赛尔原创 | IJCAI 2018基于图结构的实体和关系联合抽取模型简介
1. 前言
实体和关系抽取是信息抽取领域的的重要研究问题。如图1所示,其输入是非结构化文本,输出则是识别出的实体及其对应的语义关系。其中,实体与关系之间、以及关系与关系之间都存在着很强的关联性。例如,Live_In关系往往对应着 Person 和 Location两种实体,反之亦然。Live_In关系(对应实体“John” 和实体 “California”) 可以由Live_In关系(对应实体 “John” 和实体 “Los Angeles”) 和 Loc_In关系(对应实体 “Los Angeles“ 和实体 “California”)推理出来。
以往的很多工作都是采用串联的方式来解决这两个任务,也就是说先识别出实体,然后再在实体识别的基础上识别出对应的关系,这种方法的一个主要问题就是所谓的错误传播,还有就是其不能很好的利用实体和关系之间的关联性。所以,目前的一个比较主流的研究思路就是采用联合抽取的方法。对于联合抽取方法,一个很重要的点就是如何充分的建模实体和关系以及关系与关系之间紧密的关联性。
联合抽取方法可以细分为基于统计的方法和基于神经网络的方法。基于统计的方法的性能严重依赖于复杂的特征工程,而且很难利用全局的特征。基于神经网络的方法则可以自动学习非局部的特征,在联合抽取任务上取得了更好的实验结果。但是,目前大部分的基于神经网络的方法仅仅是通过参数共享的方式来实现联合抽取,其导致实体和关系以及关系和关系之间的联系不能被很好的利用。(Zheng et al., 2017)是第一种将实体识别和关系抽取两个任务转化成一个任务来做的基于神经网络的方法。其通过设计一个标签体系,从而将联合抽取问题转化成一个序列标注问题。这种序列标注方法的一个主要问题是如果一个实体同时和另外两个实体有关系,其只能识别出其中的一个关系。还有一个问题是,其并不能显示的建模实体与关系以及关系与关系之间的联系。
基于以上观察,我们通过设计一套转化规则,将实体识别和关系抽取联合任务转化为一个有向图的生成问题,并使用基于转移的方法来直接生成该有向图。如图1所示,与传统的句法任务不同,我们的输出结构中每个节点可能含有多个或零个父节点。因此,我们提出了一种新的转移系统,通过递增的融合实体信息及其相应的关系信息,我们的方法不仅可以对实体和关系之间的关联性进行建模,而且还可以很好的表示关系之间的关联性。
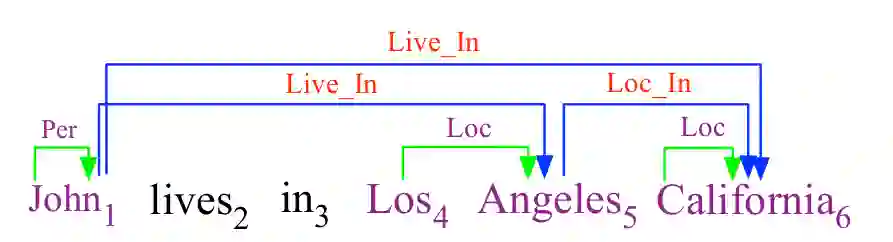
图1 实体和关系抽取(绿色表示实体弧,蓝色表示关系弧)
这项工作的主要贡献总结如下:
我们通过设计一套转化规则,将实体识别和关系抽取联合任务转化为一个有向图的生成问题,
基于有向图的特点, 我们设计了一套转移系统来生成该有向图。另外,为了更好的建模关系和关系之间的依赖性,我们设计了一个特殊的递归神经网络。
2. 模型介绍
2.1 转化策略
在我们定义的有向图中,图中的节点对应于输入句子中的单词。 有向弧分为两类:
表示实体内部结构的实体弧;
