

分享嘉宾:杨韬 腾讯 专家研究员 编辑整理:付琰 百度 出品平台:DataFunTalk
**导读:**今天给大家介绍微信搜一搜中的智能问答技术。 围绕下面四点展开: * 背景介绍 * 基于图谱的问答 * 基于文档的问答 * 未来展望
01****背景介绍
** 1. 从搜索到问答**
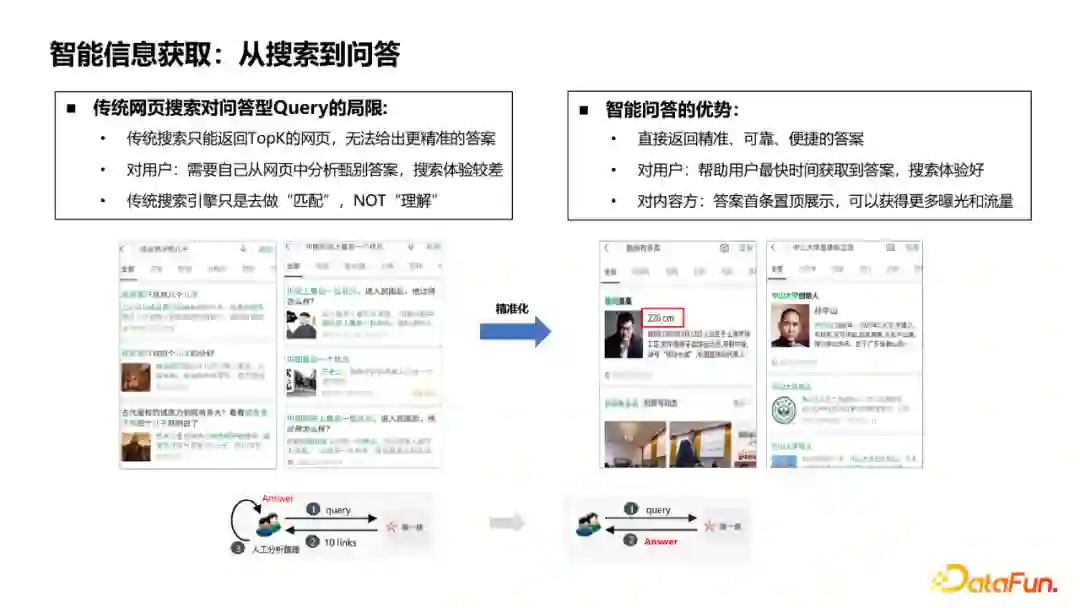
搜索引擎是人们获取信息的重要途径,其中包含了很多问答型的query。但传统的搜索只能返回TopK的网页,需要用户自己从网页中分析甄别答案,体验较差。原因是传统搜索引擎只是对query和doc做“匹配”,并不是真正细粒度地理解query。智能问答正好可以弥补这个局限,它的优势在于能够更好地分析query,直接返回精准、可靠的答案。
2. 搜索场景下的常见用户问答需求
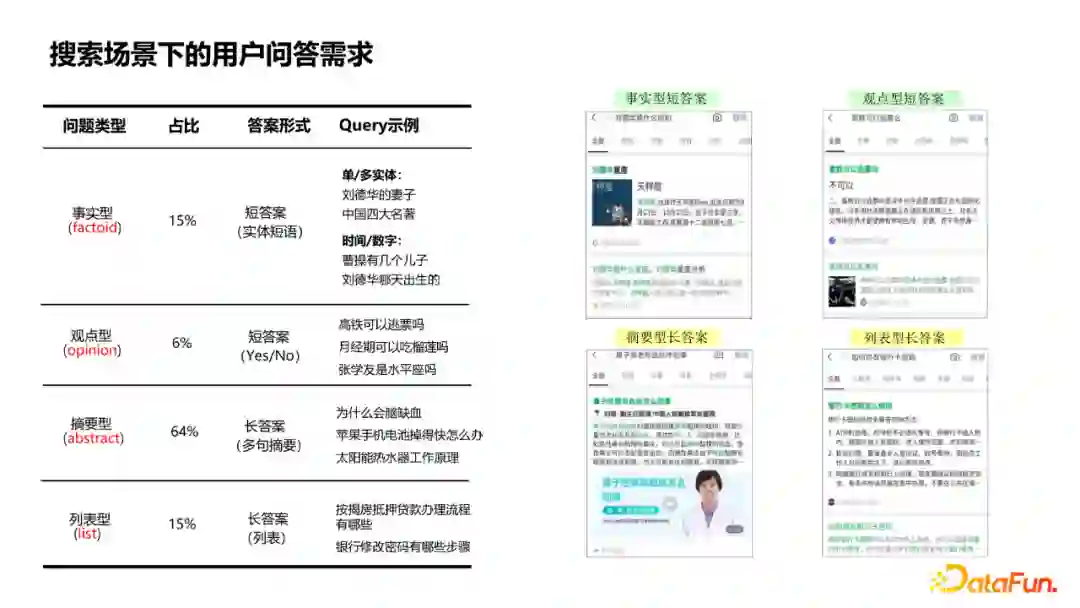
基于图谱的问答事实型query,答案形式是实体短语类的短答案。例如“刘德华的妻子”,或者实体集合“中国四大名著”,还有时间/数字等。 * 第二类是观点型query,答案形式是“是或否”,例如像“高铁可以逃票吗”等。 * 第三类是摘要型query,不同于前两类短答案,答案可能需要用长句的摘要来回答,通常是“为什么”、“怎么办”、“怎么做”等问题。 * 最后一类是列表型query,通常是流程、步骤相关的问题,答案需要用列表做精确的回答。
3. 答案知识来源

结构化数据**,来源于百科、豆瓣等垂类网站的infobox**。优点是质量高,便于获取和加工;缺点是只覆盖头部知识,覆盖率不够。例如“易建联的身高”、“无间道1的导演是谁”。 * 非结构化的通用文本**,来源于百科、公众号等互联网网页文本库**。优点是覆盖面广,但缺点在于文本质量参差不齐,对医疗、法律等专业领域知识的覆盖度和权威度不够。 * 非结构化的专业垂类网站问答库,来源于专业领域垂类站点的问答数据,通常以问答对的形式存在。优点是在专业领域知识覆盖广、权威度高。
4. 智能问答的技术路线
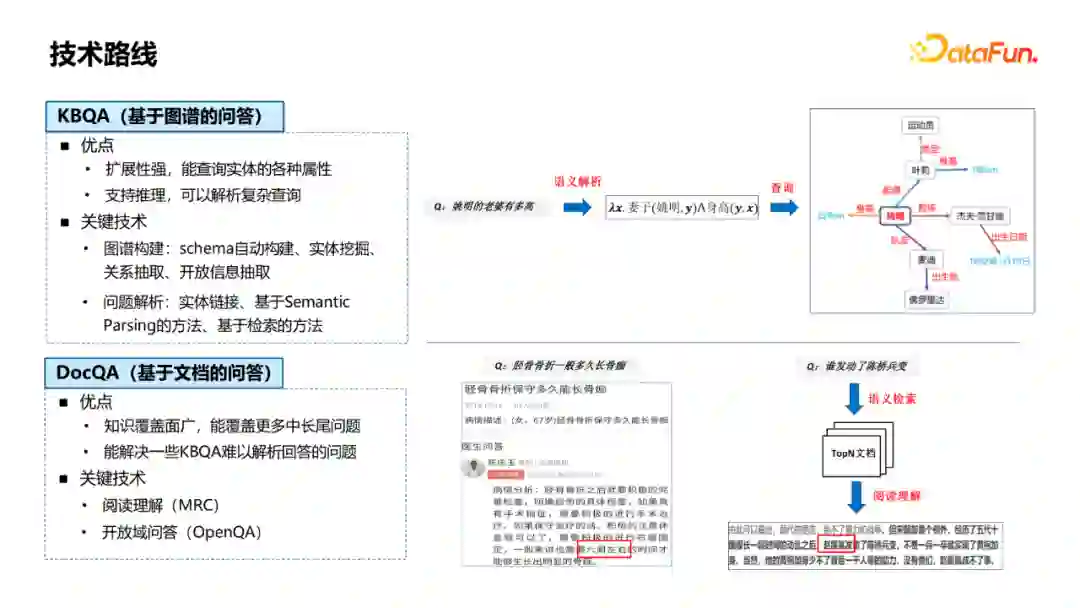
支持智能问答的技术路线主要分两种:KBQA(基于图谱的问答)和DocQA(基于文档的问答)。 * KBQA的优点是扩展性强,能查询实体的各种属性,同时支持推理,可以解析复杂查询。例如图中右边的一个例子,“姚明的老婆有多高”可以解析得到中间的语义表达式,从而转换成知识图谱的查询,得到问题的答案。涉及的关键技术是图谱构建(包括schema构建、实体挖掘、关系抽取、开放信息抽取技术)和问题解析(包括实体链接、基于semantic parsing的问题解析方法、基于检索的问题解析方法等技术)。 * DocQA相较于KBQA的优点是覆盖面更广,能覆盖更多中长尾的问题,同时能解决一些KBQA难以解析的问题。例如,“中国历史上第一个不平等条约”这个query,很难解析成结构化的表达,涉及到的技术主要包括阅读理解(MRC)、开放域问答(OpenQA)。
