reformatting CopyNode for Input Tensor 0 to Conv_137 13.07 0.0175 0.6
[03/07/2022-11:34:20] [I] Conv_137 11.99 0.0160 0.5
[03/07/2022-11:34:20] [I] Total 2352.92 3.1414 100.0
可以看到该融合的都融合了,尤其是 Conv_116 + Add_117 + Relu_118以及ConvTranspose_120 + BatchNormalization_121 + Relu_122和Conv_129 + Relu_130 || Conv_132 + Relu_133 || Conv_135 + Relu_136,都是提速很大的融合,下图是通过trt-engine生成时候产出的log画的图:
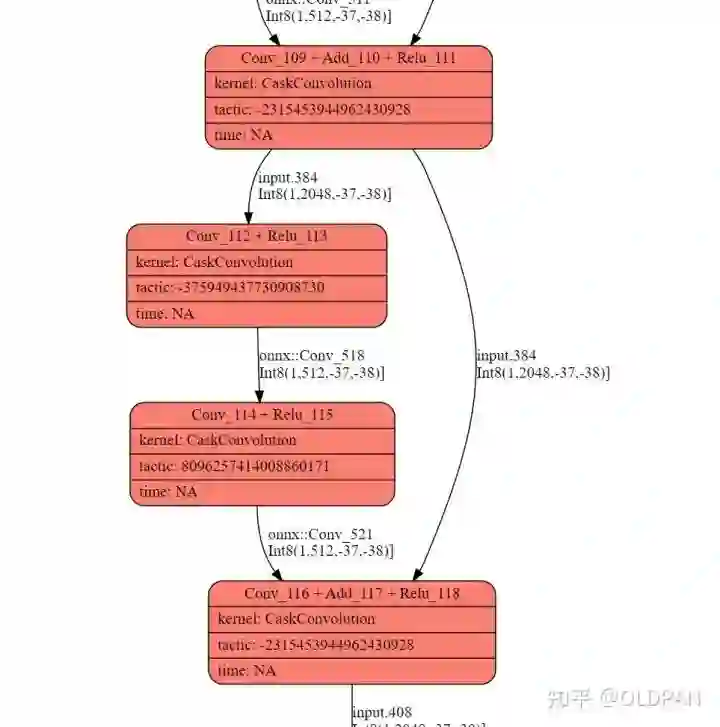
再看下刚才经过FX转换成TRT模型的网络结构:
[03/03/2022-14:46:31] [I] add_29 + relu_97 8.90 0.0137 0.4
[03/03/2022-14:46:31] [I] quantize_per_channel_110_input + (Unnamed Layer* 592) [Constant]_output_per_channel_quant + conv2d_107 + relu_98 12.88 0.0199 0.5
[03/03/2022-14:46:31] [I] quantize_per_channel_111_input + (Unnamed Layer* 603) [Constant]_output_per_channel_quant + conv2d_108 + relu_99 19.11 0.0295 0.8
[03/03/2022-14:46:31] [I] quantize_per_channel_112_input + (Unnamed Layer* 614) [Constant]_output_per_channel_quant + conv2d_109 12.09 0.0187 0.5
[03/03/2022-14:46:31] [I] add_30 + relu_100 8.84 0.0136 0.4
[03/03/2022-14:46:31] [I] quantize_per_channel_113_input + (Unnamed Layer* 630) [Constant]_output_per_channel_quant + conv2d_110 + relu_101 12.61 0.0195 0.5
[03/03/2022-14:46:31] [I] quantize_per_channel_114_input + (Unnamed Layer* 641) [Constant]_output_per_channel_quant + conv2d_111 + relu_102 18.68 0.0288 0.8
[03/03/2022-14:46:31] [I] quantize_per_channel_115_input + (Unnamed Layer* 652) [Constant]_output_per_channel_quant + conv2d_112 12.11 0.0187 0.5
[03/03/2022-14:46:31] [I] add_31 + relu_103 8.84 0.0136 0.4
