
陈天奇是机器学习领域著名的青年华人学者之一,本科毕业于上海交通大学ACM班,博士毕业于华盛顿大学计算机系,研究方向为大规模机器学习。在本文中,陈天奇回答了目前深度学习编译技术的瓶颈在哪里,下一代技术是什么?
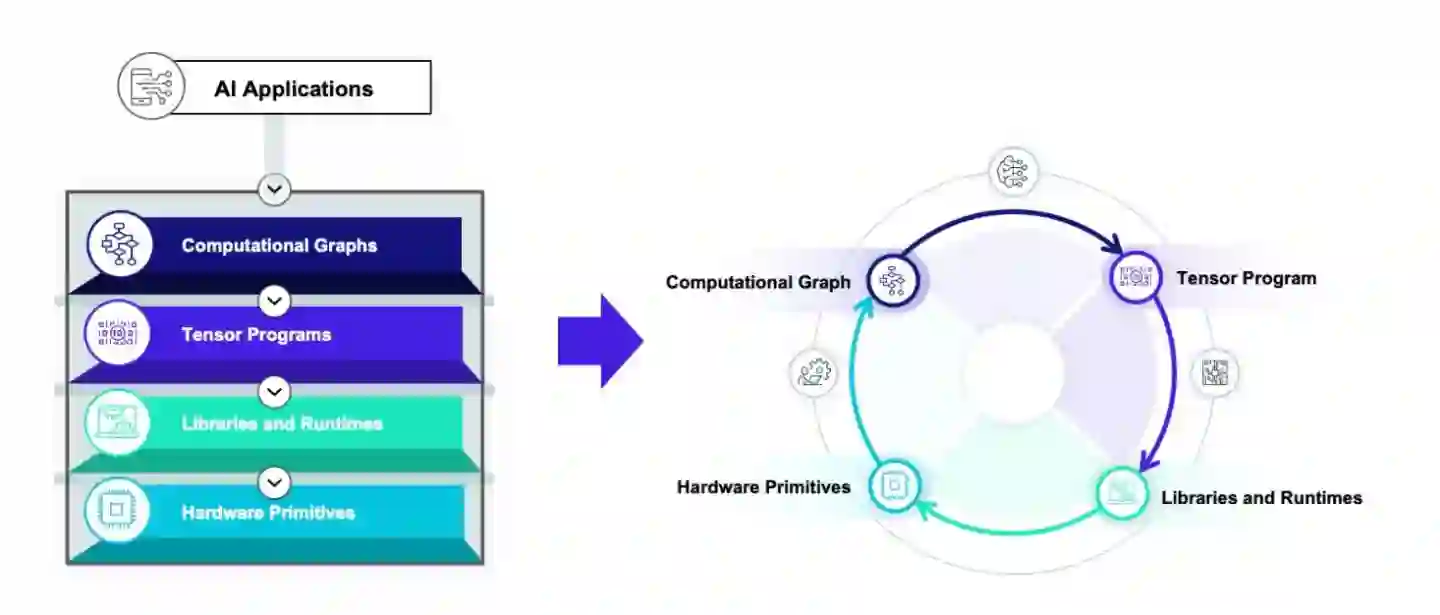
2021年12月16日,第四次TVMCon如期在线举行。从大约四年多前行业的起点开始,深度学习编译技术也从初期萌芽阶段到了现在行业广泛参与的状况。我们也看到了许多关于编译和优化技术有趣的讨论。深度学习编译技术生态的蓬勃发展也使得我们有了许多新的思考。TVM作为最早打通的深度学习编译技术框架已经可以给大家提供不少价值。但是就好像深度学习框架本身会经历从从第一代(caffe)到下两代(TF, pytorch)的变化一样,我们非常清楚深度学习编译技术本身也需要经历几代的演化。因此从两年前开始我们就开始问这样一个问题:“目前深度学习编译技术的瓶颈在哪里,下一代技术是什么“。 比较幸运的是,作为最早打通编译流程的架构我们可以比较早地直接观察到只有尝试整合才可以看到的经验。而目前开始繁荣的生态本身 (MLIR的各种dialects,XLA, ONNX, TorchScript) 也开始给我们不少可以学习参考的目标。本文是对过去两年全面深度学习编译和硬件加速生态的总结思考,也是我们对于深度学习新一代编译技术的技术展望,希望对大家有一些参考价值。本文的内容大部分来自于今年我们在TVMCon的主题报告。
成为VIP会员查看完整内容
相关内容
Arxiv
6+阅读 · 2019年9月27日
Arxiv
16+阅读 · 2018年1月31日

相关VIP内容
相关资讯