【工大SCIR Lab】AAAI20 基于关键词注意力机制和回复弱监督的医疗对话槽填充研究
论文名称:Understanding Medical Conversations with Scattered Keyword Attention and Weak Supervision from Responses
论文作者:施晓明,胡海峰,车万翔,孙钟前,刘挺,黄俊洲
原创作者:施晓明
下载链接:http://ir.hit.edu.cn/~car/papers/AAAI2020-Shi-medconv.pdf转载来自:哈工大SCIR
(本工作完成于腾讯公司实习期间)
1. 医疗对话槽填充任务简介
语音识别和自然语言处理的最新进展促进了口语对话系统(Spoken Dialogue System)作为信息访问自然接口的广泛应用,其中典型的应用包括自动化呼叫中心及智能设备的虚拟助理。口语对话系统中的一个关键组成部分是口语理解(Spoken Language Understanding),旨在将自然语言解析为计算机能够有效处理的逻辑语义表示。槽填充(Slot Filling)是其中一个重要的模块,通常被视为一个结构化预测问题,其中有监督学习算法,特别是递归神经网络(RNN)获得了比较好的效果。传统的槽填充是根据预先设定好的领域词对用户问句进行序列标注,标注其中领域相关的核心词,从而从预测的标注中提取出结构化的语义表示。

图1 医疗对话槽填充的一个例子
2. 任务挑战

图2 医疗对话数据与标注之间不对齐现象的一个例子
第二个挑战是精标注的医疗对话数据难获取。医疗对话数据标注需要具备专业医学知识的标注人员,这些标注人员必须具备专业的医学知识,导致注释成本高。
3. 方法介绍
由于医疗对话数据和标注不对齐的问题,不能以传统的序列标注任务来建模。因此,我们将该任务定义为多标签分类问题,其中输入为医疗对话数据,输出为该语句的语义结构化表示。此外,为了更好地识别患者口语化表述中的不连续关键词,我们使用了关键词注意力机制,旨在使得模型对医学关键词更加敏感。
面对数据标注成本高的挑战,我们利用大量无标注数据,将回复作为问句的弱标注信息,从而减少对于精标注数据的需求。具体来说,在线医学社区中存在着大量的医学对话,医生总是在他们的回复中用专业化的表达来复述病人的症状,这很容易通过字符串匹配医学知识库中的医学概念来获得医学术语。如图2中的示例,医生提到了槽值“腹痛”,而该术语正是患者陈述的病症。因此,基于医生回复中的医学术语与病人的询问密切相关的直觉,我们提出了一种新的方法,将医生回复中的医学实体作为模型预训练的目标,然后再在标注良好的数据上进行精调。
3.1 关键词注意力机制
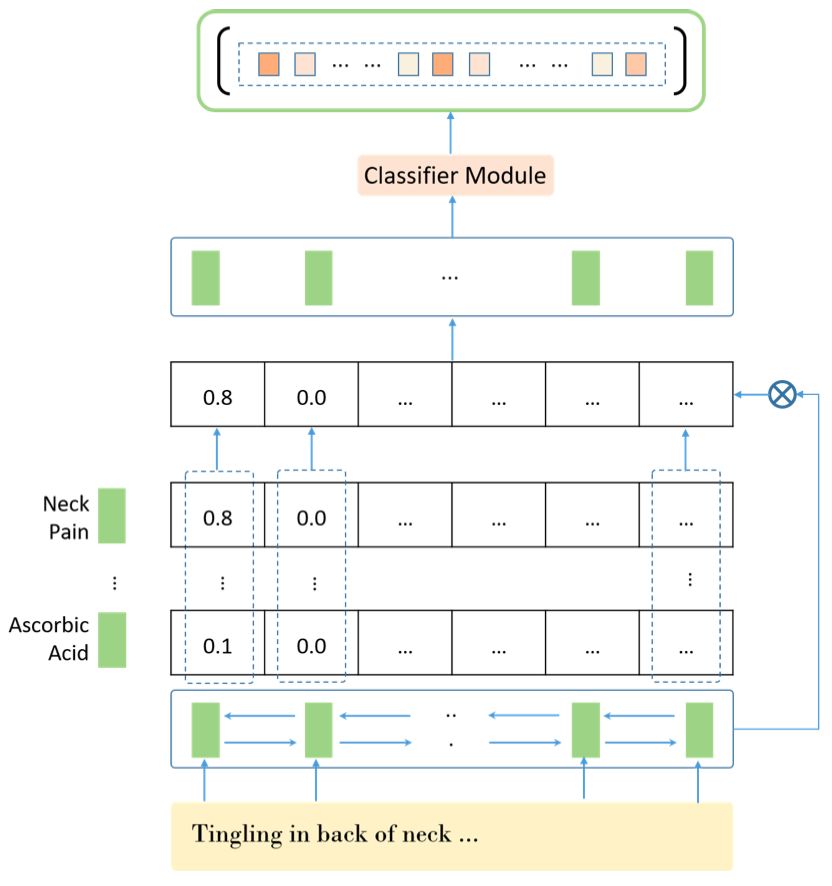
图3 关键词注意力机制示意图
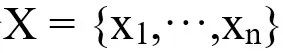 为输入陈述的词向量序列,
为输入陈述的词向量序列,
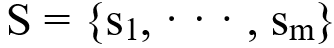 为候选症状的词向量表示。这两种表示相互作用,以学习两者之间的相似性度量,该度量判别一个单词是否与槽值对相关,然后取最大值:
为候选症状的词向量表示。这两种表示相互作用,以学习两者之间的相似性度量,该度量判别一个单词是否与槽值对相关,然后取最大值:
