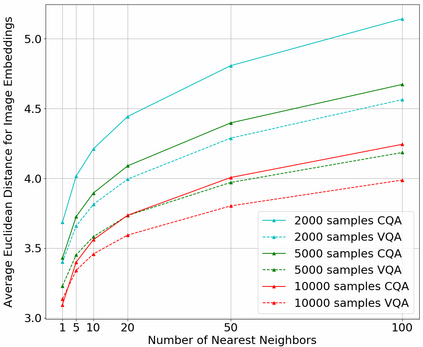
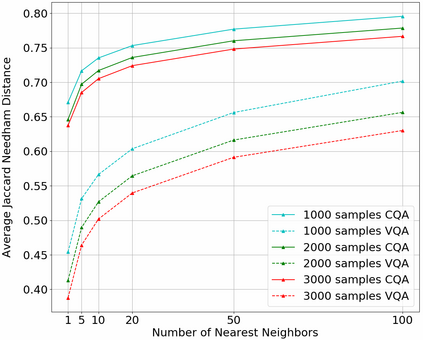
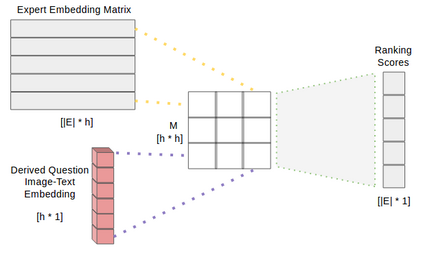
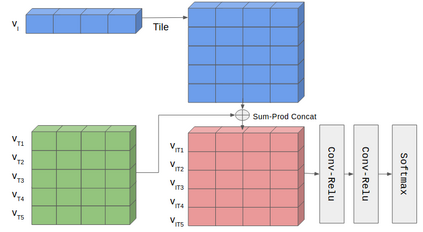
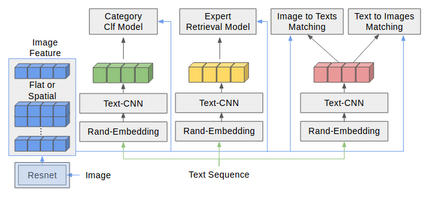
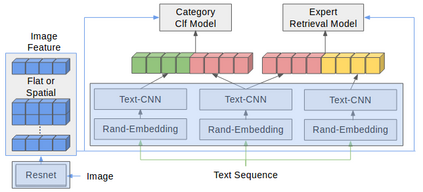
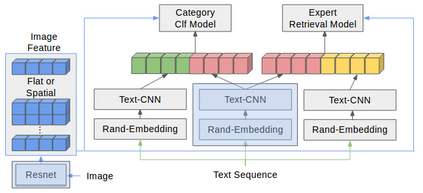
In this work, we present novel methods to adapt visual QA models for community QA tasks of practical significance - automated question category classification and finding experts for question answering - on questions containing both text and image. To the best of our knowledge, this is the first work to tackle the multimodality challenge in CQA, and is an enabling step towards basic question-answering on image-based CQA. First, we analyze the differences between visual QA and community QA datasets, discussing the limitations of applying VQA models directly to CQA tasks, and then we propose novel augmentations to VQA-based models to best address those limitations. Our model, with the augmentations of an image-text combination method tailored for CQA and use of auxiliary tasks for learning better grounding features, significantly outperforms the text-only and VQA model baselines for both tasks on real-world CQA data from Yahoo! Chiebukuro, a Japanese counterpart of Yahoo! Answers.
翻译:在这项工作中,我们提出了一些新方法,以调整具有实际意义的社区质量评估任务可视质量评估模式(自动问题分类和寻找专家回答问题)中包含文字和图像的问题。据我们所知,这是在质量评估中应对多式联运挑战的首次工作,也是在基于图像的CQA上基本回答问题的一个有利步骤。 首先,我们分析了视觉质量评估和社区质量评估数据集之间的差异,讨论了直接将VQA模型应用到CQA任务中的局限性,然后我们建议对基于VQA的模型进行新的增强,以更好地解决这些限制。我们的模型,通过为CQA定制的图像-文字组合方法的增强,以及利用辅助任务学习更好的地貌特征,大大超越了实际世界CQA数据的文本和VQA模型基线。 雅虎的日本对口者Chiebukuro! 答案。