02
基于图谱的问答
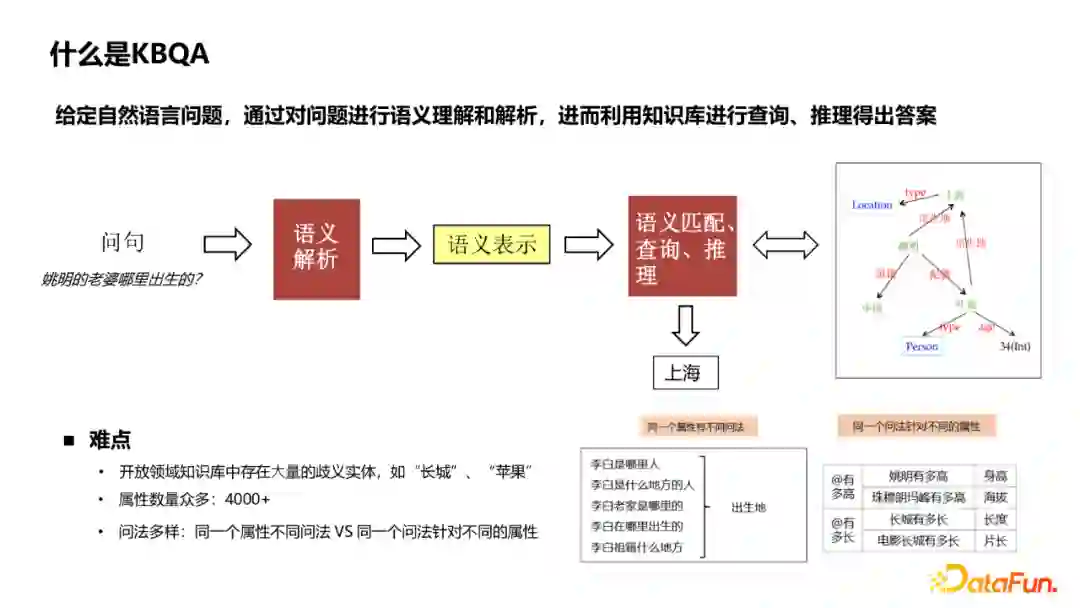
KBQA的定义:给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。面临的难点主要有以下几点: * 开放领域知识库中存在大量的歧义实体,例如“长城”、“苹果”,可能在知识库中存在多种类型的同名实体。从query中识别出正确的实体是整个KBQA中一个比较关键的模块。 * 开放域的知识图谱属性众多,需要从4000+属性中识别出正确的属性。 * 自然语言的问法多样,同一个属性有不同问法,例如询问李白的出生地,可以有“李白是哪里人”、“李白老家是哪里的”等多种不同的表达。同一个问法也可能针对不同的属性,例如“姚明有多高”、“珠穆朗玛峰有多高”,同样是“有多高”,但询问属性分别是身高和海拔。
1. KBQA技术方案

方案一:检索式的方法。把query和候选答案(知识图谱中的候选节点)表征为向量计算相似度。优点是可以进行端到端的训练,但可解释性和可扩展性差,难以处理限定、聚合等复杂类型的query。 * 方案二:基于解析的方法。把query解析成可查询的结构化表示,然后去知识图谱中查询。这种方法的优点是可解释性强,符合人能理解的图谱显示推理过程,但依赖高质量的解析算法。综合考虑优缺点,我们在实际工作中主要采用的是这种方法。
2. KBQA整体流程
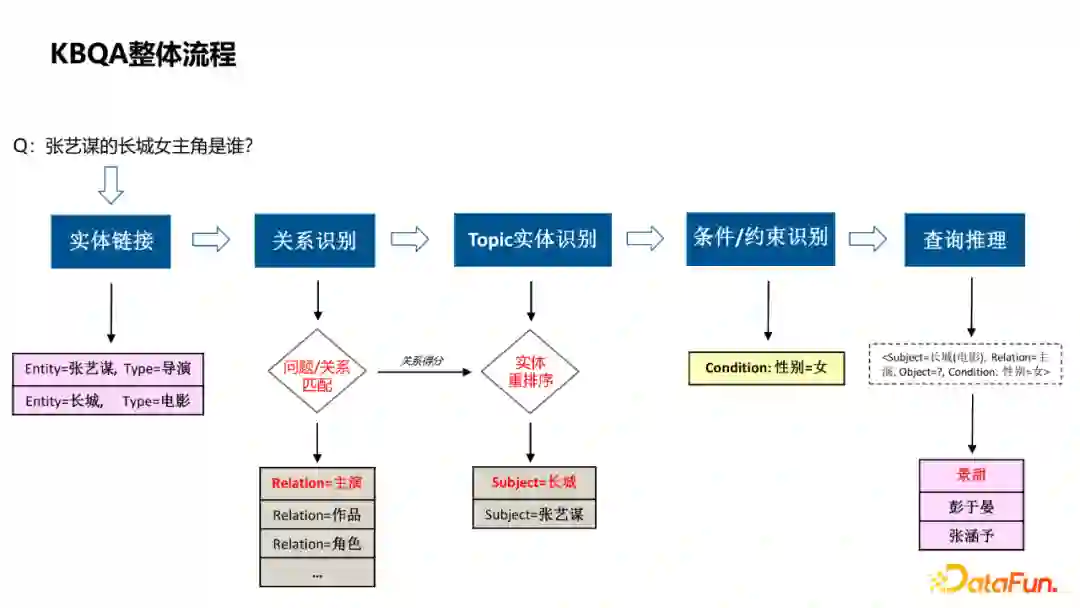
首先以一个例子介绍KBQA的整体流程: * 实体链接,识别出query中的实体,并关联到图谱中的节点; * 关系识别,query询问的具体属性; * Topic实体识别,当query涉及到多个实体时,判断哪个实体是问题的主实体; * 条件/约束识别,解析query中涉及到的一些约束条件; * 查询推理,将前几步的结果组合成查询推理的语句,通过知识图谱获得答案。
在整个流程中,比较关键的是实体链接和关系识别这两个模块,下面对这两个模块做重点介绍。
3. KBQA-实体链接
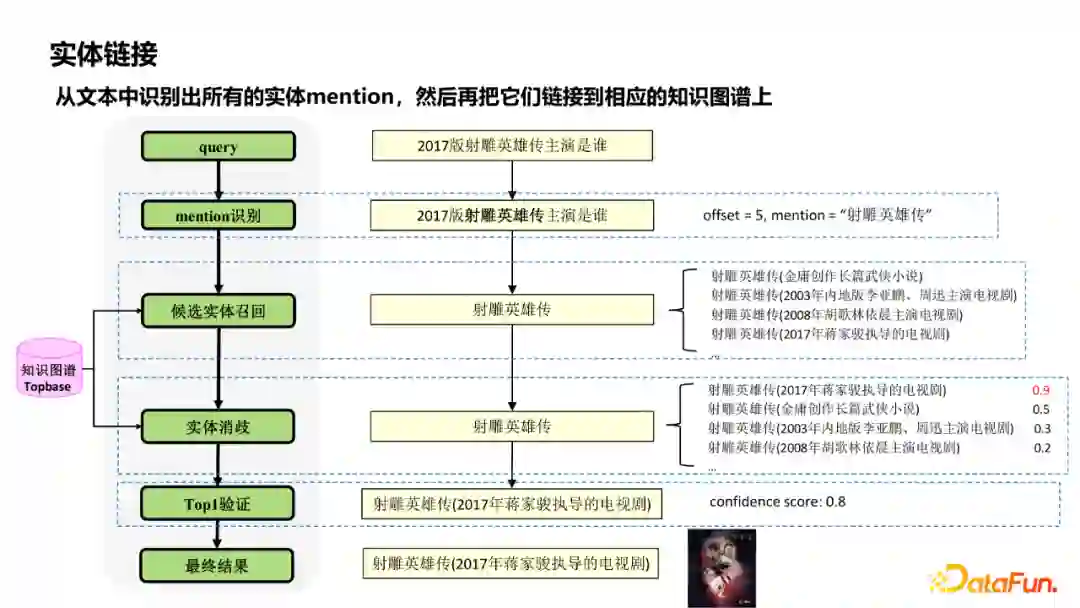
实体链接,从文本中识别出所有的实体mention,然后再把他们链接到对应的知识图谱上。这里展示了一个实体链接的例子。 首先通过NER、SpanNER等方法,对query进行mention识别;根据识别出的mention,在知识图谱中召回候选多个实体,并进行实体消歧,本质上也就是对召回实体的排序打分。有时由于知识图谱数据不全,库中根本不存在对应的实体,因此通常会有一步“Top1验证”,即对排序后的top1结果再进行一次打分,确定top1结果是否是最终的实体。
