干货 | 哈工大AAAI 2018录用论文解读:基于转移的语义依存图分析
AI 科技评论按:语义依存是中文语义的深层分析,完善的语义表示体系对语义依存分析有重要作用。本文介绍的工作来自哈工大 SCIR 实验室录用于 AAAI 2018 的论文《A Neural Transition-Based Approach for Semantic Dependency Graph Parsing》。
在近期 GAIR 大讲堂举办的线上公开课上,来自哈尔滨工业大学在读博士生王宇轩分享了一篇他在 AAAI 2018 投中的论文:基于转移的语义依存图分析。
以下是王宇轩同学在线上直播课上的分享内容,AI 科技评论做了简要回顾,完整视频回放链接请点击文末阅读原文。
分享内容
同学们,大家好,今天主要分享的是用一种基于转移的方法来进行语义依存图的分析。
首先介绍一下什么是语义依存分析。语义依存图是近年来提出的对树结构句法或语义表示的扩展,它与树结构的主要区别是允许一些词拥有多个父节点,从而使其成为有向无环图(direct edacyclic graph,DAG)。

右上图是 2012 年和北京语言大学合作定义和标注的语义依存树,通过一些依存弧把句子中有语义关系的词连接起来。它是树结构,所以成为语义依存树。右下角是语义依存图结构,因为在依存树里面,有一些词之间的关系受限于树结构,不能很好刻画,所以就引入了依存图概念。
语义依存图与传统树结构的区别
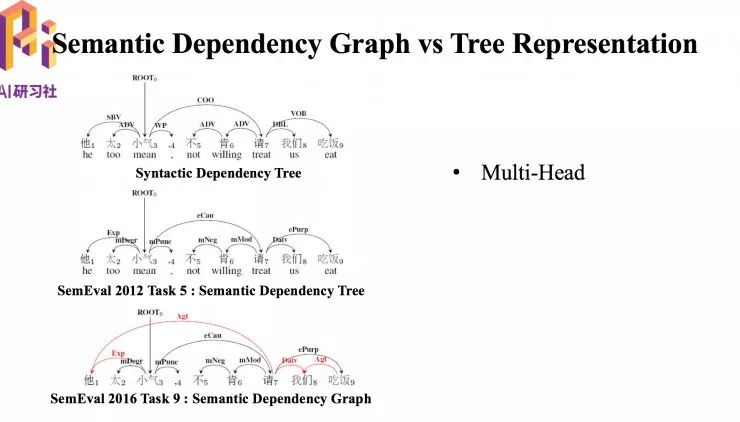
左上第一个是句法依存树,中间为语义依存树,最下面是语义依存图。图结构与原来传统的树结构表示最大的不同就是存在有多个父节点,比如图中的“我们”存在两个父节点。
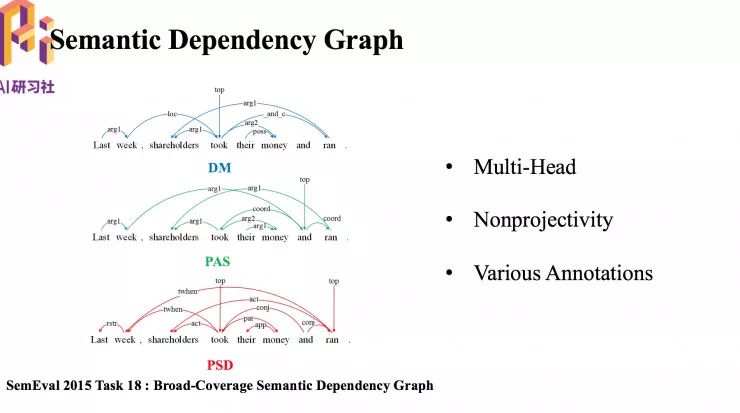
上图左边三个结构是另一种语义依存图结构。它们是在英文语料上进行标注,并且有三种标注规范,分别是 DM、PAS、PSD。由此可以看出在同一个句子中,由于标注规范不同,图结构也是不同的。这是依存图的第二个特点,具有多种标注规范。第三个特点事具有非投射性,弧之间有交叉。
语义依存图实际上就是有向无环图, 这篇论文的目的就是提出一个能适应多种标注规范的有向无环图的一个分析器。
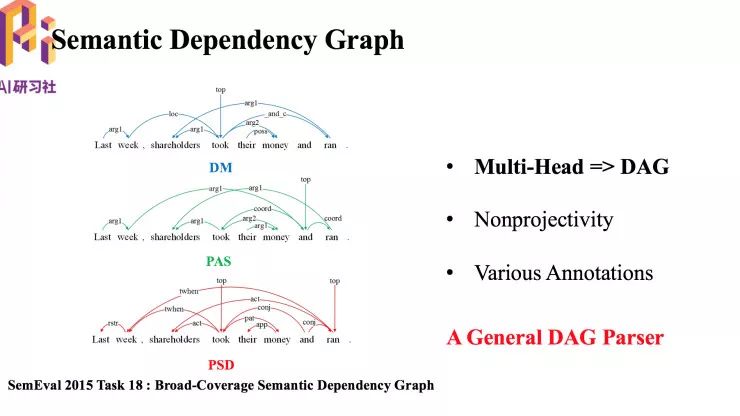
我们采用的是基于转移的语义依存分析方法。该方法主要分为两部分结构,一是预测,二是执行。预测部分是由一个分类器实现。执行部分需要一个转移算法 ,包括一些预定义的转移动作等。