[03/03/2022-14:46:31] [I] quantize_per_channel_116_input + (Unnamed Layer* 668) [Constant]_output_per_channel_quant + conv2d_113 37.40 0.0577 1.5
[03/03/2022-14:46:31] [I] quantize_per_channel_117_input + (Unnamed Layer* 678) [Constant]_output_per_channel_quant + conv_transpose2d_3 30.68 0.0474 1.2
[03/03/2022-14:46:31] [I] PWN(relu_104) 4.73 0.0073 0.2
[03/03/2022-14:46:31] [I] quantize_per_channel_118_input + (Unnamed Layer* 693) [Constant]_output_per_channel_quant + conv_transpose2d_4 102.36 0.1580 4.2
[03/03/2022-14:46:31] [I] PWN(relu_105) 10.18 0.0157 0.4
[03/03/2022-14:46:31] [I] quantize_per_channel_119_input + (Unnamed Layer* 708) [Constant]_output_per_channel_quant + conv_transpose2d_5 447.84 0.6911 18.2
[03/03/2022-14:46:31] [I] PWN(relu_106) 34.68 0.0535 1.4
[03/03/2022-14:46:31] [I] quantize_per_channel_120_input + (Unnamed Layer* 723) [Constant]_output_per_channel_quant + conv2d_114 + relu_107 65.06 0.1004 2.6
[03/03/2022-14:46:31] [I] quantize_per_channel_122_input + (Unnamed Layer* 742) [Constant]_output_per_channel_quant + conv2d_116 + relu_108 64.46 0.0995 2.6
[03/03/2022-14:46:31] [I] quantize_per_channel_124_input + (Unnamed Layer* 761) [Constant]_output_per_channel_quant + conv2d_118 + relu_109 64.35 0.0993 2.6
[03/03/2022-14:46:31] [I] quantize_per_channel_121_input + (Unnamed Layer* 734) [Constant]_output_per_channel_quant + conv2d_115 11.23 0.0173 0.5
[03/03/2022-14:46:31] [I] quantize_per_channel_123_input + (Unnamed Layer* 753) [Constant]_output_per_channel_quant + conv2d_117 11.16 0.0172 0.5
[03/03/2022-14:46:31] [I] quantize_per_channel_125_input + (Unnamed Layer* 772) [Constant]_output_per_channel_quant + conv2d_119 11.20 0.0173 0.5
