赛尔原创 | ACL 2018 基于强化学习的中文零指代消解模型
作者:哈工大SCIR博士生 尹庆宇
1 前言
中文的零指代,作为指代现象中的一种,能够更好地帮助机器理解自然语言。随着计算机技术和互联网的迅速发展,社会的信息化程度已经发展到一个全新的阶段,信息的传递与交流已成为现代社会生活运作的重要基础,各种信息呈爆炸式增长。人们在享受海量信息提供便利的同时,也面临着如何从浩如烟海的信息中找到自己所需内容的困境。一些集成了自然语言处理成果的技术,如信息检索(Information Retrieval)、信息抽取(Information Extraction)、问答(Question Answering)、自动文摘(Automatic Summarization)和机器翻译(Machine Translation)等系统,能够帮助用户更为方便快捷准确地获得自己所需的内容。在这些系统中,自然语言都扮演着很重要的角色。比如在问答系统中,用户的问题都是通过自然语言的形式提出的,而如何能够让机器正确有效地理解这些问题就成了重中之重。
2 任务简介
指代消解是信息抽取不可或缺的组成部分。在信息抽取中,由于用户关心的事件和实体间语义关系往往散布于文本的不同位置,其中涉及到的实体通常可以有多种不同的表达方式,例如某个语义关系中的实体可能是以代词形式出现的,为了更准确且没有遗漏地从文本中抽取相关信息,必须要对文章中的指代现象进行消解。指代消解不但在信息抽取中起着重要的作用,而且在机器翻译、文本摘要和问答系统等应用中也极为关键。
中文的零指代是指代现象中的一种,是指代现象中的一种特殊情况。它是指在篇章中,读者能够根据上下文的关系推断出来的部分经常被省略,被省略的部分在句子中又承担相应的句法成分,并且回指前文中的某个语言单位。被省略掉的部分称为零指代项或者零代词,被指向的语言单位被称为先行语。图1是一个中文零指代现象的示例。在这里,"φ"表示一个零代词,它的先行语为"苹果''。

图1 中文零指代示例
3 我们的方法
3.1 动机
现有的中文零指代消解系统中,都是把零指代消解问题视作一个分类问题。即每次都拿出一个候选先行语和一个零代词进行分类。这种方法每次只会从局部中选取最优的解。也就是说,用这种单分类的方法构建的零指代消解系统不能有效利用之前的候选先行语分类提供的信息,而之类信息是很重要的,我们需要设计一种模型能够很好的利用之前判断出的候选先行语信息来帮助对后续的候选先行语进行分类。因此,我们把分类的模型用一种序列化的决策的方式来进行分类,把所有的候选先行语视为一个序列,在判断序列后放的候选词的时候能够把之前的序列候选词信息考虑进去。这种序列决策的方法能够利用深度强化学习的方法来实现。综上,我们设计了一种基于强化学习的中文零指代消解系统,旨在解决传统的单分类中文零指代系统中不能很好利用全局信息的缺点。
3.2 方法设计
传统的零指代方法主要分为两个步骤:零代词的可消解性识别和零代词的消解。在这篇文章中,同已有的方法啊类似(Chen and Ng, 2016; Yin et al., 2017a; Yin et al., 2017b),我们主要关注第二个子任务,即零代词的消解。图2是本方法的整体流程图。对于一个给定的零代词,我们首先选取它所有的候选先行词,并将其映射成序列,从左到右依次与零代词进行分类。如果一个零代词和候选先行语被分为了可消解类别,那么我们就将这个零代词的信息保存起来,供后边的零代词消解使用。如果没有被选中,则将其舍去。在这个过程中,我们利用了基于策略梯度的深度强化学习算法进行零代词的选择。每一时刻,我们的状态定义为输入的零代词和对应时刻的候选先行语以及之前判断出的所有先行语,动作定义为选中和未选中两个动作--选中代表零代词和候选先行语可以消解。这样,我们就可以利用强化学习的方法进行零代词的消解工作。下边来详细介绍强化学习模型
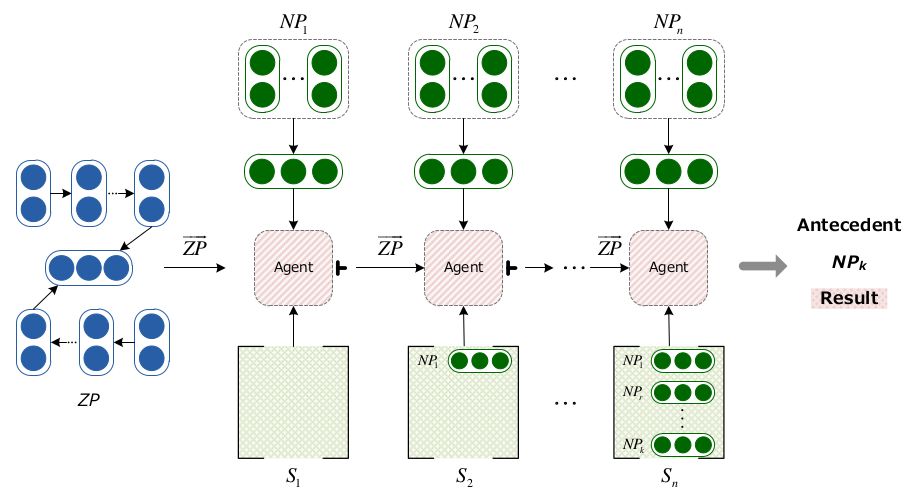
图2 基于强化学习的中文零指代消解方法流程图
3.2.1 状态
我们的状态向量定义为零代词,候选先行语和先行语信息的组合。对于时间 t, 状态向量st定义为:
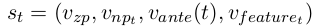
