KuaiRec | 快手发布首个稠密度高达99%的推荐数据集, 可用于多种推荐系统方向研究
本周跟大家分享一篇快手公司与中科大合作产出的资源型论文,即发布了一个几乎全是观测值的稠密数据集KuaiRec,该数据集包含了1411个用户对3327个短视频的交互行为,稠密度高达99.6%(一般推荐系统公开数据集的稠密度在1%以下)。该数据集可用于离线的A/B测试,以及可用于无偏推荐、交互式/对话推荐或者是基于强化学习推荐等方向。

论文:https://arxiv.org/abs/2202.10842
数据:https://rec.ustc.edu.cn/share/598635c0-9585-11ec-8259-414ede1f8d4f
代码:http://m6z.cn/5U6xyQ
目前大多数离线评测的推荐系统数据集会存在高度数据稀疏(Highly sparse)与包含多种偏置(Various bias)的问题,因此会严重影响推荐算法的评测性能(关于目前主流推荐系统45种公开数据集的统计分析可阅读WSDM2022 | 数据困境: 我们究竟有多了解推荐系统数据集?)。目前主要的缓解方式是通过随机选择交互物品的方式来收集用户偏好以此来提高数据的质量,比如Yahoo数据集与Coat数据集。然而这些数据集会由于数据稀疏而导致高度偏差的问题,为从根本上缓解以上问题,所以提出了一个全量观测数据集KuaiRec,该数据集是从快手短视频社交分享平台上收集的,是第一个稠密度高度99%的数据集。
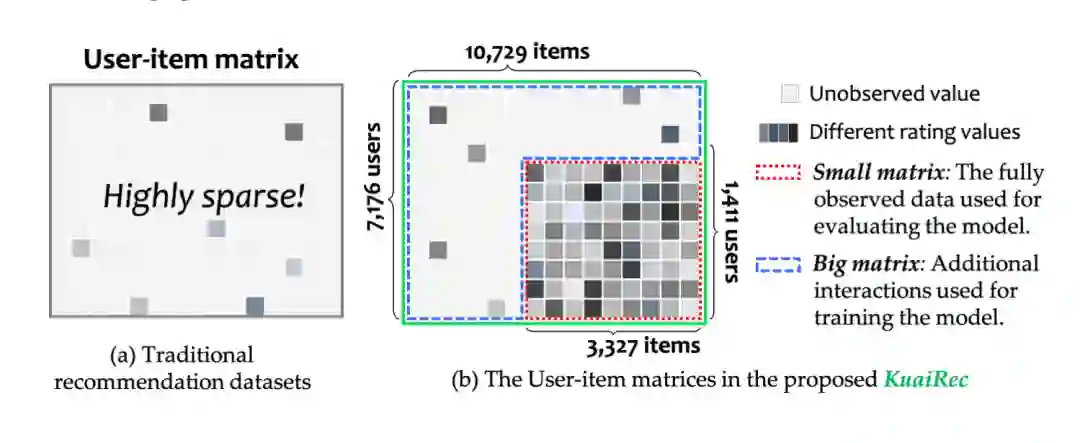
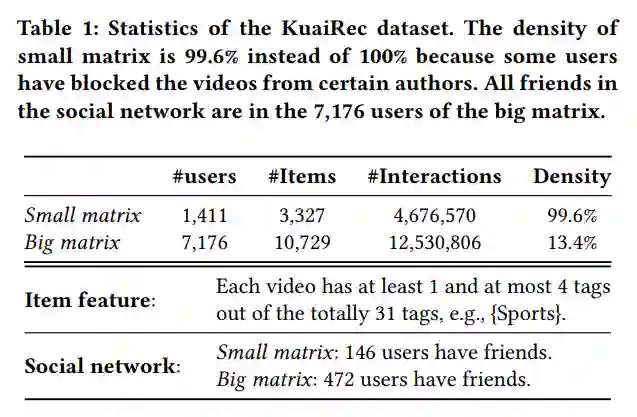
对于该数据集的统计信息可见下表,其中Big matrix还包含丰富的边信息,即用户侧的社交网络与物品侧的特征信息。
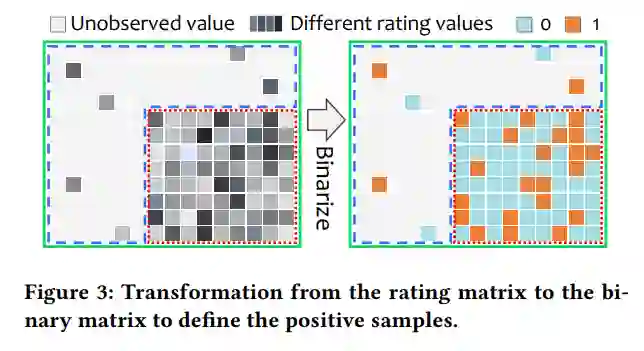
另外,通过从Small matrix中抽取部分用户-商品交互(Partially dataset)作为测试集来进行与全量观测数据(Fully-observed dataset)的实验对比,来评估数据稠密度(Data density)与偏置(Bias)的影响。通过在KuaiRec数据集上的实验结果提供了两个关键的发现,这些发现正好说明了全量观测数据集的重要性:
2. 不同的数据稠密度仍然会导致结果不一致。
最后,作者希望可以把该数据集作为一个测试平台来支持更多的研究工作。首先,可以使用Partially observed data来构建可信的用户模拟器。虽然在实验中验证了在矩阵填充任务上的帮助有限,但是否可以使用部分观测数据正确模拟完全观测数据仍然是一个悬而未决的问题。我们充分观察到的数据可以进一步支持这种探索。第二,Small trix版本的数据集可以作为推荐系统中多个研究方向的基准数据集,例如推荐系统中的偏差、交互式推荐和评估。至少通过发布这些全量观察到的数据,希望鼓励更多的科研人员努力收集具有更丰富属性的更完全的数据集,以此来促进推荐系统社区的发展。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。