[03/03/2022-14:46:31] [I] Reformatting CopyNode for Input Tensor 0 to (Unnamed Layer* 741) [Quantize]_output_.dequant 6.92 0.0107 0.3
[03/03/2022-14:46:31] [I] (Unnamed Layer* 741) [Quantize]_output_.dequant 4.45 0.0069 0.2
[03/03/2022-14:46:31] [I] Reformatting CopyNode for Input Tensor 0 to (Unnamed Layer* 760) [Quantize]_output_.dequant 6.34 0.0098 0.3
[03/03/2022-14:46:31] [I] (Unnamed Layer* 760) [Quantize]_output_.dequant 4.56 0.0070 0.2
[03/03/2022-14:46:31] [I] Reformatting CopyNode for Input Tensor 0 to (Unnamed Layer* 779) [Quantize]_output_.dequant 6.00 0.0093 0.2
[03/03/2022-14:46:31] [I] (Unnamed Layer* 779) [Quantize]_output_.dequant 4.35 0.0067 0.2
[03/03/2022-14:46:31] [I] Total 2464.87 3.8038 100.0
可以发现没有Conv_116 + Add_117 + Relu_118以及后续的ConvTranspose_120 + BatchNormalization_121 + Relu_122和Conv_129 + Relu_130 || Conv_132 + Relu_133 || Conv_135 + Relu_136优化,这部分多消耗了0.6ms的时间:
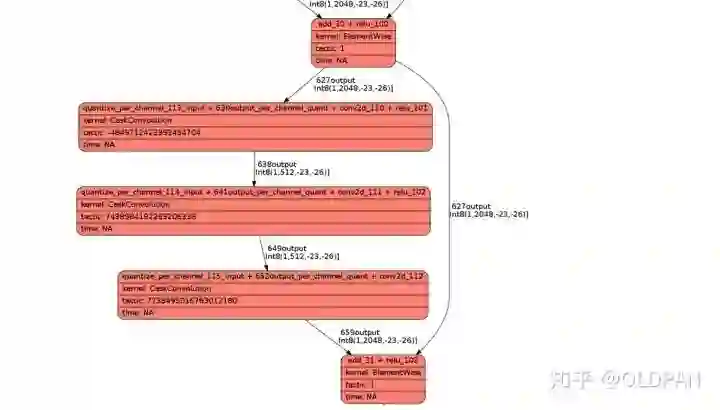
为什么会这样呢,仔细观察了下FX的模型结构,发现这里多了一个Q、DQ的操作,对于TensorRT来说,不恰当位置的QDQ会导致TensorRT在量化的时候优化不彻底。我之前有一篇文章详细介绍,感兴趣的可以看看。
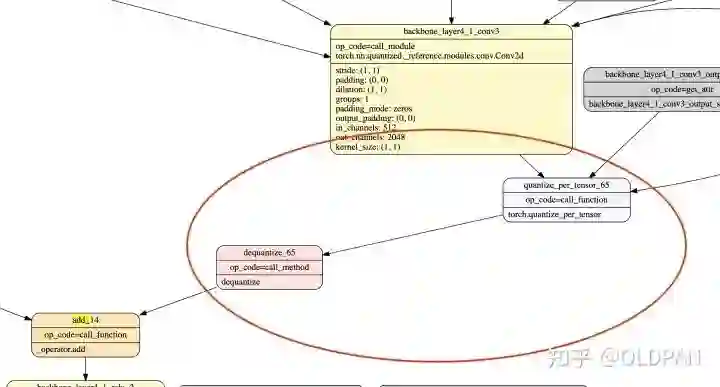
所以理想的应该是这种的,BN层紧接着Add,中间米有QDQ操作,这样TRT会把conv+bn+add以及后续的relu直接融合成Conv_116 + Add_117 + Relu_118:
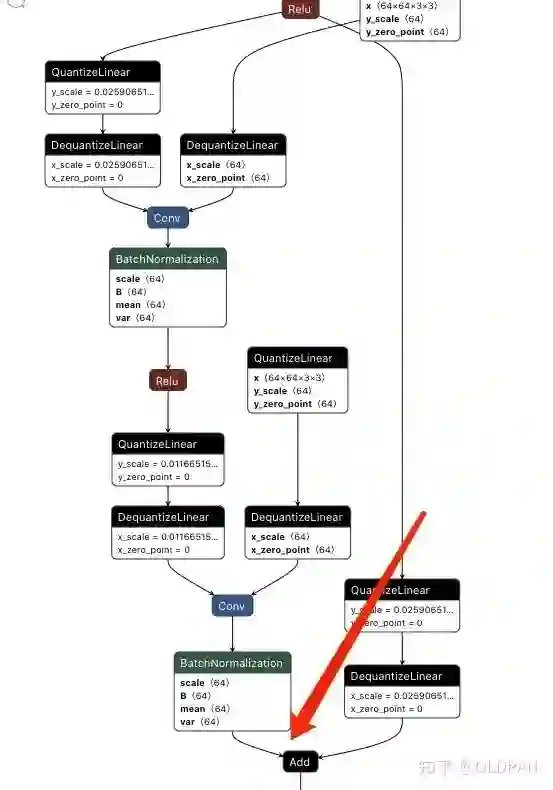
另外还有一点,旧版的FX在fuse的时候(第二篇有说),反卷积后续的BN层融合,这个也会对后续的量化造成一些干扰,导致优化不彻底,把这些都解决后TRT就可以正常优化了。
如何批量将多的QDQ操作干掉呢,这个利用刚才介绍的interpreter就OK了,在propagate的时候,将add节点的args直接修改为正确的节点即可,一共17个,批量修改即可:
def propagate(self, *args):
args_iter = iter(args)
env : Dict[str, Node] = {}
def load_arg(a):
return fx.graph.map_arg(a, lambda n: env[n.name])
def fetch_attr(target : str):
target_atoms = target.split('.')
