快手+中科大 | 全曝光推荐数据集KuaiRec 2.0版本
作者:高崇铭
单位:中国科学技术大学博士生,快手实习
在沉淀了一段时间后,我们推出了数据集KuaiRec的2.0版本。这是由我们中科大何向南团队与快手社区科学部门联合推出的,用于推荐系统的一个全曝光数据集。这也是推荐系统学界以及业界首个包含百万量级交互的超密集曝光数据。
数据集的详细信息可见官网文档:https://chongminggao.github.io/KuaiRec/
关于这个数据的的1.0版本的简介,可参考本文KuaiRec | 快手发布首个稠密度高达99%的推荐数据集, 可用于多种推荐系统方向研究。
什么是全曝光数据集?
在本数据集提出前,几乎所有的真实推荐数据集都是高度稀疏的,以下列举了一些常见的推荐数据集,给定了用户数目、商品数目、交互数目,以及对应的数据密度=交互数/(用户数*商品数)。可见绝大多数的推荐数据集密度是小于1%的。
| Dataset | #Users | #Items | #Interactions | Density | Types of interactions | # User Features | # Item Features |
|---|---|---|---|---|---|---|---|
| Movielens 1M | 6,040 | 3,706 | 1,000,209 | 4.47% | Rating: [1-5] | 4 | 1 |
| Movielens 10M | 69,878 | 10,677 | 10,000,054 | 1.34% | Rating: [0.5-5], tags | 0 | 1 |
| Movielens 20M | 138,493 | 26,744 | 20,000,263 | 0.540% | Rating: [0.5-5], tags | 0 | 1 |
| Movielens 25M | 162,541 | 5,9047 | 25,000,095 | 0.260% | Rating: [0.5-5], tags | 0 | 1 |
| Yelp | 1,987,897 | 150,346 | 6,990,280 | 0.00234% | Reviews | 21 | 13 |
| Alibaba | 106,042 | 53,591 | 907,470 | 0.0160% | Implicit | 0 | 0 |
| Jester | 73,421 | 100 | 4,136,210 | 56.34% | Rating: [-10, 10] | 0 | 0 |
| Book-Crossing | 92,107 | 271,379 | 1,031,175 | 0.0041% | Raing: [1, 10], and implicit | 4 | 2 |
| Last.fm-2k | 1,892 | 17,632 | 92,834 | 0.28% | Play Counts | 0 | |
| zhihuRec 1M | 7963 | 81,214 | 1,000,026 | 0.155% | Views | 26 | 17 |
| zhihuRec 20M | 159,878 | 342,736 | 19,999,502 | 0.0365% | Views | ||
| zhihuRec 100M | 798,086 | 554,976 | 99,978,523 | 0.0226% | Views | 17 | |
| RetailRocket | 1,407,580 | 235,061 | 2,756,101 | 0.00083% | {View,Addtocart,Transaction} | 0 | 2 |
| Yoochoose | 509,696 (sessions) | 19,949 | 34,154,697 | 0.336% | {Buys, Clicks} | 0 | 0 |
| Coat | 290 | 300 | 11,600 | 13.33% | Rating: [1-5] | 0 | 0 |
