摘要
知识图谱(KGs)在工业和学术领域有很多应用,这反过来又推动了朝着大规模地从各种来源提取信息大量的研究工作。尽管付出了这些努力,但众所周知,即使是最先进的KGs也是不完整的。链路预测(Link Prediction, LP)是一种根据KG中已存在的实体去预测缺失事实的任务,是一种有前途的、广泛研究的、旨在解决KG的不完整的任务。在最近的LP技术中,基于KG嵌入的LP技术在一些基准测试中取得了很好的性能。尽管这方面的文献在迅速增加,但对这些方法中各种设计选择的影响却没有引起足够的注意。此外,这一领域的标准做法是通过测试大量的事实来报告准确性,其中一些实体被过度表示;这允许LP方法通过只修改包含这些实体的结构属性来展示良好的性能,而忽略KG的主要部分。本篇综述分析提供了基于嵌入的LP方法的全面比较,将分析的维度扩展到常见的文献范围之外。我们通过实验比较了16种最先进的方法的有效性和效率,考虑了一个基于规则的基准,并报告了文献中最流行的基准的详细分析。
介绍
知识图谱(KGs)是真实世界信息的结构化表示。在一个KG中,节点表示实体,例如人和地点;标签是连接它们的关系类型;边是用关系连接两个实体的特定事实。由于KGs能够以机器可读的方式对结构化、复杂的数据进行建模,因此它被广泛应用于各个领域,从问答到信息检索和基于内容的推荐系统,并且对于任何语义web项目都非常重要。常见的KG有FreeBase、WikiData、DBPedia、Yago和行业KG有谷歌KG、Satori和Facebook Graph Search。这些巨大的KG可以包含数百万个实体和数十亿个事实。
尽管有这样的努力,但众所周知,即使是最先进的KGs也存在不完整性问题。例如,据观察FreeBase是用于研究目的的最大和最广泛使用的KGs之一,但是在FreeBase中超过70%的个体没有出生地点,超过99%的个体没有民族。这使得研究人员提出了各种各样的技术来纠正错误,并将缺失的事实添加到KGs中,通常称为知识图谱补全或知识图谱增强任务。可以通过从外部源(如Web语料库)提取新的事实,或者从KG中已经存在的事实推断缺失的事实,来增长现有的KG。后来的方法,称为链接预测(LP),是我们分析的重点。