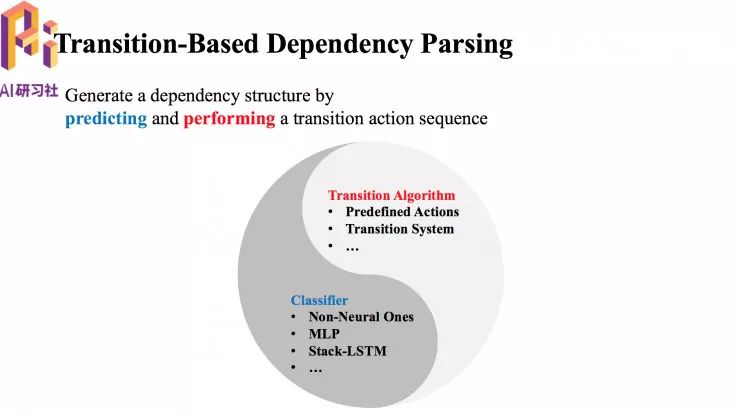
关于转移系统
首先有个缓存(buffer),用来保存将要处理的词。接下来是一个栈(stack),保存正在处理的词。还需要有一个存储器(memory),用来记录已经生成的弧。最后是一个 deque, 暂时跳过一些词。转移状态包括一个保存正在处理中的词的栈(Stack),一个保存待处理词的缓存(Buffer),和一个记录已经生成的依存弧的存储器。
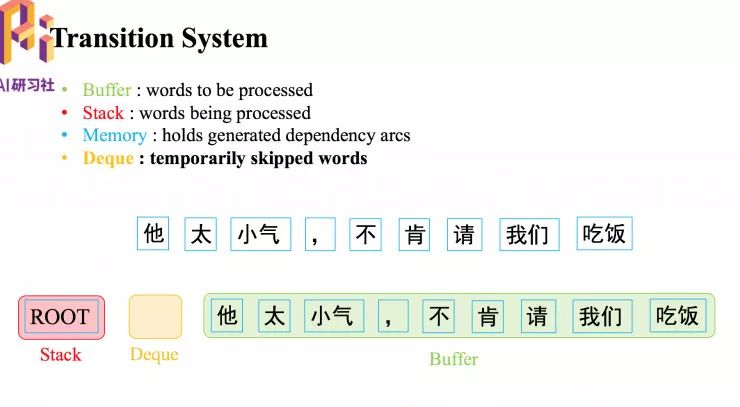
用来处理传统依存树结构的转移系统,以 Choi 等人在2013年提出的转移系统为例。
生成图中标红的弧线,首先要通过一个 LEFT-REDUCE 转移动作,LEFT 是生成一条由缓存顶的词指向栈顶词的一条弧,REDUCE,是指生成弧之后,将栈顶词消除掉。
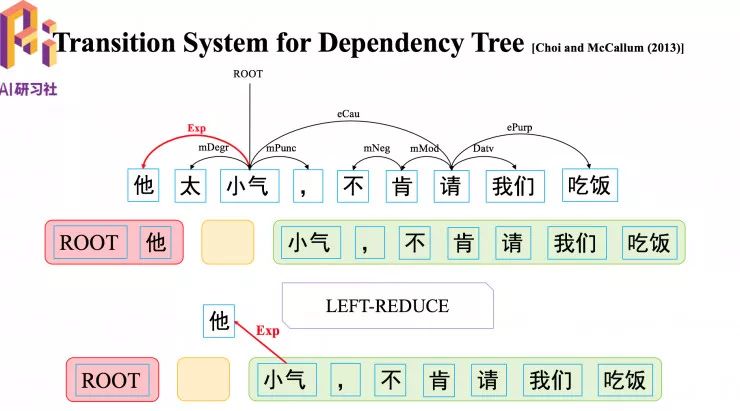
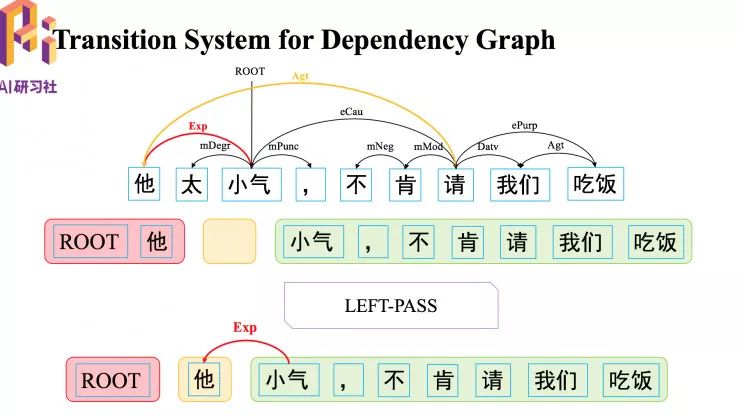
如何生成图中黄色的弧,首先执行一个 LEFT-PASS 转移动作,暂时不把“他”消除,经过一系列转移动作,再执行 LEFT-REDUCE 交互, 消除“他”。