attr_itr = self.mod
for i, atom in enumerate(target_atoms):
if not hasattr(attr_itr, atom):
raise RuntimeError(f"Node referenced nonexistant target {'.'.join(target_atoms[:i])}")
attr_itr = getattr(attr_itr, atom)
return attr_itr
for node in self.graph.nodes:
# 这里修改
if "add" in node.name:
node.args = (self.change_list[node.name], node.args[1])
# 修改完之后,需要将置空的节点删除
self.mod.graph.eliminate_dead_code()
# 更新graph
self.mod.recompile()
return
这样就OK了,修改后的add与上一个conv层(这里BN被conv吸进去了)之间就没有QDQ的操作:
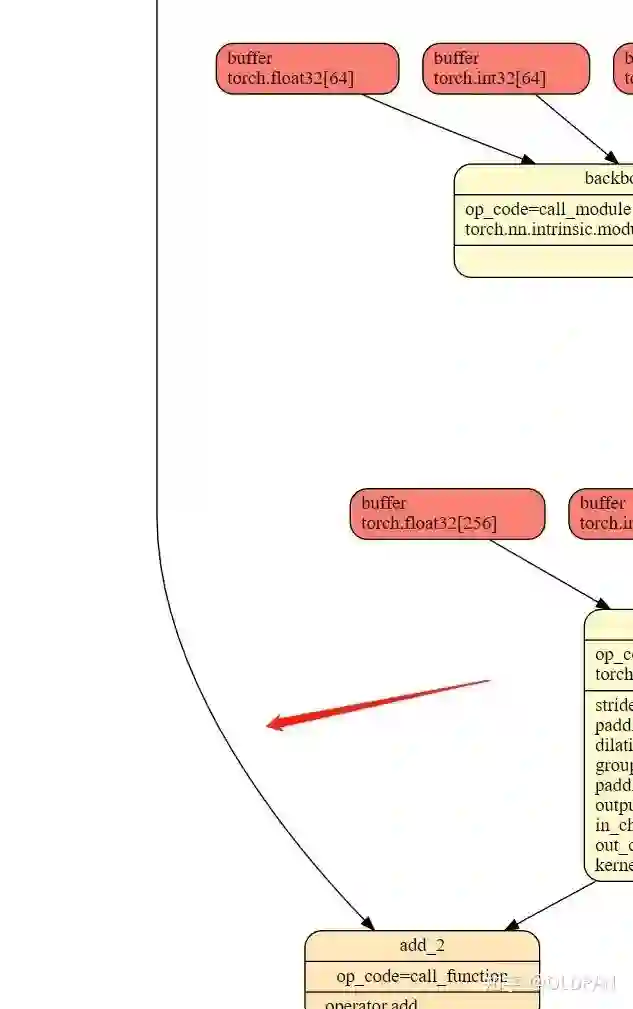
同样,反卷积也和BN层合并了:
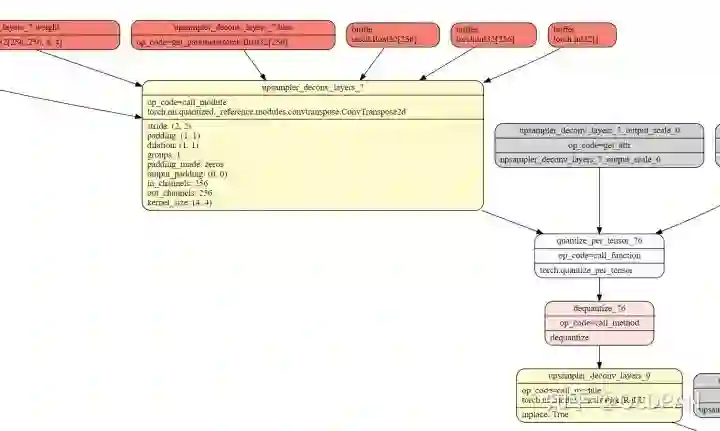
将修改后的fx模型,再一次经过TensorRT的转换,再一次benchmark一下:
# 修改网络之前的
=== Performance summary ===
Throughput: 260.926 qps
Latency: min = 4.91473 ms, max = 5.23787 ms, mean = 4.97783 ms, median = 4.97583 ms, percentile(99%) = 5.22012 ms
End-to-End Host Latency: min = 4.98529 ms, max = 8.08485 ms, mean = 7.56827 ms, median = 7.58014 ms, percentile(99%) = 8.06438 ms
Enqueue Time: min = 0.375031 ms, max = 0.717957 ms, mean = 0.394493 ms, median = 0.391724 ms, percentile(99%) = 0.470032 ms
H2D Latency: min = 1.03088 ms, max = 1.09827 ms, mean = 1.03257 ms, median = 1.03235 ms, percentile(99%) = 1.03613 ms
GPU Compute Time: min = 3.75397 ms, max = 4.07245 ms, mean = 3.81574 ms, median = 3.81421 ms, percentile(99%) = 4.05913 ms
D2H Latency: min = 0.125977 ms, max = 0.153076 ms, mean = 0.129512 ms, median = 0.129333 ms, percentile(99%) = 0.131836 ms
Total Host Walltime: 3.01235 s
Total GPU Compute Time: 2.99917 s
Explanations of the performance metrics are printed in the verbose logs.