LP一直是一个日益活跃的研究领域,最近受益于机器学习和深度学习技术的爆炸式增长。目前绝大多数LP模型使用原始的KG元素来学习低维表示,称为知识图谱嵌入,然后利用它们来推断新的事实。在短短几年的时间里,研究人员受到RESCAL和TransE等一些开创性工作的启发,开发了几十种基于不同的架构的新模型。这一领域的绝大多数论文都有一个共同点,但也存在问题,那就是它们报告的结果汇总在大量的测试事实之上,其中很少有实体被过度表示。因此,LP方法可以在这些基准上表现出良好的性能,只对这些实体进行访问,而忽略其他实体。此外,当前最佳实践的局限性可能使人们难以理解这一文献中的论文是如何结合在一起的,以及如何描述出值得追求的研究方向。除此之外,目前技术的优点、缺点和局限性仍然是未知的,也就是说,几乎没有研究过允许模型更好地执行的情况。粗略地说,我们仍然不知道是什么可以让一个事实变得容易还是难以学习和预测。
为了缓解上述问题,我们对一组有代表性的基于KG嵌入的LP模型进行了广泛的比较分析。我们优先考虑最先进的系统,并考虑属于广泛的体系结构的工作。我们从零开始对这些系统进行训练和调整,并通过提出新的、信息丰富的评估实践,提供超出原始论文的实验结果。具体是:
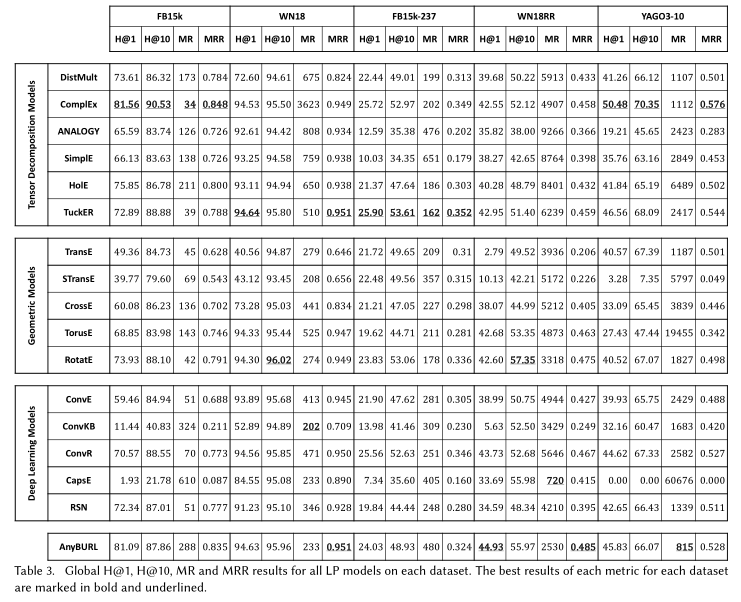
我们考虑了16个模型,属于不同的机器学习和深度学习架构;我们还采用了一个基于规则挖掘的附加的最先进的LP模型作为基线。我们提供了实验比较考虑的方法的详细描述和相关文献的总结,以及知识图谱嵌入技术的教育分类。 我们考虑了5个最常用的数据集,以及目前用于基准测试的最流行的指标;我们详细分析了它们的特点和特性。 对于每个模型,我们为每个数据集提供了效率和有效性的定量结果。 我们在训练数据中提出一组结构特征,并测量它们如何影响每个模型对每个测试事实的预测性能。
方法概述
在本节中,我们描述并讨论了基于潜在特征的知识管理的主要方法。正如在第2节中所描述的,LP模型可以利用各种各样的方法和架构,这取决于它们如何对优化问题进行建模,以及它们实现来处理优化问题的技术。
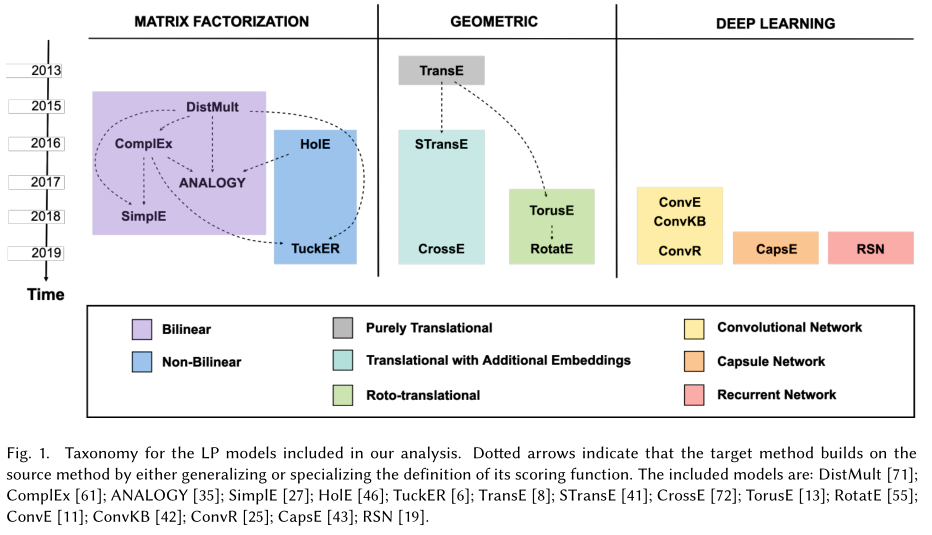
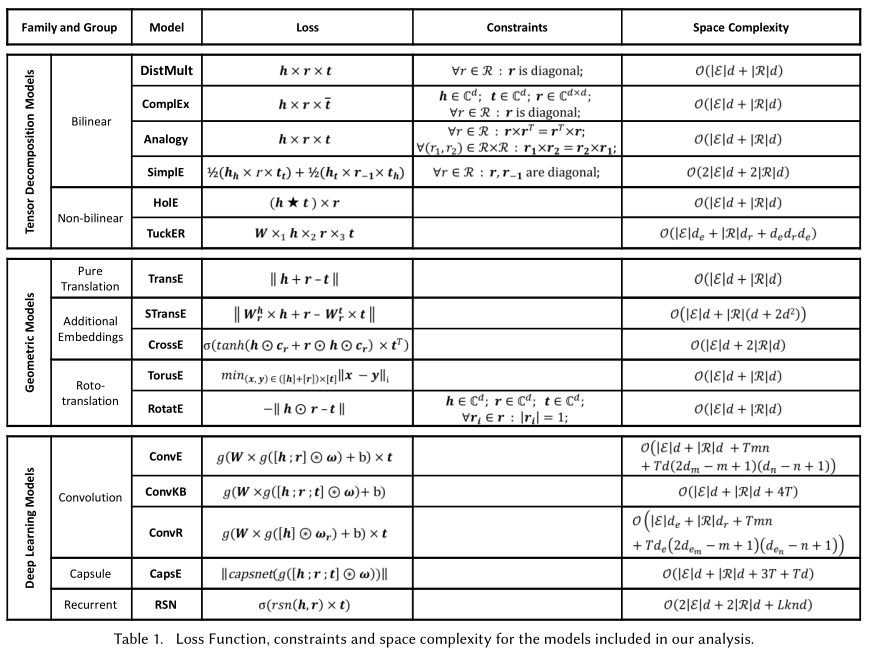