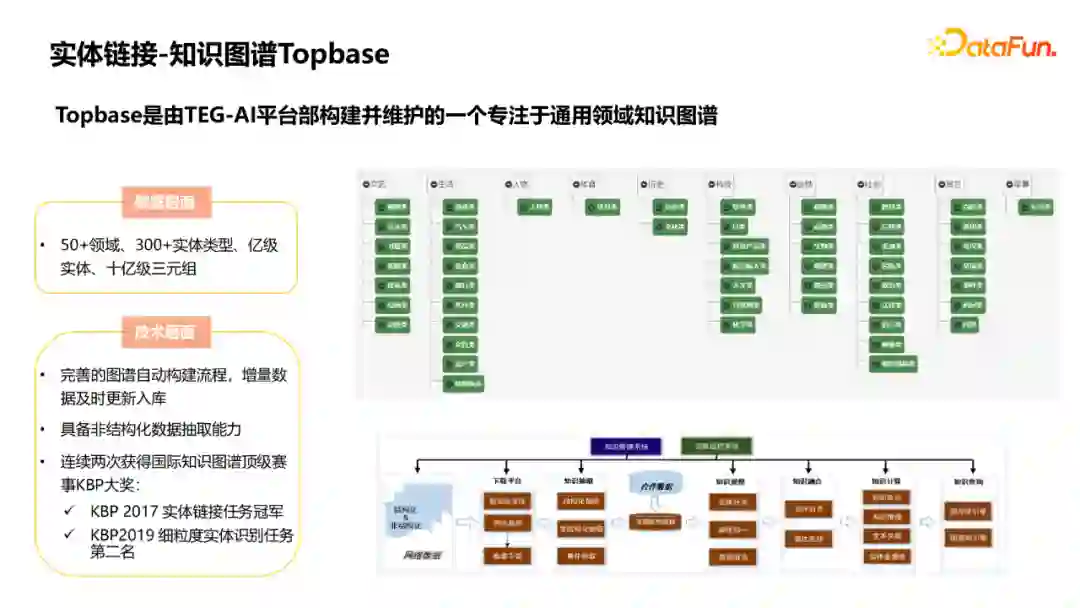
这里简单介绍一下我们在工作中用到的一个知识图谱——TopBase。它是由TEG-AI平台部构建并维护的一个专注于通用领域的知识图谱。在数据层面有五十多个领域,三百多个实体类型,亿级实体和十亿级三元组。对这个图谱我们做了一个比较完善的自动化的构建流程,包括下载、抽取、去噪、融合、计算和索引步骤。由于结构化的InfoBox数据可能是不全的,我们也构建了一个非结构化数据的抽取平台。
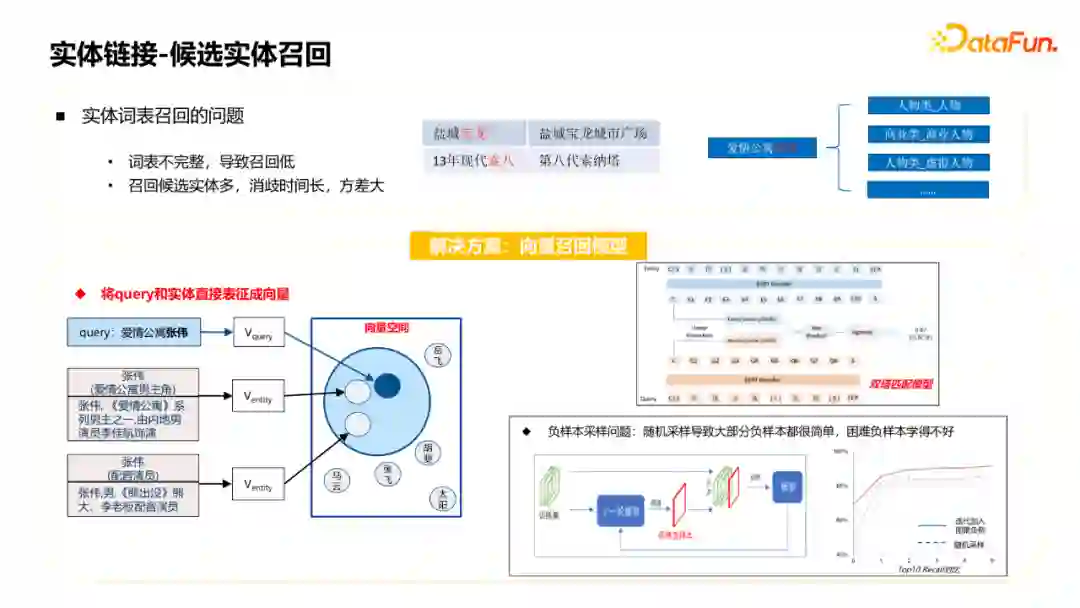
接下来介绍候选实体召回模块。传统的做法一般是用实体词表,把知识图谱中所有实体的原名和别名做成一个词表,在召回时用mention做词表召回。一般会有两个问题: ①词表不完整导致召回率较低,比如图中的宝龙和索八,如果没有挖掘出别名就无法召回。 ②有些实体mention召回的实体较多,会导致后面消歧模块的耗时比较长,比如图中的张伟,在知识库中可能有几十上百个不同类型的人物。
针对这两个问题,主要采用的是基于向量召回的解决方案:将Query和实体分别表征成向量,然后计算相似度。匹配模型是一个双塔模型,训练数据是Query和它对应的实体mention。对于候选实体会用到名字、描述信息和简介做为模型输入,通过这个模型进行匹配做召回。 在训练过程中存在一个问题,这个任务中负例很多,如果直接采用随机采样的方式,会导致大部分负例比较简单,使得困难负例学得不好。采用的解决方案是:用上一轮的模型获得query的候选实体当做负例,和当前的训练集融合到一起训练模型,不断迭代这个流程。这样做的好处是,在迭代训练的过程中,每一轮都会加入困难的负例,让困难负例学得更好。从表格里可以看到这样的训练效果更好。
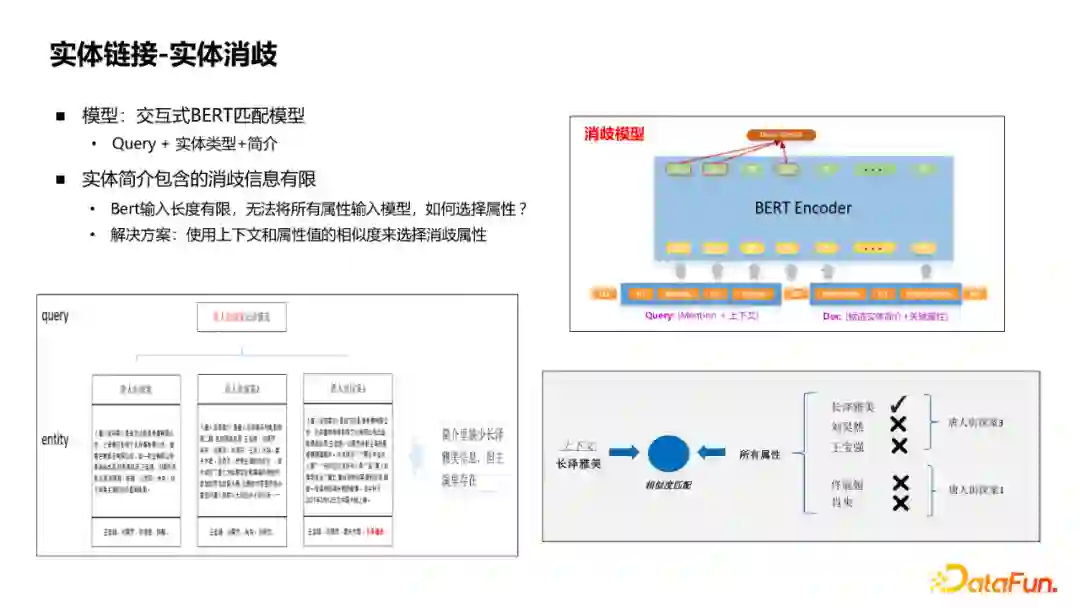
在召回实体后,下一个流程是实体消歧,采用的模型是交互式BERT匹配模型,将Query和实体的简介、描述信息拼接在一起打分。但是对实体的描述只有简介信息是不够的,例如在《唐人街探案》中,“长泽雅美”没有出现在简介里,只在演员属性里。因此,更重要的是将实体的属性值也加入到消歧的模型里。但实体的属性值量非常大,不可能全部加入,采用的方案是对属性进行粗召回,用query与实体的属性值做轻量级的相似度计算,例如词袋、word2vec的向量选出TopK等方法,拼接到这里做消歧。
4. KBQA-关系识别
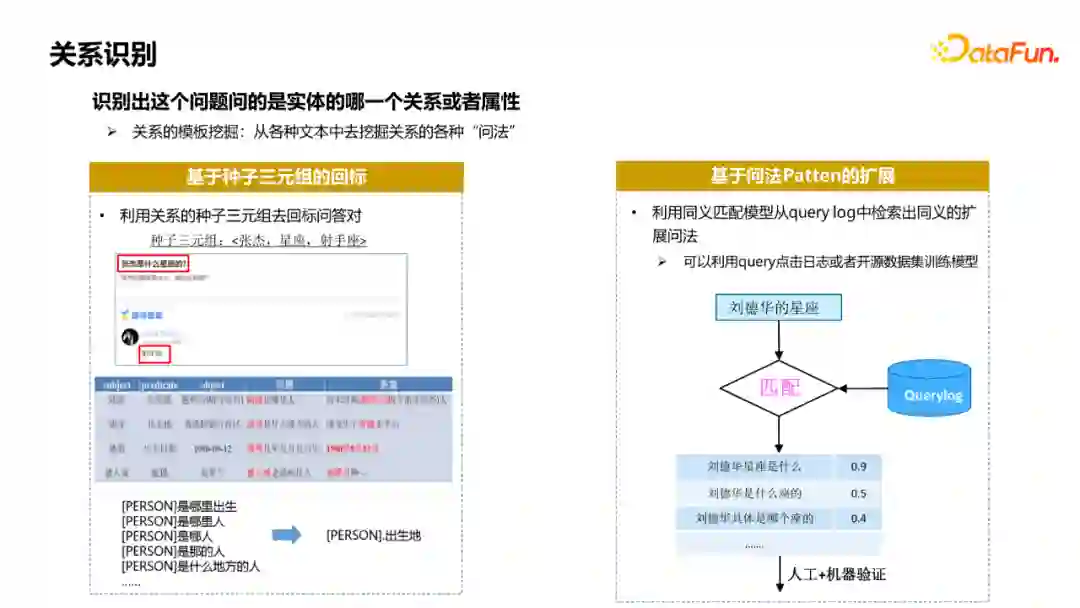