# 修改网络之后
=== Performance summary ===
Throughput: 305.313 qps
Latency: min = 4.35956 ms, max = 4.64665 ms, mean = 4.41392 ms, median = 4.40918 ms, percentile(99%) = 4.62846 ms
End-to-End Host Latency: min = 4.401 ms, max = 6.90311 ms, mean = 6.43806 ms, median = 6.43774 ms, percentile(99%) = 6.88329 ms
Enqueue Time: min = 0.320801 ms, max = 0.559082 ms, mean = 0.334164 ms, median = 0.330078 ms, percentile(99%) = 0.486328 ms
H2D Latency: min = 1.03186 ms, max = 1.03824 ms, mean = 1.03327 ms, median = 1.0332 ms, percentile(99%) = 1.03638 ms
GPU Compute Time: min = 3.20001 ms, max = 3.48364 ms, mean = 3.25109 ms, median = 3.24609 ms, percentile(99%) = 3.46623 ms
D2H Latency: min = 0.126404 ms, max = 0.13208 ms, mean = 0.129566 ms, median = 0.129395 ms, percentile(99%) = 0.13147 ms
Total Host Walltime: 3.01003 s
Total GPU Compute Time: 2.98775 s
Explanations of the performance metrics are printed in the verbose logs.
发现速度从3.8ms->3.2ms了,提升了0.6ms,QPS也提升了15%,当然精度没有变化,此时TensorRT的log显示该融合的都正确融合了。
不过我好奇的是,现在3.2ms,比上述implict mode下的直接通过trtexec量化的engine的3.1ms,还慢0.1ms。于是我尝试使用trtexec,加入校准数据去量化这个模型,发现速度又变为3.2ms了,目前尚不清楚原因,如果有知道的小伙伴欢迎留言。
到目前为止,我们成功使用FX后训练量化了一个模型,并且转化为了TensorRT,精度和速度也比较符合预期!
需要符合TensorRT搭建network的形式
如果遇到模型出来的节点不对、有腾空的节点(即节点输出不是任一层的输入也不是模型的输出)、有错误引用的结点(结点获取某些属性是不存在的,例如backbone_base_fc_bias = self.backbone.base.fc.bias,其中fc是一个ConvRelu2D的)。这个时候TRT构建的时候会报错:Error Code 4: Internal Error ([DECONVOLUTION]-[acc_ops.conv_transpose2d]-[conv_transpose2d_3]: Missing Dequantization layer \- 2nd input to a weighted-layer must include exactly one DQ layer.)。当然也有可能是TensorRT的bug,修改节点的FX网络,在TensorRT-8.2版本以上就没问题,但是TensorRT-8.0.1.6下,就会构建出匪夷所思的模型(下面显示的模型结构,INT8和FP32的节点错乱):
Layer(CaskConvolution): quantize_per_channel_106_input + 492output_per_channel_quant + conv2d_103 + relu_95, Tactic: 805889586762897346, 489output[Int8(1,1024,-26,-29)] -> 500output[Int8(1,512,-26,-29)]
Layer(CaskConvolution): quantize_per_channel_109_input + 520output_per_channel_quant + conv2d_106, Tactic: 7738495016763012180, 489output[Int8(1,1024,-26,-29)] -> 527output[Int8(1,2048,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_107_input + 503output_per_channel_quant + conv2d_104 + relu_96, Tactic: 6781129591847482048, 500output[Int8(1,512,-26,-29)] -> 511output[Int8(1,512,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_108_input + 514output_per_channel_quant + conv2d_105 + add_29 + relu_97, Tactic: 8234775147403903473, 511output[Int8(1,512,-50,-51)], 527output[Int8(1,2048,-50,-51)] -> 533output[Int8(1,2048,-50,-51)]
Layer(CudnnConvolution): quantize_per_channel_110_input + 536output_per_channel_quant + 538output_.dequant + conv2d_107 + relu_98, Tactic: 1, 535output[Float(1,2048,-50,-51)] -> 542Activation]_output[Float(1,512,-50,-51)]