这里 vzp 和 vnpt是零代词 zp 和候选先行语 npt 在时间 t 的向量表示。另外,我们还引入了一些人工设计的特征向量 vfeaturet 进行计算,这些特征都是从以往的零代词消解工作中得到的(Zhao and Ng, 2007; Chen and Ng, 2013; Chen and Ng, 2016)。vante(t)表示先行词信息,这些信息是从之前被判断为正例的先行词中得到的。之后,我们把这个向量当做状态,然后放入后续的深度强化学习智能体(Agent)来产生动作。
3.2.2 回报
我们将回报定义为一个序列上的所有先行词计算出的F值。
3.3 强化学习智能体
在这篇文章中,我们利用 ZP-centered神经网络模型(Yin et al., 2017a)来建模零代词,利用一个RNN来建模候选先行语。通过这种方式,我们可以得到零代词和其候选先行语的向量表示:vzp 和{vnp1, vnp2 ,…, vnpn}。另外,我们利用Pooling的操作来获取先行语信息。对于时间t,我们利用max-pooling和average-pooling产生两个向量,然后把这两个向量当做先行词信息。假设在时间t,之前选取的所有先行语写作 S(t) = [vnpi, vnpj ,…, vnpr],我们的先行语信息向量 vante(t)k 可以被定义为:
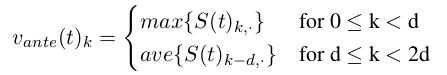
我们的智能体的输入就是状态向量 st ,其输出对应着两个动作的概率,结构如图3所示。
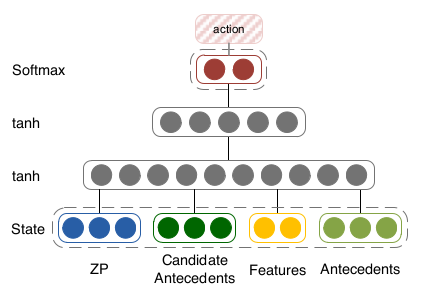
图3 智能体结构图
我们的智能体是由一个前馈神经网络构成,其包括了两个隐层,每个隐层的激活函数都是tanh。对于每一层,我们得到其输出:
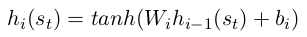
然后我们将最后隐层的输出当做输入到一个维数为2的得分层:
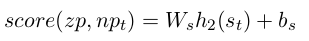
通过这种方式,我们得到每个动作的得分,然后放入一个softmax得到每个动作的概率:
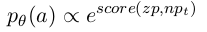
在这个工作中,我们利用策略梯度网络来进行强化学习。特别的,我们的目标函数定义为最大化回报期望:
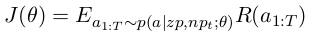
这里p(a|zp,npt;θ) 表示选取动作 a的概率。
4 实验结果
我们在OntoNotes 5.0语料上进行了实验,并选取了目前世界上最好的中文指代消解系统作为基准系统进行对比。在实验的过程中,根据不同情况的特点,我们共设计了三组对比实验。OntoNotes语料是由6个不同来源的语料组成的,其分别为:广播新闻(BN)、报纸新闻(NW)、广播采访(BC)、电话通话(TC)、微博(WB)和杂志(MZ)。我们的每组实验除了在整体语料上对比外,还对其不同分类做出了对比。我们假设所有的零代词的可消解性都是标注好了的,即只对可消解的零代词进行消解,并且依存树结构是人工标注的标准树结构(Gold Parse),实验结果如表1所示。
表1 实验结果
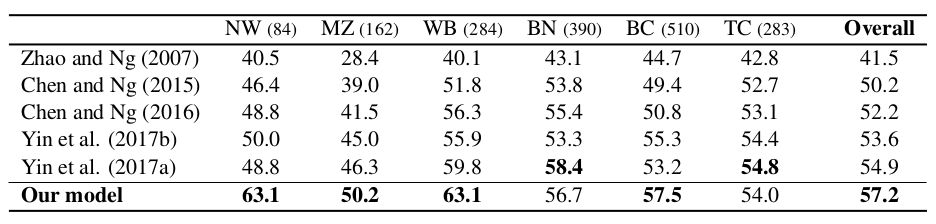
从结果中,我们不难看出,我们的方法是整体显著优于基准系统方法的在不同源的语料上测试,我们的方法能够在大部分来源的语料上超越基准系统,尤其是在文本数目最大的BC语料上,我们的方法优于所有的基准系统。综上所述,我们提出的基于强化学习的中文零指代消解算法能有效够提升中文零指代消解的效果。
5 总结
传统的中文零代词消解工作中,都采用了单独选的先行语分类策略,并没有能够充分利用先行语信息。而单个先行语带来的信息是有限的,这种单分类模型只能从局部最优的角度选取先行语,并不能从整体出发而给出答案,因此是不可靠的。为了避免这种情况的发生,我们提出了一种基于强化学习的中文指代消解算法,利用强化学习的思想将但分类问题转化为序列决策分类问题,充分利用了先行语的信息,因而得到更好的结果。论文发表在ACL 2018 https://arxiv.org/abs/1806.03711
ACL 2018与IJCAI 2018系列原创往期推送:
本期责任编辑: 赵森栋
本期编辑: 赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。