关系识别是识别出这个问题问的是实体的哪一个关系或属性,要完成这个任务,不管是基于规则策略的方法还是基于模型的方法,首先要做的是挖关系的模板库,常用的方法: ① 基于种子三元组的回标,这是一个比较经典的方法。从知识图谱中找到属性和关系的一些常见的三元组,去回标这种问答对,像问题匹配到主语,段落答案匹配到宾语,就有理由认为这个问题是在问这个属性。在匹配一些数据之后,可以通过策略或者人工的方式,为每种关系或属性挖掘出模板。 ② 对于有种子问法的属性**,可以采用基于问法pattern扩展的方式**:利用同义匹配模型从query log中检索出同义的扩展问法,可以利用query点击日志或者开源数据集训练模型,当有一个属性的种子问法后,用这个模型去匹配query log得到数据,结合人工或机器的验证来获得扩展问法。
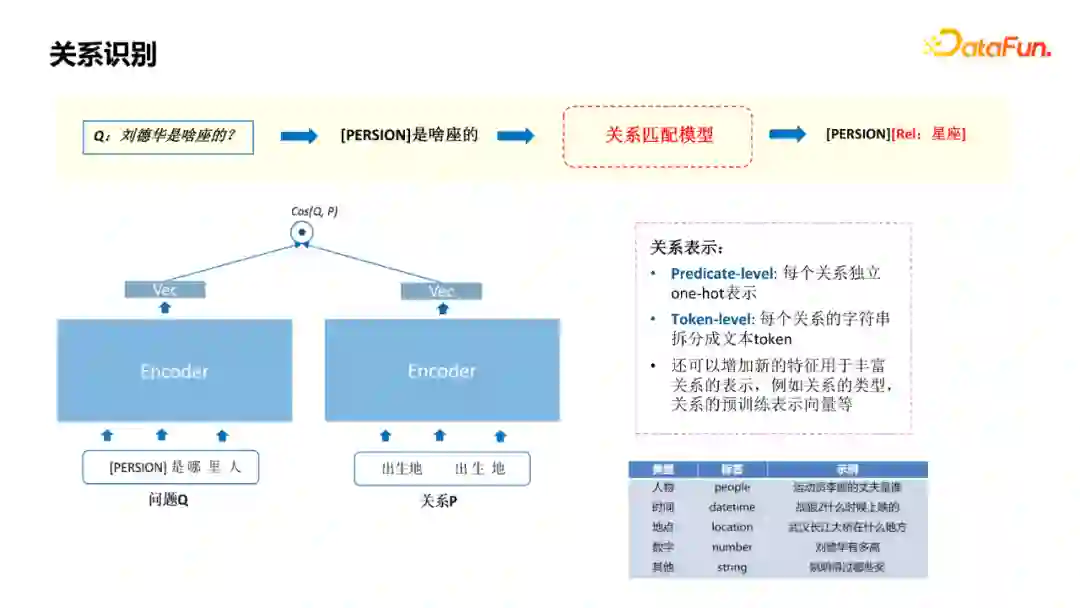
刚才介绍了模板库的构建,我们的模型也是基于匹配的模型。如图左边把识别出的mention用它的type去替代,通过Encoder得到向量;如图右边,是对关系的encode。关系的表示有两部分,第一部分是对每个关系独立one-hot表示,第二部分是将每个关系的字符串拆分成文本token。这个模型还有一个好处是可以增加一些新的特征,用于丰富关系的表示,如图右边这一部分。比如关系的宾语类型,还有预训练表示向量,可以进一步提升模型的训练效果。
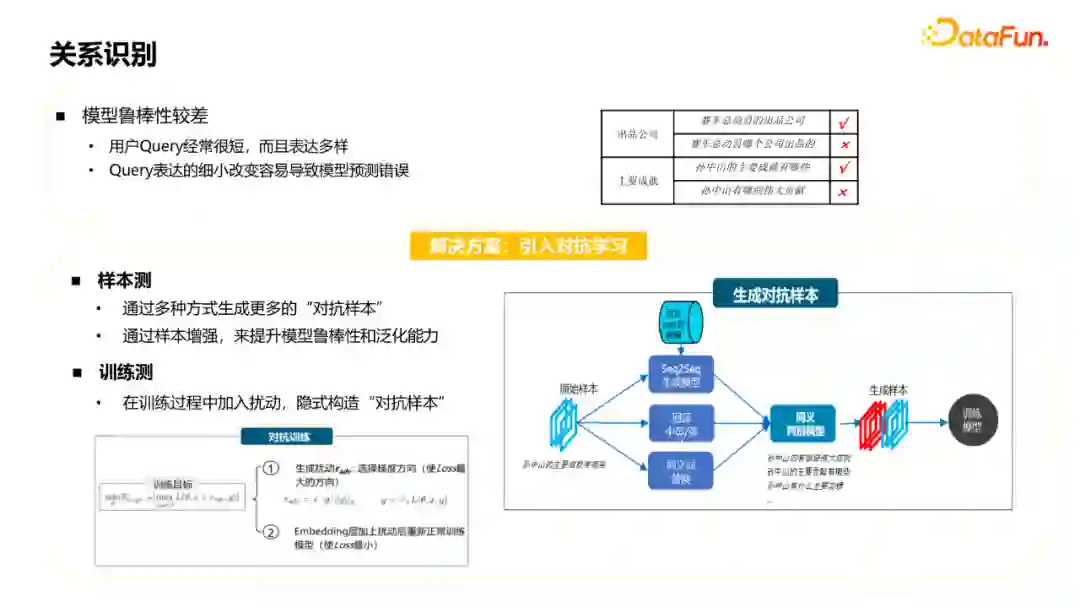
在做关系模型的过程中经常会遇到鲁棒性较差的问题,原因如下: ① 用户Query经常很短,而且表达多样。 ② Query表达的细小改变很容易导致模型预测错误。 对于这个问题可以采用的解决方案是引入对抗学习,主要用在样本侧和训练侧。 在样本侧可以通过多种方式生成更多的“对抗样本”,通过样本增强来提升模型鲁棒性和泛化能力。如图对于原始样本,可以通过seq2seq、回译或者同义词替换的方式去生成扩展的对抗样本,但生成的样本中可能有一些并不是同义的,而是噪声,这可以用一个同义的模型或策略来判别。最后将生成的样本和原始样本合并在一起训练,提升模型的鲁棒性。 在训练侧,可以在训练过程中加入扰动,采用对抗学习的方式,隐式构造“对抗样本”。对抗训练一般就是两个步骤,第一是生成扰动:选择梯度方向(使loss最大的方向);第二是Embedding层加上扰动后重新正常训练模型(使loss最小)。
5. KBQA-复杂查询解析

大家通常搜的都是一些简单Query,但也有一部分复杂Query,刚才介绍的关系识别模型是比较难处理复杂Query的。图中列举了一些复杂Query的例子,多跳、多限定、序数、是否和计数问题都是用户常搜的复杂Query类型。 这些Query涉及到的关系可能是多个,而且涉及到的实体也是多个。所以用刚才的关系识别模型是难以处理这种情况的。由于是多关系、多实体,可以将其表示为一个图,这里介绍几个查询图,通过这种方式,将刚才的简单单实体、单跳的问答扩展成Query Graph的结构,我们希望用这样一个更复杂的图结构来解析更复杂的Query。