Layer(Scale): 542Activation]_output_per_tensor_quant, Tactic: 0, 542Activation]_output[Float(1,512,-50,-51)] -> 544output[Int8(1,512,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_111_input + 547output_per_channel_quant + conv2d_108 + relu_99, Tactic: 7438984192263206338, 544output[Int8(1,512,-50,-51)] -> 555output[Int8(1,512,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_112_input + 558output_per_channel_quant + conv2d_109 + add_30 + relu_100, Tactic: 8234775147403903473, 555output[Int8(1,512,-50,-51)], 533output[Int8(1,2048,-50,-51)] -> 567output[Int8(1,2048,-50,-51)]
Layer(CudnnConvolution): quantize_per_channel_113_input + 570output_per_channel_quant + 572output_.dequant + conv2d_110 + relu_101, Tactic: 1, 569output[Float(1,2048,-50,-51)] -> 576Activation]_output[Float(1,512,-50,-51)]
Layer(Scale): 576Activation]_output_per_tensor_quant, Tactic: 0, 576Activation]_output[Float(1,512,-50,-51)] -> 578output[Int8(1,512,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_114_input + 581output_per_channel_quant + conv2d_111 + relu_102, Tactic: 7438984192263206338, 578output[Int8(1,512,-50,-51)] -> 589output[Int8(1,512,-50,-51)]
Layer(CaskConvolution): quantize_per_channel_115_input + 592output_per_channel_quant + conv2d_112 + add_31 + relu_103, Tactic: 8234775147403903473, 589output[Int8(1,512,-50,-51)], 567output[Int8(1,2048,-50,-51)] -> 601output[Int8(1,2048,-50,-51)]
engine是能构建出来,但是速度很慢,精度全无,对于我们的debug更造成了一些困扰和难度。
FX2TRT的另一种方式
TensorRT有显式量化(explicit mod)和隐式量化(implict mode )两种方式,我们刚才用的是显式量化,即利用QDQ显式声明需要量化的节点,我们也可以用过隐式量化走FX去转TensorRT,这个时候就不能转reference版本的模型,不是模拟量化,而是实际算子就是INT8的模型,quantized_fx = convert_fx(model.fx_model)。
Pytorch有CPU端的INT8操作,实际中模型调用的是torch.nn.quantized.modules.conv.Conv2d算子,在转trt的时候,会调用以下的转换代码:
@tensorrt_converter(torch.nn.quantized.modules.conv.Conv2d)
def quantized_conv2d(network, submod, args, kwargs, layer_name):
input_val = args[0]
if not isinstance(input_val, trt.tensorrt.ITensor):
raise RuntimeError(
f"Quantized Conv2d received input {input_val} that is not part "
"of the TensorRT region!"
)
return common_conv(
network,
submod,
dimension=2,
input_val=input_val,
layer_name=layer_name,
is_quantized=True,
)
过程中我们会传入每一层激活值的scale和zero_point,但是weight还是由tensorrt内部进行校准的:
if is_quantized:
# Assume the dtype of activation is torch.quint8
mark_as_int8_layer(
layer, get_dyn_range(mod.scale, mod.zero_point, torch.quint8)
)
这里就不演示了,写不动了。
提一嘴TRTModule类
FX2TRT中,最终构造出来的engine是由这个类进行管理,这个类对engine进行了封装,我们在调用该类对象的时候,就和调用普通nn.module一样,非常方便。
可以通过代码看下TRTModule的细节,值得看。
# torch_tensorrt/fx/trt_module.py
class TRTModule(torch.nn.Module):
def __init__(
self, engine=None, input_names=None, output_names=None, cuda_graph_batch_size=-1
):
super(TRTModule, self).__init__()
self._register_state_dict_hook(TRTModule._on_state_dict)
self.engine = engine
self.input_names = input_names
self.output_names = output_names
self.cuda_graph_batch_size = cuda_graph_batch_size
self.initialized = False
if engine:
self._initialize()
def _initialize(self):
self.initialized = True
self.context = self.engine.create_execution_context()
