史上最大多模态图文数据集发布!

文 | 付瑶
编 | 小轶
最近多模态研究圈中出现了一个扬言 “史上最大规模”的多模态图文数据集:LAION-400。该数据集在今年8月完全公开,共计公开了 4亿图文对,可以依据不同的用途提供不同大小版本的子数据集。据小编调查,在 LAION-400 出现前,多模态图像文本对的最大的开放数据集是 DALE 数据集,该数据集的规模在 10M 左右,大概是 LAION-400 的 1/40,其在图文对检索等任务中已显示数据集不够大导致模型的性能欠缺。
LAION-400M 通过 CommonCrawl 提取出随机抓取 2014-2021 年的网页中的图片、文本内容。通过 OpenAI 的 Clip 计算,去除了原始数据集中文本和图片嵌入之间预先相似度低于0.3的内容和文本,提供了4亿个初筛后的图像文本对样本。
数据集下载链接:
https://laion.ai/laion-400-open-dataset/
近两年多模态的研究已经成为了一大热点。所谓道“工欲善其事,必先利其器”,一个优质的数据集是研究过程中必不可少的装备。小编在本文整理了一些常见的多模态任务常用的数据集,分享给大家:
![]() 任务一:多模态情感分析
任务一:多模态情感分析![]()
 任务一:多模态情感分析
任务一:多模态情感分析在过去的研究中,大多数基于情感分析的研究都是采用单一模态,随着情感分析算法逐渐成熟,研究者们可以发现在解决单模态的局限性的研究中,可以通过将多种模态通过特征融合、决策融合等策略等方式,使得模态之间互相辅助,互为补充,既保留模态之间的一致性,也利用模态之间的差异性。在多模态情感分析的研究中,主要有以下几个数据集:
IEMOCAP数据集
该数据集是2008年由南加大SAIL实验室录制收集,共包含了5个男演员和5个女演员录制情感互动过程,录制时长大约12h。单条数据包括对话者的音频、视频、文本、面部和姿势信息等,情感标签为愤怒、快乐、悲伤、中立等10个标签。IEMOCAP是多模态对话情绪识别中最常用的数据集,数据集单条质量较高,但是其数据集的规模较小。