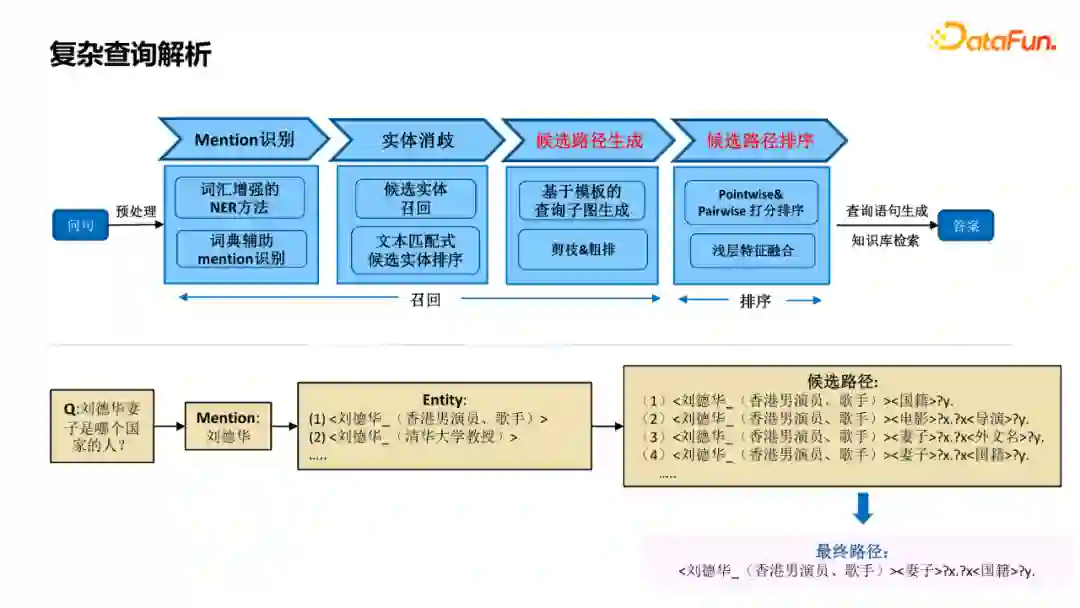
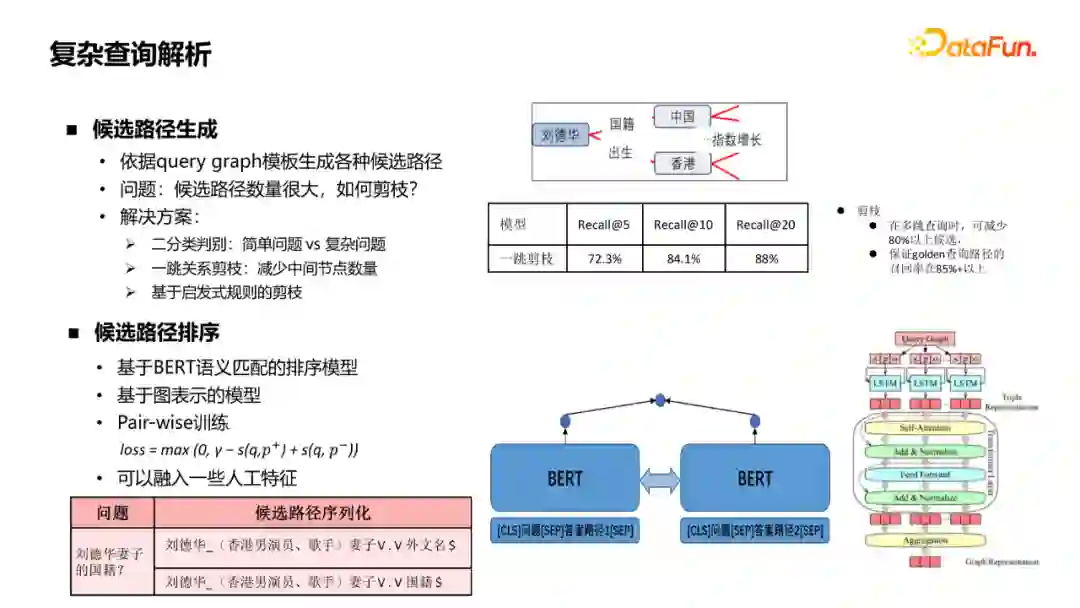
对复杂查询有两个关键的模块,一个是候选路径生成,依据query graph模板生成各种候选路径,但生成的路径数量非常大,几种常见的剪枝方案: * 二分类判别:简单问题还是复杂问题 * 一跳关系剪枝:减少中间节点数量 * 基于启发式规则剪枝
通过这些方法,在保证一定召回率的基础上,候选可以减少百分之八九十。 对于候选路径排序一般有两种方案:
① 基于BERT语义匹配的排序模型。BERT需要输入一个句子,因此首先将查询图序列化成一段文本,再和问题拼接一起去搜,得到匹配分,再基于pair-wise的方法训练。这种方法的不足是,将查询图进行了序列化,没有更好地利用图的结构化信息。 ② 基于图表示的模型。Query Graph是一些三元组组成的,分别去encode这些三元组,得到encode向量,通过Transformer层去做他们之间的交互,最后将它们aggregation起来得到候选查询图的表征。这种方法要比之间序列化的方法要好。 除了这些深度语义的话,也可以融入一些相关的人工特征来进一步提升效果。
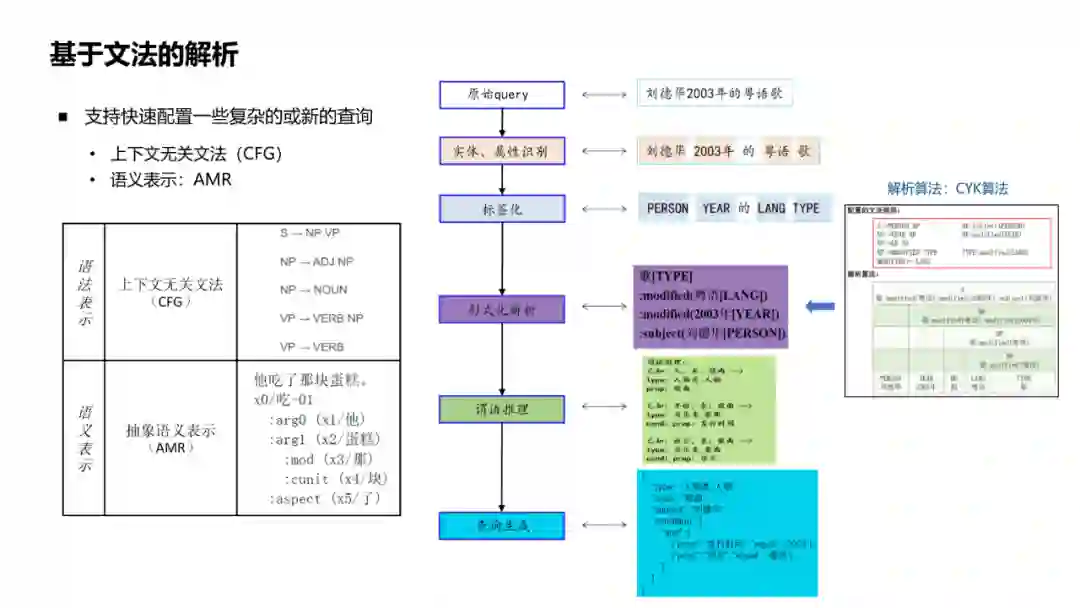
除了刚才介绍的方法,还有一类Query解析方法是基于文法的解析。支持快速配置,支持复杂的和新的查询。 采用的文法表示是上下文无关文法(CFG),语义表示用的是抽象语义表示(AMR)。 如图列举了一个简单的流程。对于一个Query,首先会去做实体和属性的识别,然后进行标签化,再通过标签依据配置的语法规则进行语法解析,例如CYK等经典算法,得到形式化表示。接下来还要推理相关谓语,就是一些属性关系,最终生成一个实际的查询。03****基于文档的问答

DocQA是指利用检索+机器阅读理解等技术,从开放文本库中抽取出用户问题的答案。主要面临了几个难点: ① 抽取的答案片段的准确性。 ② 对无答案段落的据识能力。很多时候段落中并不包含答案,所以要尽量避免从段落中抽取出一些错误的答案。 ③ 召回段落与问题的相关性。只有保证了相关性,后面的模型才能抽取出正确的答案。
1. DocQA总体流程
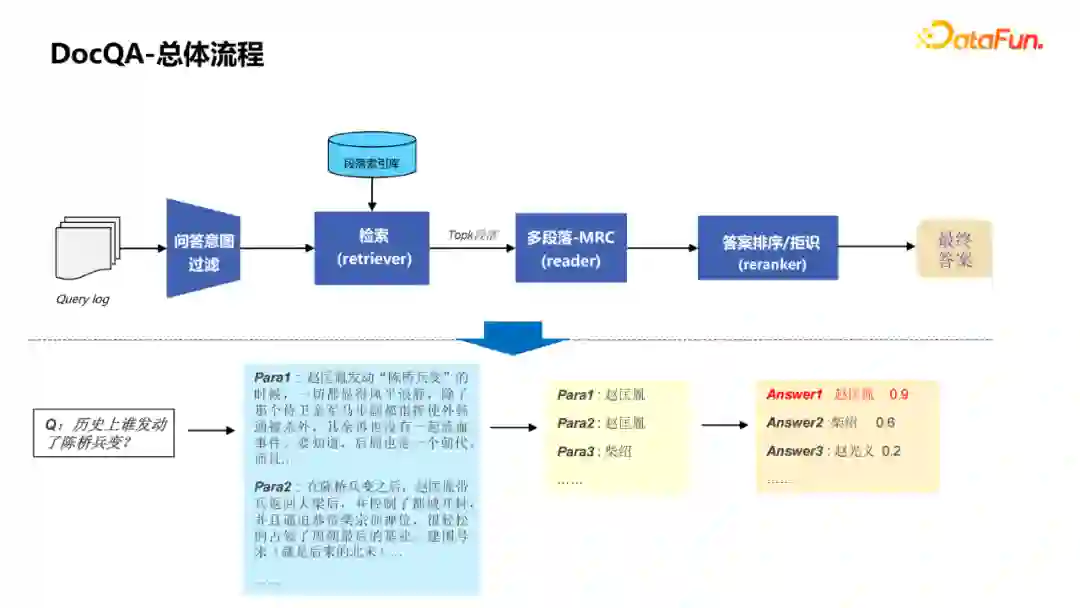
① 针对Query Log进行问答意图的过滤。 ② 通过检索模块去段落库中检索相应的一些段落。 ③ 对检索到的TopK段落,做一个Reader模型(多段落-MRC)。 ④ 对答案进行重排序和拒识判定。 ⑤ 输出最终答案。 可以看到全流程中比较重要的是检索模块和多段落的MRC模块。