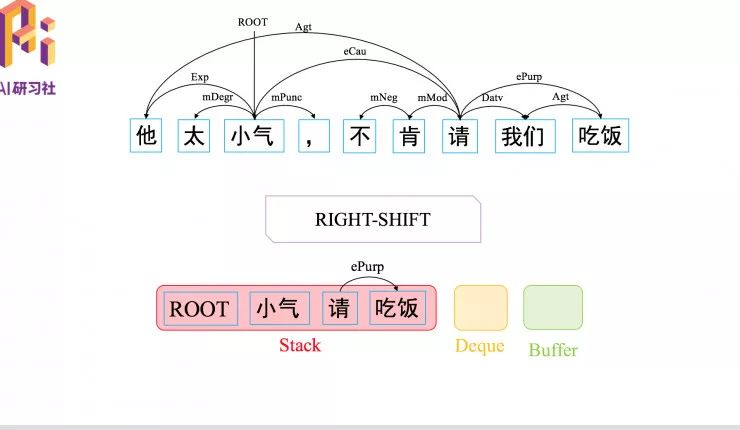
接下来是用一个具体例子介绍整个转移系统,包括更多的转移动作,具体可观看文末的视频回放。
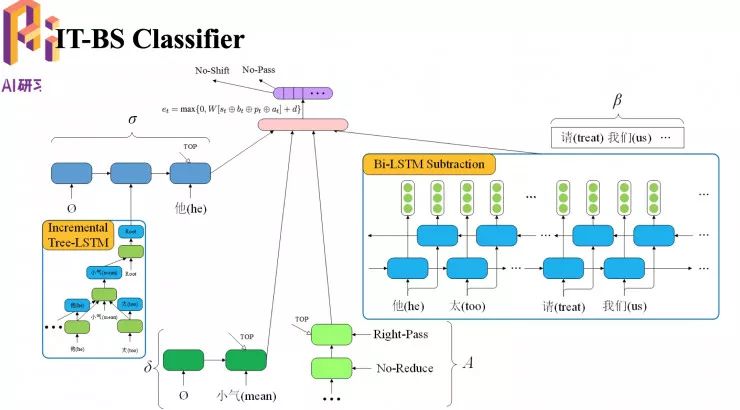
基于转移的语义依存分析方法中的分类器
图中的分类器存在一些问题,缓存会损失一些信息,因为缓存只能通过单向 LSTM 学到正在缓存中的词的表示,另外由于它是一个从右到左的单向 LSTM,因此它会损失从左到右这部分信息。
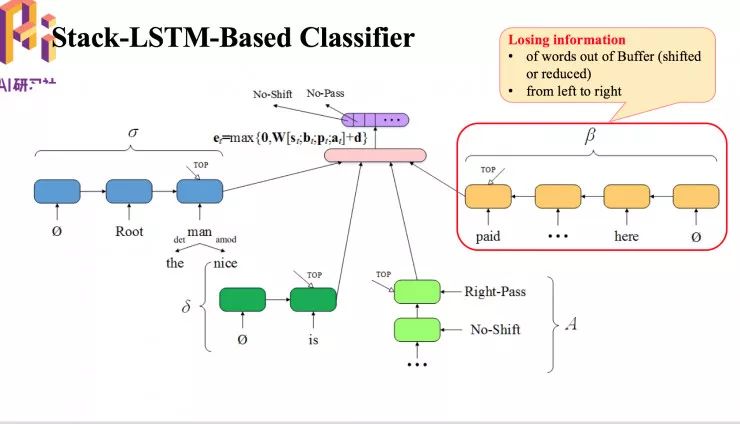
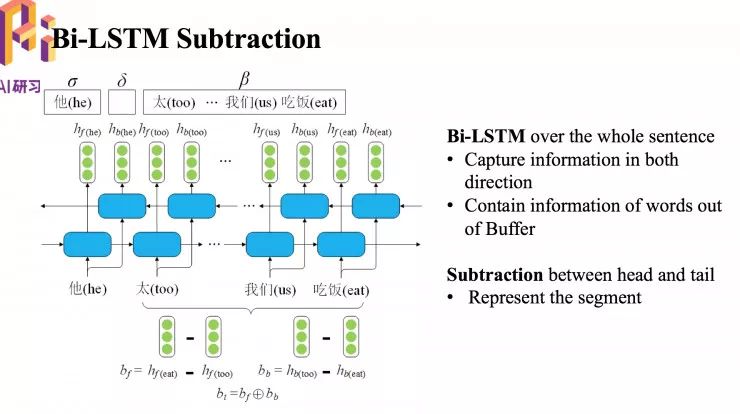
为了解决这个问题,我们提出了 Bi-LSTM 模块。
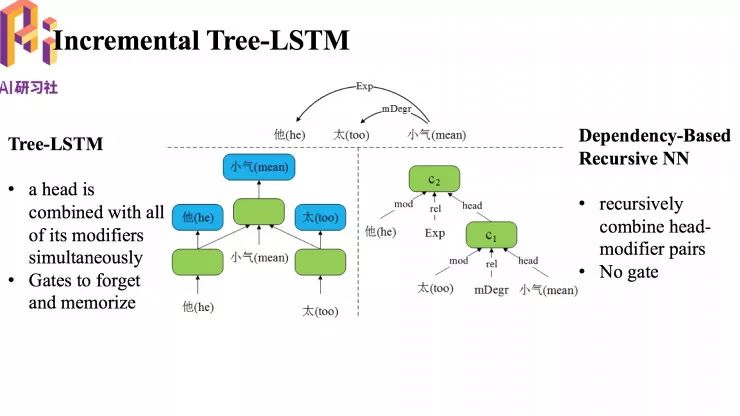
我们提出的 Incremental Tree-LSTM 和传统的 Dependency-Based Recursive NN 效果对比
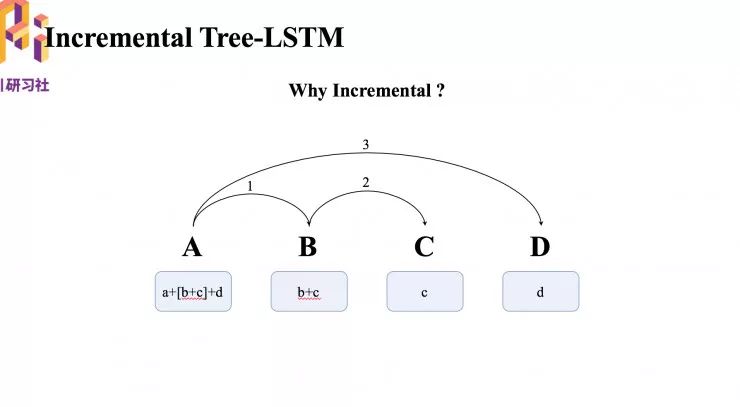
关于 Incremental Tree-LSTM
图中大写 ABCD 代表四个词,下面的小写可以认为它的向量化表示。