为了概述它们高度不同的特征,我们提出了一种新的分类法,如图1所示。我们列出了三个主要的系列模型,并进一步将它们划分为更小的组,以独特的颜色标识。对于每个组,我们都包括最有效的代表性模型,优先考虑那些达到最先进性能的模型,并且在任何可能的情况下,优先考虑那些具有公开可用实现的模型。结果是一组16个模型,基于极其多样化的架构;这些是我们随后在比较分析的实验部分所使用的模型。对于每个模型,我们还报告了发表的年份以及从其他模型得到的信息。我们认为,这种分类有助于理解这些模型和在我们的工作中进行的实验。表1报告了关于所包括的模型的进一步信息,例如它们的损失函数和空间复杂性。我们确定了三大类模型:1)张量分解模型;2)几何模型;3)深度学习模型。
张量分解模型
这个家族的模型将LP解释为一个张量分解的任务。这些模型隐式地将KG考虑为一个三维邻接矩阵(即一个3维张量),由于KG的不完整性,这个邻接矩阵只有部分可观测。张量被分解成低维向量的组合(比如一个多线性乘积):这些向量被用作实体和关系的嵌入表示。张量分解的核心思想是,只要训练集训练不过拟合,则学习到的嵌入应该能够泛化,并将高值与图邻接矩阵中不可观测的真实事实相关联。在实践中,每个事实的得分都是通过对事实中涉及的特定嵌入进行组合计算得出的;通过优化所有训练事实的评分函数,可以像往常一样进行学习嵌入。这些模型倾向于使用很少或根本没有共享参数;这使得它们特别容易训练。
几何模型
几何模型将关系解释为潜在空间的几何变换。对于给定的事实,头实体嵌入进行空间转换τ,使用嵌入的关系作为参数的值。对事实评分的值是结果向量和尾向量之间的距离;这样则可以使用距离函数计算δ(例如L1和L2范数)。
深度学习模型
深度学习模型使用深度神经网络来执行LP任务。神经网络学习参数,如权重和偏差,它们结合输入数据,以识别显著模式。深度神经网络通常将参数组织成独立的层,通常穿插非线性激活函数。
随着时间的推移,人们开发了许多不同类型的层,对输入数据应用不同的操作。例如,全连接层将把输入数据X与权重W结合起来,并添加一个偏差B: W X + B。为了简单起见,在下面的公式中我们将不提及偏差的使用,使其保持隐式。更高级的层执行更复杂的操作,如卷积层(它学习卷积内核以应用于输入数据)或递归层(以递归方式处理顺序输入)。
在LP任务中,通常结合各层的权重和偏差来学习KG嵌入;这些共享的参数使这些模型更有表现力,但可能导致参数更多,更难训练,更容易过拟合。