2. DocQA-语义检索
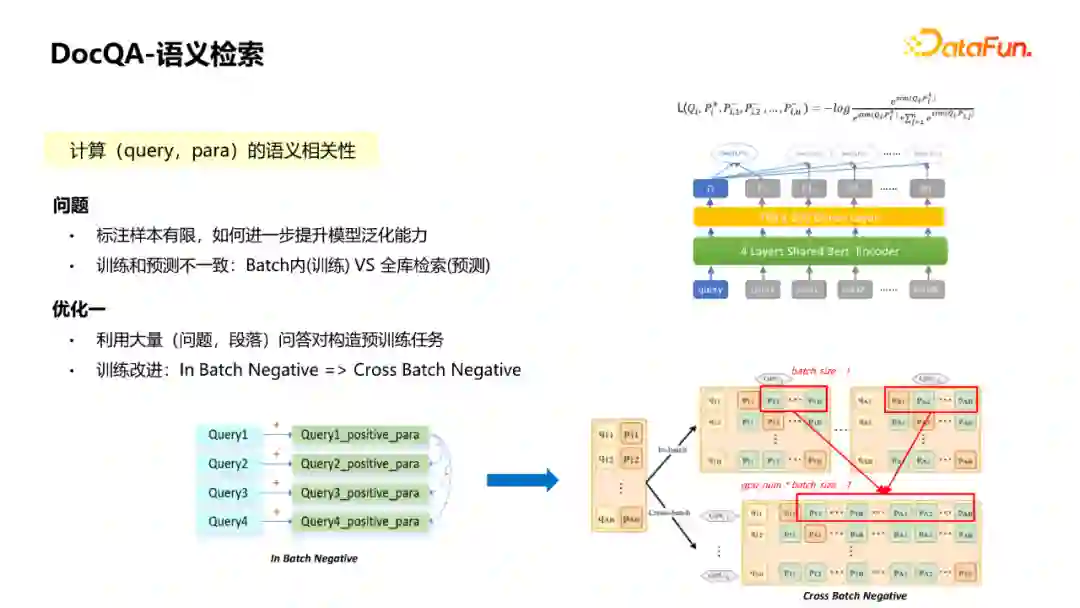
对于检索模块,常遇到的问题如下:
① 特定领域相关性标注样本有限,如何利用有限的标注进一步提升模型泛化能力。 ② 训练和预测的不一致问题:匹配模型在训练过程中,一般采用的都是In Batch Negative的方式,从Batch内的其他的Query对应的段落作为这个Query的负例,由于我们在预测过程中采用的是全库检索,可能整个库达到数百万或者数千万规模,会导致检索预测时的过召回问题,召回了很多错误的段落,这种方式会造成训练和预测的不一致问题。
针对这个问题有几种优化方案:
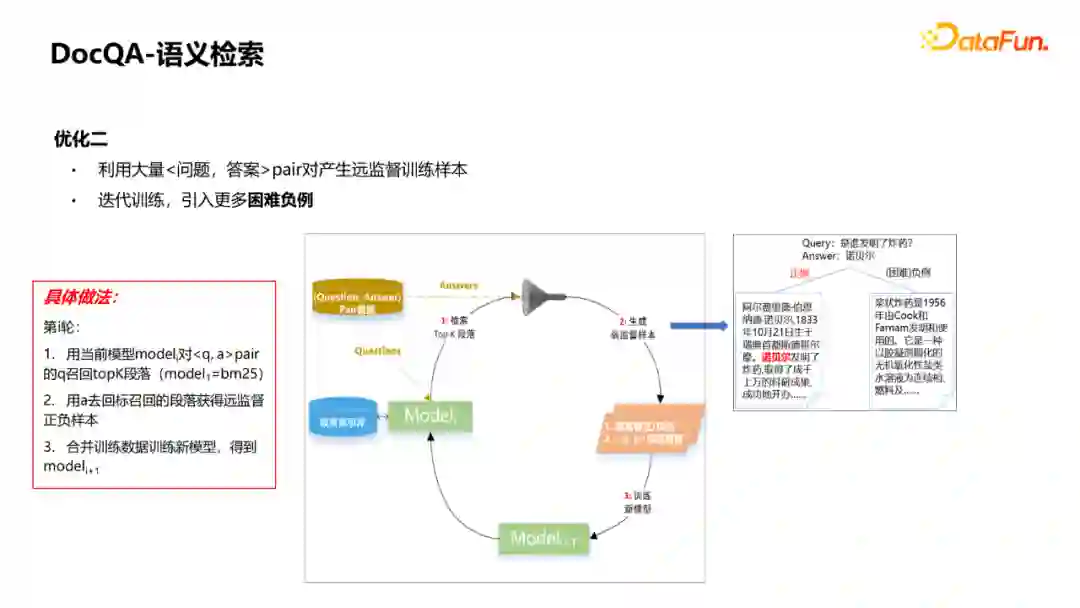
① 利用大量(问题、段落)问答对通过策略和人工筛选出一些质量比较高的来构造预训练任务,相当于在BERT训练模型基础之上,通过二次预训练来提升模型的效果。从Batch内部选Negative换成从Batch外部去选Negative,一般在训练匹配模型时,如果采用多机多卡的方式时,可以把别的卡的Query段落作为当前卡的Query的负例,每个Query的负例规模,就会从batch_size提升到gpu_num * batch_size,这样见到的负例就会更多,模型就会训练得更充分一些,可以较大地缓解训练和预测不一致的问题 ② 可以利用大量<问题,答案>pair对产生远监督训练样本来增强模型训练样本。<问题,答案>对的来源有很多方式,可以搜集一些开源数据集的问答对,或者KBQA这种去回答的问答对,有了问答对之后就可以引入他们进行远监督的样本生成。 如图就是整个流程:首先会用当前模型对收集到的QA对的Q去召回TopK的段落,如果是第一次,可以采用bm25这种无监督的方式去召回段落。召回段落后就可以用QA对的A去回标这些段落。回标到的当做正例,没回标到的当做负例。这样可以将生成的远监督样本和标注样本结合到一起去训练匹配模型,然后继续迭代。这种迭代方式可以引入更多困难负例,让模型学得更好。
3. DocQA-答案抽取
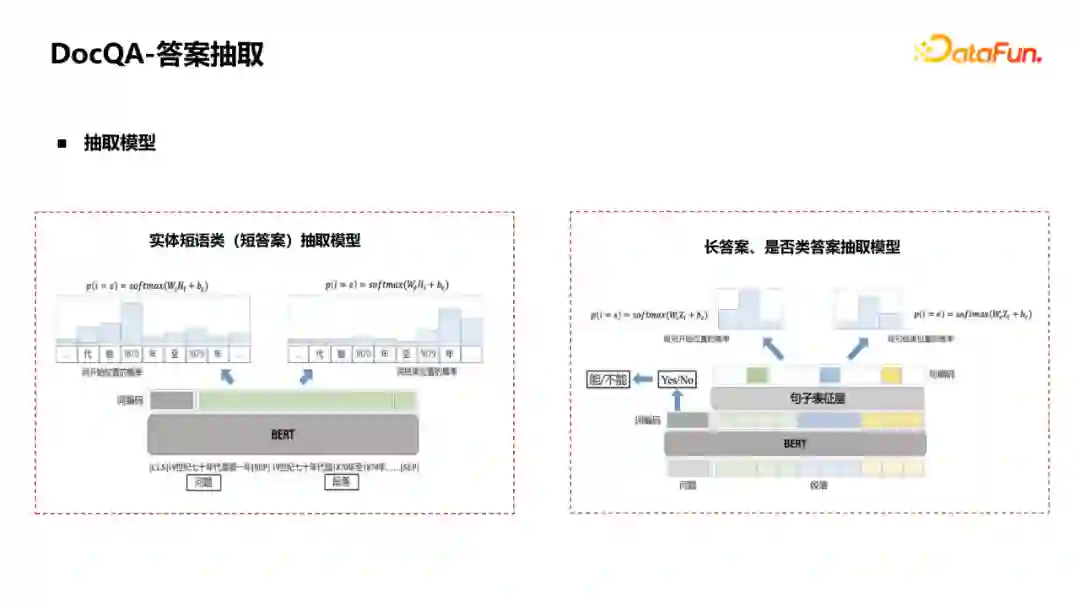
接下来介绍答案抽取(MRC)。 一般对于实体短语类(短答案)抽取,会将问题和段落拼接到一起,用一个BERT去预测片段的开始和结束。但这种方式不能很好地应用在长答案和是否类答案的抽取上,此时需要对模型进行一些改造。例如增加分类图,针对是否类答案去判断是“是”还是“否”;对长答案类,对句子进行聚合,从token级聚合成句子表征,得到了句子级的表征之后,就可以预测句子级的开始和结束。