表示实体之间关系的关系弧,其中父节点表示关系对应的第一个实体,子节点表示关系对应的第二个实体。
为了处理一个实体有多种关系的情况,有向图中的每个节点可以有多个父节点,这与传统的依存句法树等句法任务有所区别。如图1所示,其中输入句子包含:1)三个实体,它们被转换成具有实体标签的相应的绿色有向弧;和2)三个关系,它们被转换成具有关系标签的相应的蓝色有向弧。另外,与最终结果无关的其他词语没有相应的弧线。
2.2 转移系统
为了生成该有向图,我们采用了一种基于转移的方法,这个方法主要受arc-eager算法(Choi and McCallum, 2013)的启发。我们主要设计了两类转移动作:1)实体生成动作,用于生成实体弧; 2)关系生成动作,用于生成对应的关系弧。
在状态表示上,我们使用元组(σ,δ,e,β,R, E)来表示每个时刻的状态,其中σ是一个保存已生成实体的栈,δ是一个保存被从σ临时弹出,但是之后会被重新压入σ的实体的栈,e是用来存储正在被处理的部分实体块,β是一个包含未处理词的缓冲区。R用来保存已经生成的关系弧。E用来保存已经生成的实体弧。我们使用索引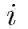
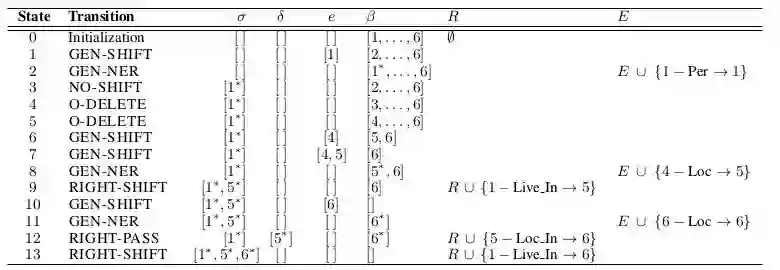
表1 转移过程(∗表示一个实体)

表1给出了具体的动作集合定义。前七个动作用于生成关系弧,最后三个动作用于生成实体弧。其中,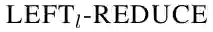
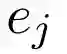
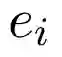
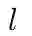
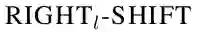
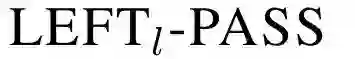
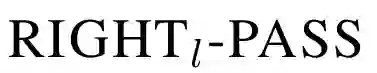
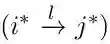


表2 转移操作的先决条件

表 3显示了图1中的输入句子所对应的动作执行序列。初始状态是([ ],[ ],[ ],[1,…,n],∅,∅),,而终止状态是(σ,δ,[ ],[ ],R,E)。
表3 图1中的实体和关系图的转换序列
2.3 搜索算法
基于上述转换系统,我们的解码器为每个给定句子预测其最佳动作序列。系统初始化时,把输入句子以相反的顺序压入β中,这样第一个单词就在β的顶部。σ,δ,e和A每个都包含一个空栈标记。在每一步预测中,系统通过计算模型状态的表示(由β,σ,δ,e和A决定)来预测要执行的动作。无论其他状态如何,当β和e都为空(空栈符号除外)时,解码完成。
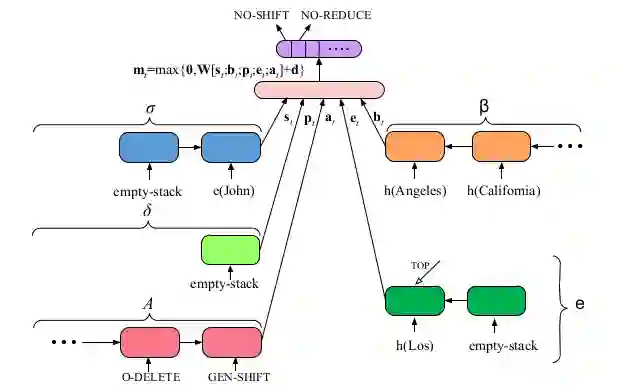
图2 表3中模型状态6地表示