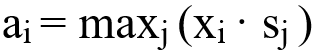 ,其中·表示点积,
,其中·表示点积,
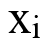 表示X中的第i个句子,
表示X中的第i个句子,
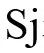 表示S中的第j个元素。然后患者陈述词序列可以表示为:
表示S中的第j个元素。然后患者陈述词序列可以表示为:
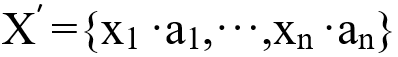 。
。
3.2 患者陈述编码及分类
编码器的目的是将自然语言输入请求转换为实值向量。我们使用几类文本分类编码器对输入自然语言序列进行编码,包括TextCNN[3]、RCNN[4],TextRNN[5],DRNN[6],RegionEmbedding[7],和Star-Transformer[8]。
3.3 模型预训练与精调

图4 模型预训练与精调框架图
3.3.1 弱监督数据用于预训练
医生的回答常常用正式的医学术语复述患者的症状,因此包含了与患者健康状况相关的医学术语。基于这种直觉,可以将医生的回答作为患者病情陈述的弱监督。同时,弱监督方法充分利用了未标注的数据,有助于降低标注成本。尽管使用无标注数据进行预训练可能会导致模型无法学习准确的标签,但它可以帮助模型消除大多数负面标签。在这之后,预训练得到的模型将根据标注良好的数据进行精调。
3.3.2 精标注数据用于模型精调
在上个阶段,分类模型已经学习了无标注数据的相关槽值信息(即已预训练),然后将模型训练在精标注数据上进行再训练。无标注数据预训练步骤有助于模型消除大多数负面标签,而精调步骤旨在根据精标注数据,使模型更准确地分类。
4. 实验结果及分析
4.1 实验数据
表1 数据集统计信息

4.2 实验结果
表2 主要实验结果
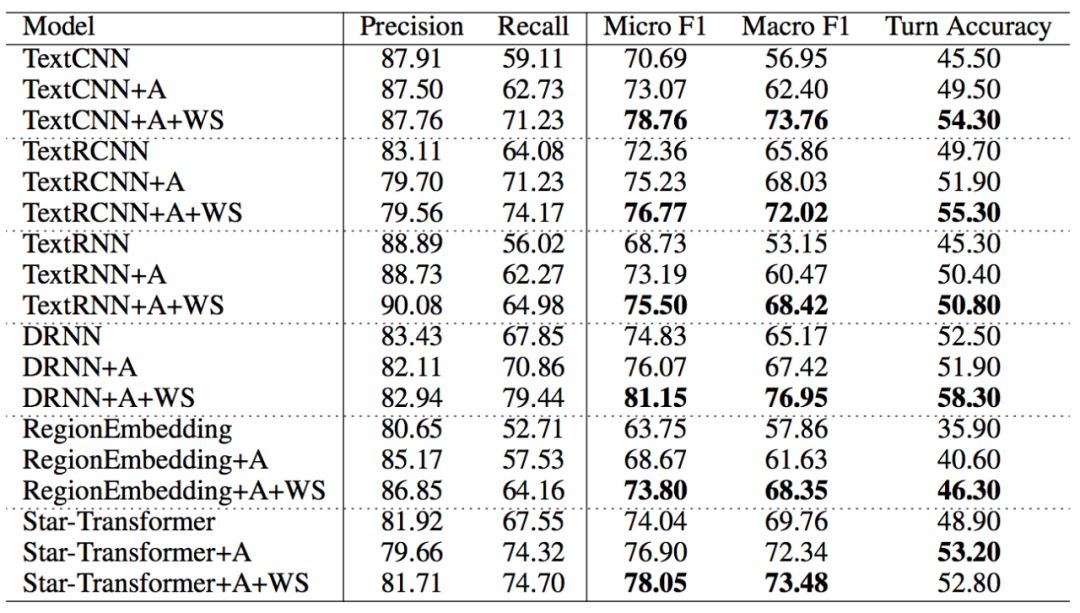 将原始分类器与添加关键词注意力机制的分类器进行比较,可以发现在Micro F1和Macro F1上,添加关键词注意力机制的模型分别比原始分类器的性能提高了3.12%和3.92%。这说明关键词注意力机制可以显著提高模型的性能。此外,关键词注意力机制在Macro F1上比在Micro F1上有更大的提高。这表明关键词注意力机制可以帮助模型在频次低的标签上改进更多。此外,关键词注意力机制使模型的召回率提高了5.27%,说明关键词有助于识别测试时训练数据中看不到的口语表达。这些结果表明,对分散的医学关键词给予更多的权重是提高任务效果的有效途径。
将原始分类器与添加关键词注意力机制的分类器进行比较,可以发现在Micro F1和Macro F1上,添加关键词注意力机制的模型分别比原始分类器的性能提高了3.12%和3.92%。这说明关键词注意力机制可以显著提高模型的性能。此外,关键词注意力机制在Macro F1上比在Micro F1上有更大的提高。这表明关键词注意力机制可以帮助模型在频次低的标签上改进更多。此外,关键词注意力机制使模型的召回率提高了5.27%,说明关键词有助于识别测试时训练数据中看不到的口语表达。这些结果表明,对分散的医学关键词给予更多的权重是提高任务效果的有效途径。
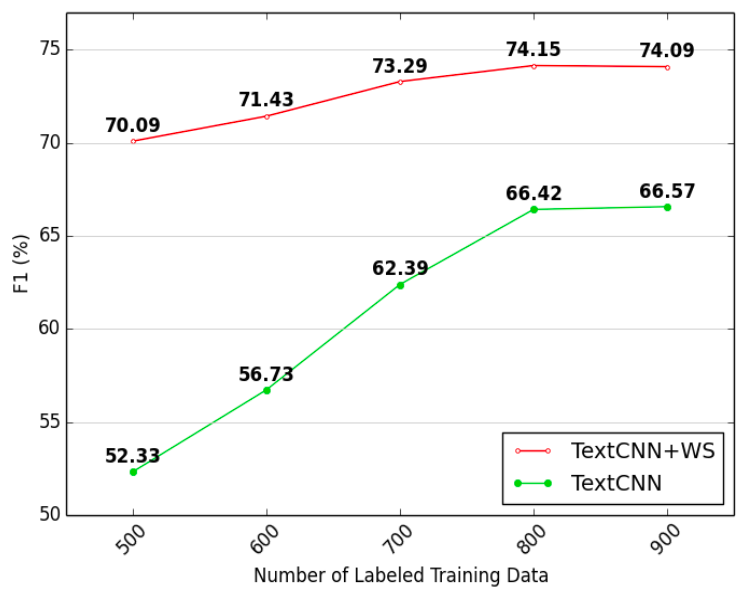