# Indices of inputs/outputs in the trt engine bindings, in the order
# as they are in the original PyTorch model.
self.input_binding_indices_in_order: Sequence[int] = [
self.engine.get_binding_index(name) for name in self.input_names
]
self.output_binding_indices_in_order: Sequence[int] = [
self.engine.get_binding_index(name) for name in self.output_names
]
primary_input_outputs = set()
primary_input_outputs.update(self.input_binding_indices_in_order)
primary_input_outputs.update(self.output_binding_indices_in_order)
self.hidden_output_binding_indices_in_order: Sequence[int] = []
self.hidden_output_names: Sequence[str] = []
for i in range(
self.engine.num_bindings // self.engine.num_optimization_profiles
):
if i not in primary_input_outputs:
self.hidden_output_binding_indices_in_order.append(i)
self.hidden_output_names.append(self.engine.get_binding_name(i))
assert (self.engine.num_bindings // self.engine.num_optimization_profiles) == (
len(self.input_names)
+ len(self.output_names)
+ len(self.hidden_output_names)
)
self.input_dtypes: Sequence[torch.dtype] = [
torch_dtype_from_trt(self.engine.get_binding_dtype(idx))
for idx in self.input_binding_indices_in_order
]
self.input_shapes: Sequence[Sequence[int]] = [
tuple(self.engine.get_binding_shape(idx))
for idx in self.input_binding_indices_in_order
]
self.output_dtypes: Sequence[torch.dtype] = [
torch_dtype_from_trt(self.engine.get_binding_dtype(idx))
for idx in self.output_binding_indices_in_order
]
self.output_shapes = [
tuple(self.engine.get_binding_shape(idx))
if self.engine.has_implicit_batch_dimension
else tuple()
for idx in self.output_binding_indices_in_order
]
self.hidden_output_dtypes: Sequence[torch.dtype] = [
torch_dtype_from_trt(self.engine.get_binding_dtype(idx))
for idx in self.hidden_output_binding_indices_in_order
]
self.hidden_output_shapes = [
tuple(self.engine.get_binding_shape(idx))
if self.engine.has_implicit_batch_dimension
else tuple()
for idx in self.hidden_output_binding_indices_in_order
]
def _check_initialized(self):
if not self.initialized:
raise RuntimeError("TRTModule is not initialized.")
def _on_state_dict(self, state_dict, prefix, local_metadata):
self._check_initialized()
state_dict[prefix + "engine"] = bytearray(self.engine.serialize())
state_dict[prefix + "input_names"] = self.input_names
state_dict[prefix + "output_names"] = self.output_names
state_dict[prefix + "cuda_graph_batch_size"] = self.cuda_graph_batch_size
def _load_from_state_dict(
self,
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
):
engine_bytes = state_dict[prefix + "engine"]
logger = trt.Logger()
runtime = trt.Runtime(logger)
self.engine = runtime.deserialize_cuda_engine(engine_bytes)
self.input_names = state_dict[prefix + "input_names"]
self.output_names = state_dict[prefix + "output_names"]
self._initialize()
def __getstate__(self):
state = self.__dict__.copy()
state["engine"] = bytearray(self.engine.serialize())
state.pop("context", None)
return state
def __setstate__(self, state):
logger = trt.Logger()
runtime = trt.Runtime(logger)
state["engine"] = runtime.deserialize_cuda_engine(state["engine"])
self.__dict__.update(state)
if self.engine:
self.context = self.engine.create_execution_context()
def forward(self, *inputs):
with torch.autograd.profiler.record_function("TRTModule:Forward"):
self._check_initialized()
with torch.autograd.profiler.record_function("TRTModule:ProcessInputs"):
assert len(inputs) == len(
self.input_names
), f"Wrong number of inputs, expect {len(self.input_names)} get {len(inputs)}."