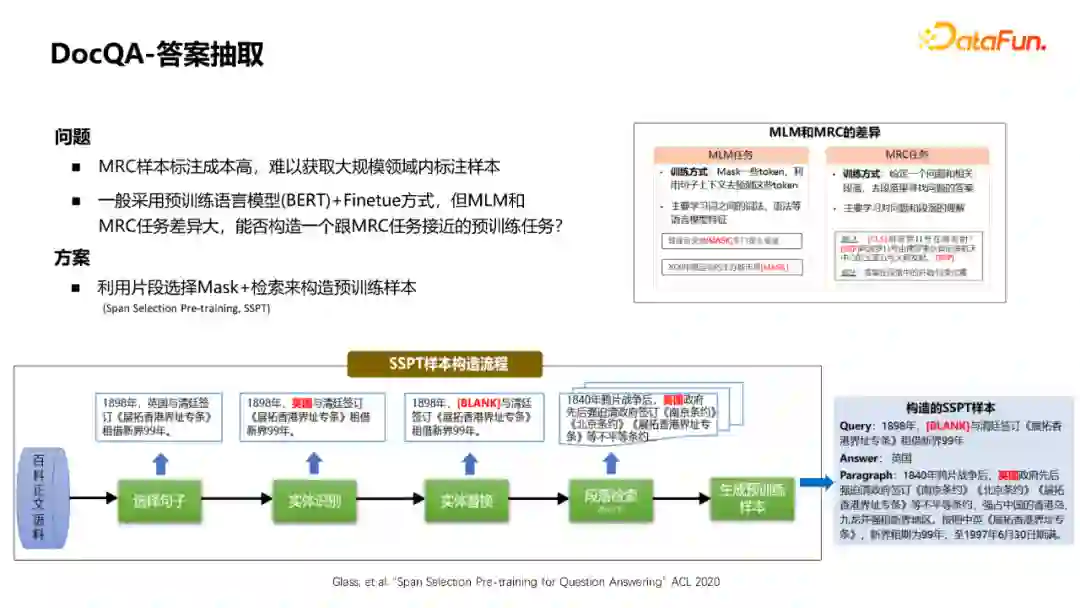
对于答案抽取这个模块,第一个问题是MRC样本标注成本高,难以获取大规模领域内标注样本。一般采用预训练语言模型(BERT)+Finetune方式,借鉴了预训练模型BERT已经学好的一些知识,可以较大地提升模型效果。但MLM和MRC任务差异较大,MLM任务主要是mask一些token,利用句子上下文去预测这些token,主要学习词之间的词法、语法等语言模型特征。MRC则是给定一个问题和相关段落,去段落里寻找问题的答案,主要学习对问题和段落的理解。
因此对于这个问题,更好的一个解决方案是能否构建一个与MRC任务接近的预训练任务。去年论文里的一种方式是利用片段选择 Mask+ 检索来构造类似MRC的预训练样本。
具体流程如图:首先需要具备一个文本库,从中选择一些句子去做实体识别,随后随机地mask掉其中的实体,用通配符来替代。这时可以将这个句子当做一个Query,去段落库中检索出TopK的段落,通过策略筛选之后,这些段落可以当做SSPT的一个样本,这个样本的形态和MRC样本的形态是比较接近的。

**第二个问题是:SSPT构造的样本包含的噪声如何处理?**其中采用的一个解决方案是新增一个问答上下文预测任务。通过建模答案周围的词和问题的语义相关性来判定是否噪声样本。对于一个噪声样本,答案项周围的词和问题无关,我们希望问答上下文预测任务的损失大,而对于正常样本,答案项周围的词和问题相关,问答上下文预测任务的损失小。
具体的做法有三个步骤:
① 定义上下文中每个词的label,将段落里的一些上下文中的一些词作为它的相关词,我们假设距离答案越近的词,越可能成为相关词。因此,启发式定义了段落中每个词属于上下文的概率label,相当于越靠近答案概率越高,越远概率越低,呈指数级衰减。 ② 估计每个词属于上下文的概率。用BERT的向量和一个额外的矩阵去算开始和结束,会对每一个词累计其区间,去算出这个词属于上下文的概率。 ③ 最后得到每个词的label和概率,就可以通过交叉熵的算法来计算预测任务上下文的损失,最后我们的损失函数就是answer抽取的损失加上这个任务的损失。 希望针对这种噪声样本损失偏大一些,对正常样本损失偏小一些。最后定义了整体的损失之后,就可以采用co-teaching去噪算法去训练模型,样本损失越大,权重越低,来达到样本去噪的目的。
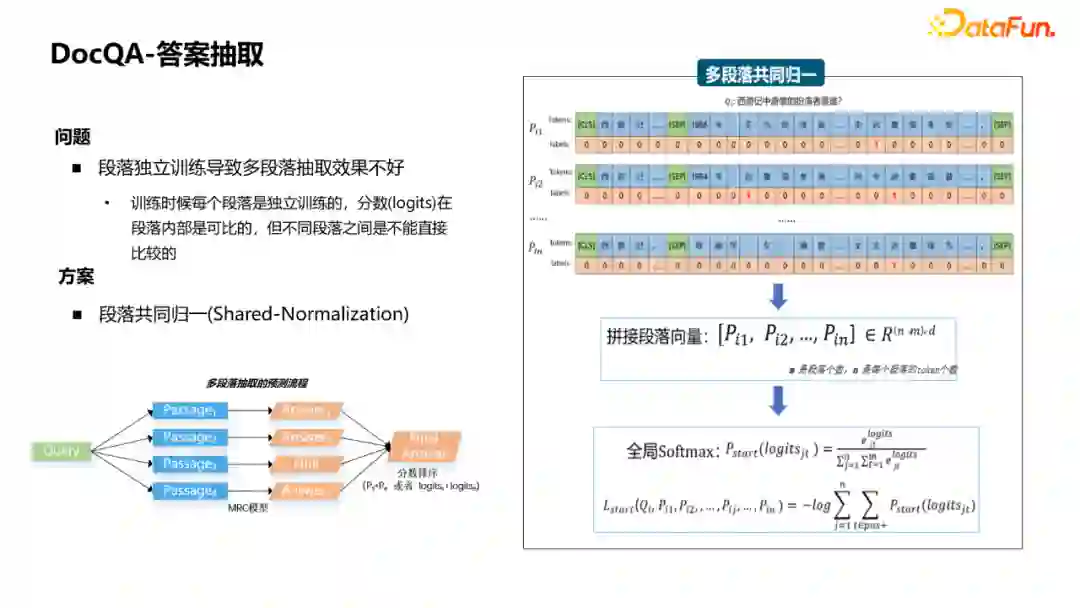
第三个问题是段落独立训练导致多段落抽取效果不好。图中展示的是多段落抽取流程,抽取时每个段落都会抽取出一个答案,会依据分数选择最后的答案。 但由于训练时每个段落是独立训练的,分数在不同段落之间是不可比的。针对这个问题可以采用的方案是段落共同归一,即针对每个段落,通过encoder得到向量后,将向量进行拼接,做一个全局的softmax去做全局的损失。这样做的好处是,最后得到的分数即使是跨段落也是可比的。