| Yahoo! R3 | 15,400 | 1,000 | 365,704 | 2.37% | Rating: [1-5] | 0 | 0 |
| Yahoo! R6A | Anonymous | 271 | 45,811,883 | Clicks | 6 | 6 | |
| Yahoo! R6B | Anonymous | 652 | 27,777,695 | Clicks | 136 | 0 | |
| Open Bandit Dataset | Anonymous | 80 | 26,703,169 | Clicks | 4 | 4 | |
| KuaiRec | 1,411 | 3,327 | 4,676,570 | 99.6% | view time | 31 | 57 |
而我们首次提出了一个几乎全曝光的推荐数据集:KuaiRec,见下图:
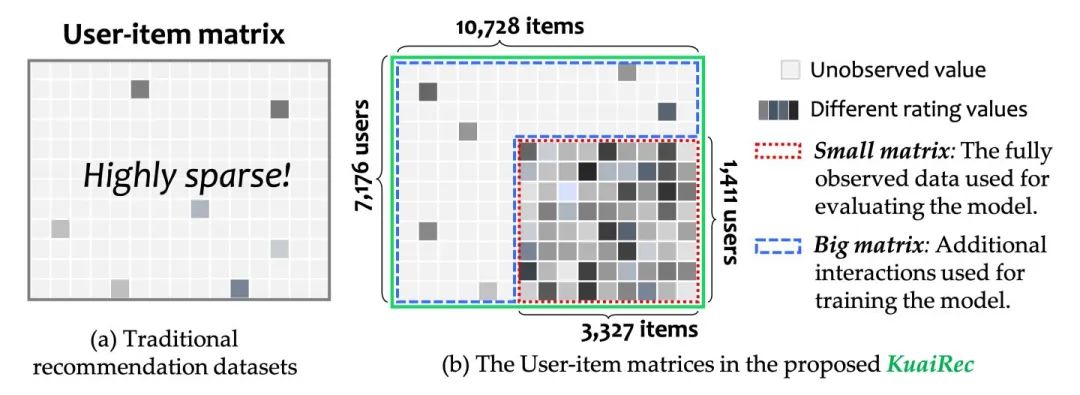
这个全曝光的小矩阵,可以成为一个绝佳的推荐系统的评测数据,即对于任意用户,其在任意商品上的偏好都已知。
而红色小矩阵外围的蓝色部分,则是我们收集作为训练用途的数据,取名为大矩阵。
这个全曝光矩阵,在推荐系统领域,是首个!
KuaiRec 2.0版本比起1.0版本多了什么?
这次的2.0版本比起1.0区别不大,主要在于:
-
加入了大量的用户侧以及视频侧特征。
-
用户侧:30个特征,包括12个显示特征和18个加密过的one-hot特征。 -
视频侧:加入了56个特征,其中45个是每天的统计特征。
-
去除了原来没用到的ID为1225号的视频,并将原先ID大于1225的视频的ID减一。
我们怎么收集的这个数据集?
短视频推荐不同于商品推荐,用户交互相对密集得多。利用这一特性,我们首先找到了一批高质量的短视频,在喜欢看这一批高质量短视频的用户群中筛选出了一批人群。当然,筛选出的人群也并不能将所有短视频都看完,此时矩阵密集程度大概在70%多。剩下不到30%的交互依然未知。接下来就简单了,我们更改这部分用户的推荐系统规则,将他们没看过的视频插入到推荐流中,在用户不知情的情况下收集他们的反馈。于是,在两周的曝光后,我们再次对用户进行筛选,得到了最终看完所有视频的用户集合。
这个过程得到的数据会不会有问题?当然!没有免费的午餐。这样筛选后也会引入部分的bias。但用户的反馈是真切记录下来了。我们也对这部分数据与快手平台的大数据进行了比较,在一些关键指标上,通过了双样本Kolmogorov–Smirnov假设检验,即我们的全曝光数据与快手平台的大数据在这些指标上分布是一样的。故,这可以当成真实在线数据的缩影。
数据官网中有这个数据集的各种统计信息,这个数据中发现任何问题,都能够支撑做一些debiasing研究的方向。总之,这个数据集可以挖掘的信息很多,机会很多。
KuaiRec数据集可以用来做什么?
由于包含全曝光用户—商品矩阵以及大量的特征,其可以支撑大多数推荐系统方向中的研究。全曝光矩阵最大的用处:评测!评测!
在基于bandit的推荐方式中,以及强化学习的方法研究中,最头疼的问题,就是没有ground-truth信息:即,模型现在推荐或者选择了一个商品,我们不知道用户对其的偏好(稀疏的历史数据中没有),那就没法评测!这类技术就没法用了。于是我们在看到bandit方法、强化学习方法的文章中,用的数据集总是人工模拟数据,或者公司内部数据。而此时此刻,一个真正记录了用户偏好的全曝光数据,就摆在眼前。再也不需要用人工模拟了。
为什么需要全曝光数据?
以前没有全曝光数据,评测推荐系统的方式就是划分出一部分数据作为测试集,在该测试集上用基于例如Precision、Recall等的指标进行评测。这种方式很普遍。
然而!这是有问题的评测方式!而且问题不小。在推荐中,传统离线评测方式,是对于稀疏数据的一种妥协。
更多推荐系统内容可移步作者主页:https://chongminggao.me/
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