(h(*)表示每个令牌的Bi-LSTM表示,e(*)表示实体及其关系的组成)
如图2所示,t 时刻的模型状态mt 被定义为:
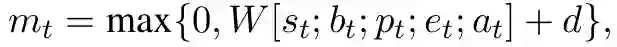
其中W是要学习的参数矩阵,st是σ的表示形式,bt是β的表示形式,pt是δ的表示形式,et是e的表示形式,at是A的表示形式,d是一个偏置项。
模型状态mt用于计算t时刻选取动作的概率:
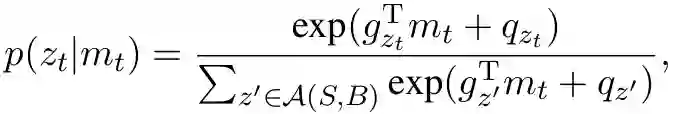
其中gz表示转换动作z的列向量,qz是动作z对应的偏置项。集合A(S, B)表示在当前状态下可以采取的合理操作的集合。给定输入句子,任何合理的动作序列z的概率可以表示为:
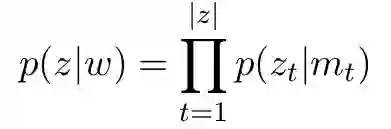
后我们可以得到
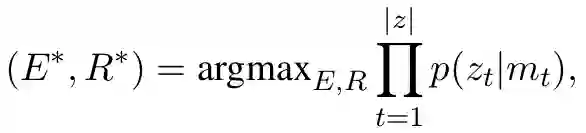
因此,实体识别和关系抽取联合任务就被集成到我们的转移系统中。在测试的时候,我们的算法贪心的选择最大概率的动作,直到满足终止状态条件。
3. 实验
我们使用公开数据集 NYT 作为我们的数据集。我们采用标准的Precision(Prec),Recall(Rec)和F1-score来评估模型性能。跟(Zheng et al., 2017)一致,计算最终F1-score时,不考虑实体类型的标签。也就是说,当关系类型及其对应的两个实体的边界都正确时,该关系被认为是正确的。跟(Zheng et al., 2017)一样,我们从测试集中随机抽样10%作为开发集,并将其余数据用作测试集。
表4 在NYT上与以前最先进的方法进行比较
(第一部分(从第1行到第3行)是管道方法,第2部分(第4行到第6行)是联合提取方法,第3部分(第7行到第9行)是端到端方法。)
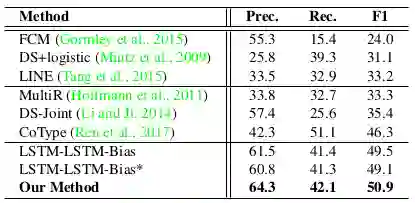
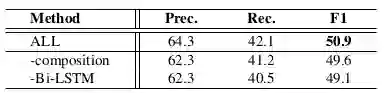
我们将我们的方法跟之前的串联方法,联合方法等进行对比。结果如表4所示,我们的基于图的方法获得了最高的F1-score,另外,模型的准确率也是最高的。为了验证各个模块的性能,我们做了消融实验。结果如表5所示,我们发现在初始化β时候采用的双向lstm表示,以及针对关系之间的联系而设计的递归递归神经网络对性能提升有很重要的影响。更多具体的实验分析可以参考我们的英文原文。
表5 NYT上的消融测试
4. 结论
针对实体识别和信息抽取联合任务,我们通过设计一套转化规则,将实体识别和关系抽取联合任务转化为一个有向图的生成问题。基于有向图的特点, 我们设计了一套转移系统来生成该有向图。我们的方法能够很好的表示和利用实体和关系以及关系与关系之间的关联性,在NYT数据上取得了不错的结果。
本期责任编辑: 赵森栋
本期编辑: 赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