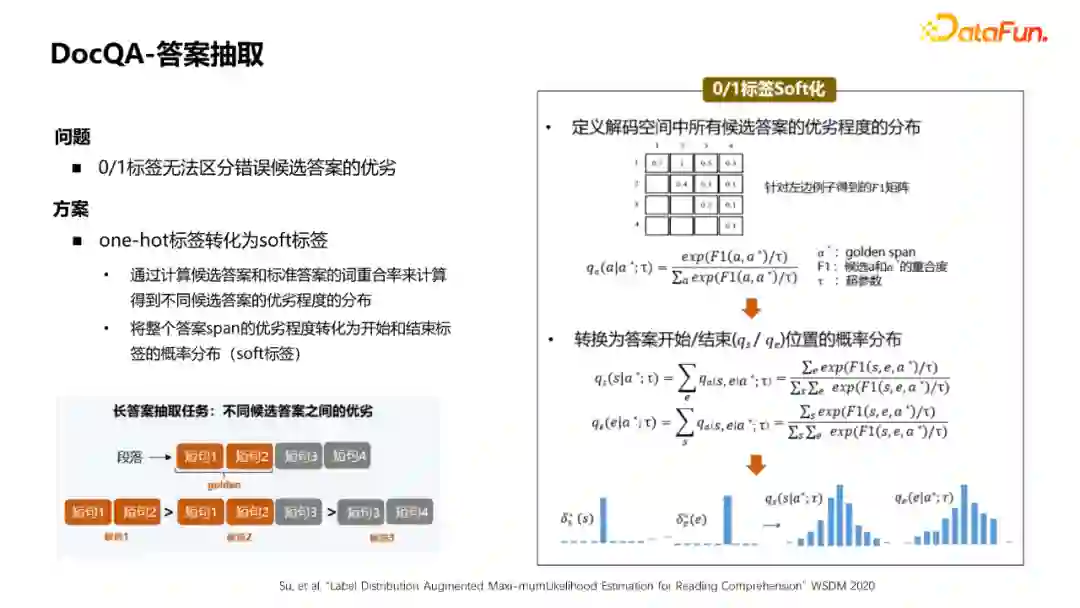
还有一个常见的问题:预测开始和结束一般会采用0/1标签,无法区分错误候选答案的优劣。相应的解决方案是将标签soft化,通过计算候选答案和标准答案的词重合率来计算得到不同候选答案的优劣程度的分布。将整个答案span的优劣程度转化为开始和结束标签的概率分布。首先计算所有候选答案的优劣矩阵,将其转化成概率分布,接下来得到每个答案开始/结束位置的概率分布。就将原来0/1的hard表示,转化成了一种soft表示。
04****未来展望

① 复杂问题的解析。除了刚才列举的一些,其实还有很多用户常问的复杂问题,比如多意图、多条件问题。对这些Query进行很好地解析和解答比较困难,需要更强大的query graph表示和更高校的解析算法。 ② 提高MRC模型的稳定性。当问题换一种问法,或者段落中存在和答案类型相同的实体且上下文和问题比较相似,容易造成模型抽取错误。这也是学术界研究的热点,也有很多成果,例如加入一些对抗样本或者对抗句子。这也是未来一个比较重要的工作。 ③ 带条件且跨片段的实体类短答案抽取。很多时候一个问题虽然是实体短语类的一个短答案问题,但可能在段落里面是带条件的,不同条件下,短实体的答案可能是不一样的。所以,不仅要抽出长句子,更精准的是要抽出这些条件以及条件对应的答案。
05
Q&A
Q1:KBQA中基于基于种子的三元组的回标部分,是不是需要维护一个标准问和相似问的表? A1:不需要,我们对属性会选出一些三元组,去回标一些问答对,对于回标上的那些问题,就是疑似问这个属性的。对这些问题再做一些去噪,加上人工策略或人工审核,最终拿到每个属性比较干净的训练数据,没有涉及到维护相似问的表。刚才介绍了一种方法,得到一些pattern之后,通过同义模型去Query log中匹配出一些扩展的问法,这些问法再通过策略处理,最后得到这个关系的更多的一些问法。 Q2:KBQA的关系识别里识别除了关系后,怎么去区分识别出的实体是主语还是宾语? A2:一般会在识别过程中单独通过一个模型去判别,问的是已知SP得O还是根据PO得S。 Q3:在关系识别中,负样本该如何选择?怎么处理字面相似但含义不同的属性? A3:如果随机抽取负例的话会比较简单,一般采用的方法是引入人工的方法标注,例如扩展问,同义匹配这种方式去获取样本。标注的时候就会自然把那些看着很相似,但其实是错误的问法给标注出来,通过类似主动学习的方式,不断加入一些困难负样本,来提升困难负例样本识别的准确率。 今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

