只需要几行代码,Cleanlab 就能帮你纠正数据集中的错误。
从事 AI 研究工作的人都知道,数据准备几乎占据了数据科学和机器学习研究工作的 80%。它被认为是最耗时和最不愉快的数据科学任务。
你以为的研究工作是「花时间从数据、训练模型、高级建模技术中探索出很棒的见解」,实际上经常是「把大量时间花在清理数据上」,因为现实世界的数据是杂乱无章的,而且充满错误……
![]()
数据错误(例如训练集中的错误标记示例)会降低模型性能,数据集级别的问题(如重叠类)也会降低模型性能。即使在 gold-standard 基准数据集中,测试集错误也很常见,这可能会误导数据科学家选择劣质模型进行部署。虽然探索复杂的建模技术听起来比手动检查和清理单个数据点更有吸引力,但往往是后者提供了更大的收益。
为了帮助数据集纠错效率的提升,来自 MIT、亚马逊的研究者创造了数据标注纠错工具 Cleanlab。Cleanlab 通过仅自动标记真正需要注意的一小部分数据来减少此过程中的痛苦。
![]()
![]()
论文链接:https://arxiv.org/abs/2103.14749
在这篇文章中,三人对 10 个主流机器学习数据集的测试集展开了研究,发现它们的平均错误率竟高达 3.4%。其中,最有名的 ImageNet 数据集的验证集中至少存在 2916 个错误,错误率为 6%;QuickDraw 数据集中至少存在 500 万个错误,错误率为 10%。
既然数据标注错误如此普遍,但又十分重要,那 cleanlab 是怎么解决这个问题的呢?
Cleanlab 通过提供一个框架来简化以数据为中心的 AI ,帮助数据科学家和 ML 工程师完成 80% 的工作。Cleanlab 通过查找和修复示例级、类级和数据集级问题,支持机器学习和分析工作流,处理混乱的现实世界数据;测量和跟踪整体数据集质量;并为机器学习管道提供清洁数据。
「Cleanlab 背后的算法理论受到了量子信息理论的启发,当时我们的 CEO 正在麻省理工学院进行博士研究。我们的一些用户认为 Cleanlab 是黑魔法,但它大部分是发表在顶级 ML/AI 会议和期刊上的数学和科学研究。」
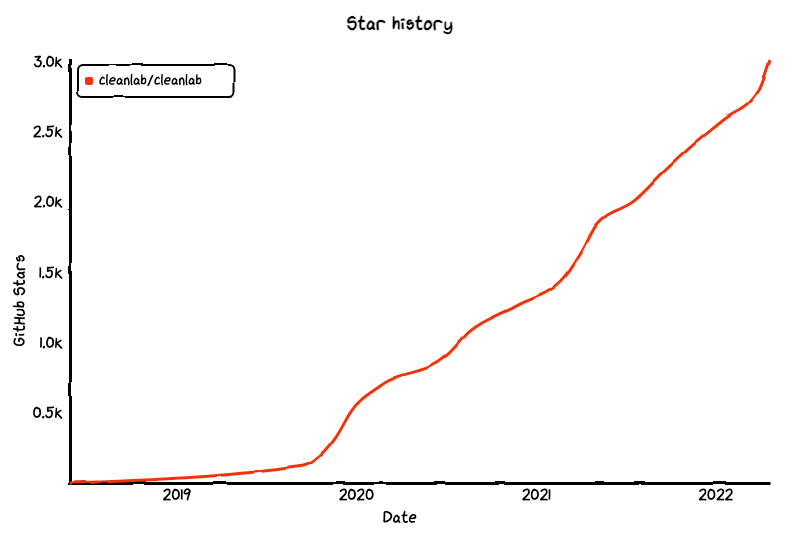
2021 年底,Cleanlab 公司成立。在过去的一年里,数十家科技、医疗保健、金融和数据相关的公司(例如特斯拉、摩根大通、Chase、富国银行、微软等)已经开始使用 cleanlab。迄今,这个项目已经累积了 3k Star:
![]()
近日,Cleanlab 正式发布了 2.0 版本,以适用于所有数据科学家、ML 数据集和模型。
![]()
cleanlab 2.0 是一个开源框架,用于机器学习和分析杂乱的真实数据。基于 MIT 的研究,cleanlab 可以识别数据集中的错误,测量数据集质量,用噪声数据训练可靠模型,并帮助管理高质量的数据集,每一个都只需要几行代码。
项目地址:https://github.com/cleanlab/cleanlab
![]()
Cleanlab 2.0 版本中开源的新特性示例(大部分是一行代码)包括:
在数据集中查找问题并按质量对数据点进行排名
在有标签问题的任何数据集上训练任何分类器
在数据集级别查找要合并和 / 或删除的重叠类
衡量数据集的整体标签健康状况
基本只需要一行代码,即可找出数据集中的哪些示例存在问题:
from cleanlab.classification import CleanLearningissues = CleanLearning(yourFavoriteModel).find_label_issues(data, labels)
from cleanlab.dataset import overall_label_health_scorehealth = overall_label_health_score(labels, pred_probs)
此外,cleanlab 的所有功能都适用于任何数据集和任何模型,包括 scikit-learn、PyTorch、Tensorflow、Keras、JAX、HuggingFace、MXNet、XGBoost 等。如果你使用与 sklearn 兼容的分类器,cleanlab 可以开箱即用。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com