# This is only used when the trt engine is using implicit batch dim.
batch_size = inputs[0].shape[0]
contiguous_inputs: List[torch.Tensor] = [i.contiguous() for i in inputs]
bindings: List[Any] = [None] * (
len(self.input_names)
+ len(self.output_names)
+ len(self.hidden_output_names)
)
for i, input_name in enumerate(self.input_names):
assert inputs[
i
].is_cuda, f"{i}th input({input_name}) is not on cuda device."
assert (
inputs[i].dtype == self.input_dtypes[i]
), f"Dtype mismatch for {i}th input({input_name}). Expect {self.input_dtypes[i]}, got {inputs[i].dtype}."
idx = self.input_binding_indices_in_order[i]
bindings[idx] = contiguous_inputs[i].data_ptr()
if not self.engine.has_implicit_batch_dimension:
self.context.set_binding_shape(
idx, tuple(contiguous_inputs[i].shape)
)
else:
assert inputs[i].size()[1:] == self.input_shapes[i], (
f"Shape mismatch for {i}th input({input_name}). "
f"Expect {self.input_shapes[i]}, got {inputs[i].size()[1:]}."
)
with torch.autograd.profiler.record_function("TRTModule:ProcessOutputs"):
# create output tensors
outputs: List[torch.Tensor] = []
for i, idx in enumerate(self.output_binding_indices_in_order):
if self.engine.has_implicit_batch_dimension:
shape = (batch_size,) + self.output_shapes[i]
else:
shape = tuple(self.context.get_binding_shape(idx))
output = torch.empty( # type: ignore[call-overload]
size=shape,
dtype=self.output_dtypes[i],
device=torch.cuda.current_device(),
)
outputs.append(output)
bindings[idx] = output.data_ptr()
for i, idx in enumerate(self.hidden_output_binding_indices_in_order):
if self.engine.has_implicit_batch_dimension:
shape = (batch_size,) + self.hidden_output_shapes[i]
else:
shape = tuple(self.context.get_binding_shape(idx))
output = torch.empty( # type: ignore[call-overload]
size=shape,
dtype=self.hidden_output_dtypes[i],
device=torch.cuda.current_device(),
)
bindings[idx] = output.data_ptr()
with torch.autograd.profiler.record_function("TRTModule:TensorRTRuntime"):
if self.engine.has_implicit_batch_dimension:
self.context.execute_async(
batch_size, bindings, torch.cuda.current_stream().cuda_stream
)
else:
self.context.execute_async_v2(
bindings, torch.cuda.current_stream().cuda_stream
)
if len(outputs) == 1:
return outputs[0]
return tuple(outputs)
def enable_profiling(self, profiler: "trt.IProfiler" = None):
"""
Enable TensorRT profiling. After calling this function, TensorRT will report
time spent on each layer in stdout for each forward run.
"""
self._check_initialized()
if not self.context.profiler:
self.context.profiler = trt.Profiler() if profiler is None else profiler
def disable_profiling(self):
"""
Disable TensorRT profiling.
"""
self._check_initialized()
torch.cuda.synchronize()
del self.context
self.context = self.engine.create_execution_context()
def get_layer_info(self) -> str:
"""
Get layer info of the engine. Only support for TRT > 8.2.
"""
inspector = self.engine.create_engine_inspector()
return inspector.get_engine_information(trt.LayerInformationFormat.JSON)
TRTModule我见过最开始出现在torch2trt,也是一个Pytorch的转换TensorRT工具,同样非常好用。
后记
总算是把坑补了点,拖延症晚期啊。
接下来会写一些FX的文章,内容随意了。另外也会写QAT的文章,以及torch_tensorrt的文章,大家记得关注哦。
公众号后台回复“画图模板”获取90+深度学习画图模板~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
极市&深大CV技术交流群已创建,欢迎深大校友加入,在群内自由交流学术心得,分享学术讯息,共建良好的技术交流氛围。
“
点击阅读原文进入CV社区
收获更多技术干货