首相生成一个 A 指向 B 的弧,把A和B的子向量同时放到一个 LSTM 单元里面,组合起来用 a+b 表示,放在 A 下面,以此类推,每次找到新的子节点都会把原来已找到的子节点拿来一起输入,就不会损失 C 的信息。
上面提出的两个模块儿替换原来转移系统后的效果图
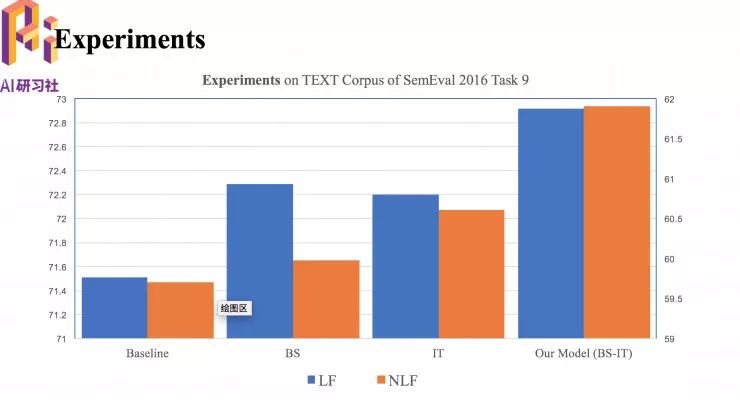
实验结果
简单介绍一下得到的实验结果,首先是在一个中文语义依存图的数据集 SemEval 2016 Task9 进行实验,其中最重要的两个评测指标 LF 和 NLF。图中 BS 是增加了第一种模块后的性能,IT 是增加第二个模块儿后的性能,BS-ST 是两个模块同时使用后整个模型的性能。
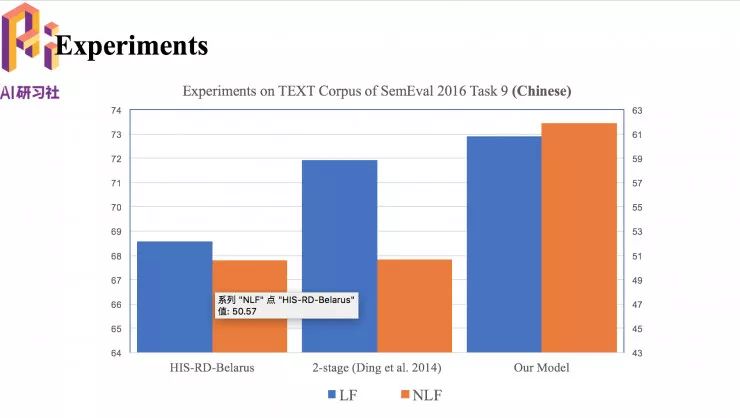
我们的模型和其他模型的性能对比
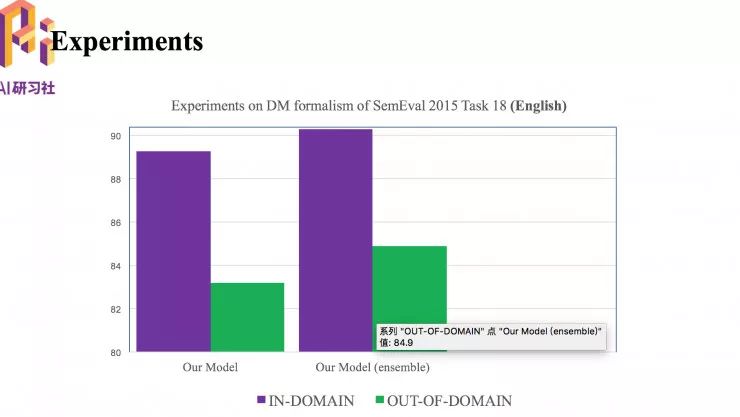
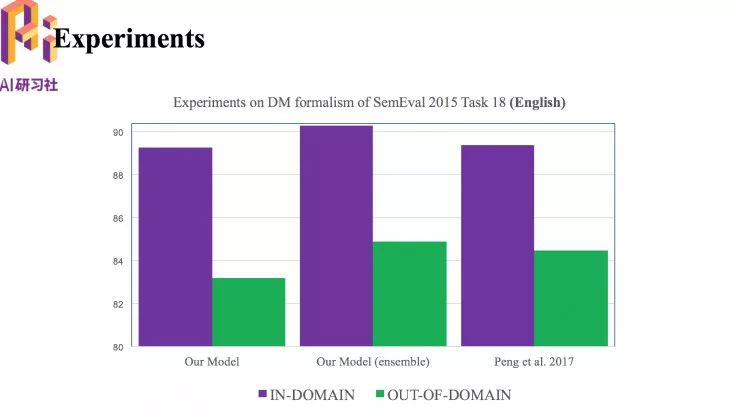
接下来是在 SemEval 2015 Task 18 上的英语数据集上的实验。这个数据的测试集包括两部分,紫色(in-domain)是指和训练数据来自同领域的数据,绿色(out-of-domain)是指和训练数据来自不同领域的数据,所以性能表现也不一样。
值得一提的是,我们的模型可以通过模型融合的方法,在训练过程中用不同的随机化种子,训练多个模型, 在预测的时候,用多个模型分别进行预测,得到多个当前状态下要执行的转移动作的概率分布,把多个概率分布对应的叠加起来,作为接下来判定的标准,这样的简单模型融合对模型性能有较大的提升效果。
最后给大家安利一个我们实验室的中文语言处理工具包,包括最底层的分词,词性标注,一直到上层的句法分时,语义分析都能够提供。可以下载到本地直接使用,也可以通过接口在线接入。

以上就是全部的分享内容。
更多直播预告敬请关注「AI 科技评论」。如果错过了直播课程,还可到 AI 慕课学院查找该期的视频回放,点击阅读原文直达本期回放页面。
————— AI 科技评论招人了 —————

————— 给爱学习的你的福利 —————
Fintech 年终思想盛宴
28 天『AI+金融』学习特惠
跟着民生技术总监、前瑞银大牛、四大行一线操盘手们一起充电
区块链、智能投顾、CCF ADL 智能商业课等都参与特惠
与大咖们碰撞思维
扫码了解活动详情
▼▼▼

————————————————————