图5 精标注数据对于结果的影响
结果表明:1)当标注数据量较小时,弱监督会导致更多的提升;2)无标注数据的弱监督信息总是有助于模型获得更好的性能。由此可见,医生回复中的弱监督信息是十分有用的。
5. 总结
本文针对医疗槽填充任务的两个挑战,提出了关键词注意力机制和医生回复弱监督的方案。实验表明,该方法能显著提高模型的性能。今后,我们将从回复弱监督的角度,进一步完善数据,进而尝试更多的方式来提高医疗槽填充任务的性能。
参考文献
[1] Wei, Z.; Liu, Q.; Peng, B.; Tou, H.;Chen, T.; Huang, X.; Wong, K.-F.; and Dai, X. 2018. Task-oriented dialogue system for automatic diagnosis. In Proceedings of ACL 2018,201–207.
[2] Xu, L.; Zhou, Q.; Gong, K.; Liang, X.;Tang, J.; and Lin, L. 2019. End-to-end knowledge-routed relational dialogue system for automatic diagnosis. AAAI.
[3] Lai, S.; Xu, L.; Liu, K.; and Zhao, J.2015. Recurrent convolutional neural networks for text classification. In AAAI 2015.
[4] Liu, P.; Qiu, X.; and Huang, X. 2016.Recurrent neural network for text classification with multi-task learning. arXiv preprint arXiv:1605.05101.
[5] Yin, W., and Schu ̈tze, H. 2018. Attentive convolution: Equipping cnns with rnn-style attention mechanisms. TACL 6:687–702.
[6] Wang, B. 2018. Disconnected recurrent neural networks for text categorization. In Proceedings of ACL 2018, 2311–2320.
[7] Qiao, C.; Huang, B.; Niu, G.; Li, D.;Dong, D.; He, W.; Yu, D.; and Wu, H. 2018. A new method of region embedding for text classification. In ICLR.
[8] Guo, Q.; Qiu, X.; Liu, P.; Shao, Y.;Xue, X.; and Zhang, Z. 2019. Star-transformer. In Proceedings of NAACL-HLT 2019, 1315–1325.
赛尔原创 | AAAI20 基于多任务自监督学习的文本顺滑研究
赛尔原创 | AAAI20 基于选择两方面信息的文档级文本内容改写
本期编辑:冯梓娴