《IEMOCAP: interactive emotional dyadic motion capture database. Lang Resources & Evaluation. 2008.》
数据集下载链接:
https://sail.usc.edu/iemocap/
该数据集需要发送申请表提供数据集用途,数据集提供方才会回复下载链接
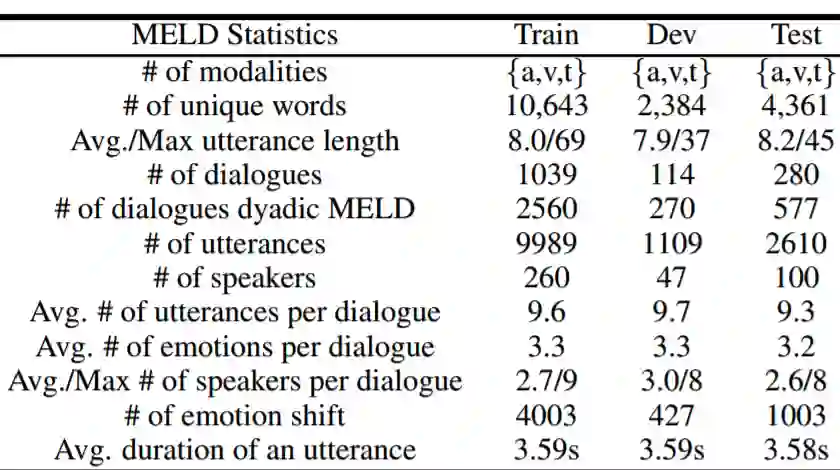
MELD数据集
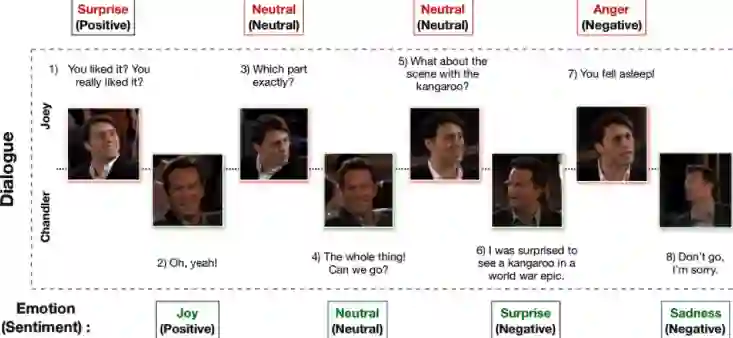
该数据集于2019年公布,是由从电视剧《老友记》中截取片段构成,模态包括文本信息、视频,共计1400对对话,总共13000句,包含7中情感,分别是angger、disgust、sadness、joy、Netural、suprise、fear,对每句话有情感注释positive、negative、neutral。该数据集规模较大,但是其剧情相关背景较为复杂,识别情感的难度增大。
相关论文:
《MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation》
数据集下载链接:
https://affective-meld.github.io/
CH-SIMS数据集
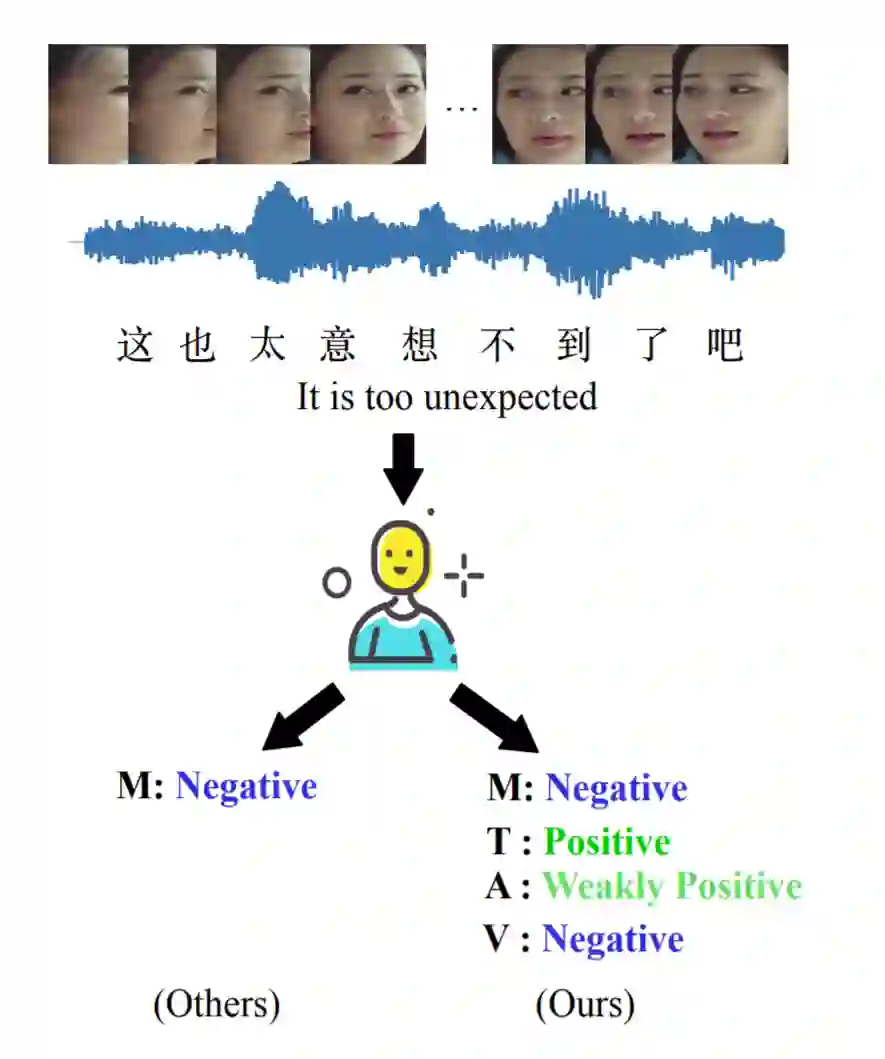
该数据集中包含60个原始视频,从中文影视作品《西虹市》、《妖猫传》中剪辑出2281个视频片段,每个片段长度在1s——10s之间。数据集的情感标注为-1(负向)、0(中性)、1(正向)。除此之外,在论文的实验中,作者证明了单模态标签对多模态的改进,该数据集不仅有多模态最终的标签,还具备各个单模态的情感标签。
相关论文:
《CH-SIMS: A Chinese Multimodal Sentiment Analysis Dataset with Fine-grained Annotations of Modality》
数据集下载链接:
https://drive.google.com/drive/folders/1E5kojBirtd5VbfHsFp6FYWkQunk73Nsv官方提供的google drive链接

SEMAINE数据集
该数据集由SEMAINE数据库收集,构建了4个机器人进行对话,数据集标注的情感维度采用连续模式情感标注,情感维度为:Valence (愉悦度), Arousal (激活度), Expectancy (预期), Power (力量)。其中Valence表示情感积极向的程度,Arousal表示兴奋程度,Expectancy表示与预期相符的程度,power表示情感影响力,其中Valence、Arousa和Expectancy为[-1, 1]范围内的连续值,Power为大于等于0的连续值。SEMAINE是对话情绪识别最常用的连续情感标注的数据集。
相关论文:
《The SEMAINE Database: Annotated Multimodal Records of Emotionally Colored Conversations between a Person and a Limited Agent》
数据集下载链接:
https://semaine-db.eu/DailyDialog
除以上三个最具代表性的多模态情感分析数据集之外 CMU 制作的CMU-MOSEI、CMU—MOSI、上海交通大学标注的SEED等数据集结合了视频、文本、语音等模态,也是多模态情感分析研究任务较为通用的数据集。
![]() 任务二:多模态检索
任务二:多模态检索![]()
多模态检索即不同模态的同类别之间的搜索,例如文搜图,图搜文等,融合不同的模态便于检索,
COCO
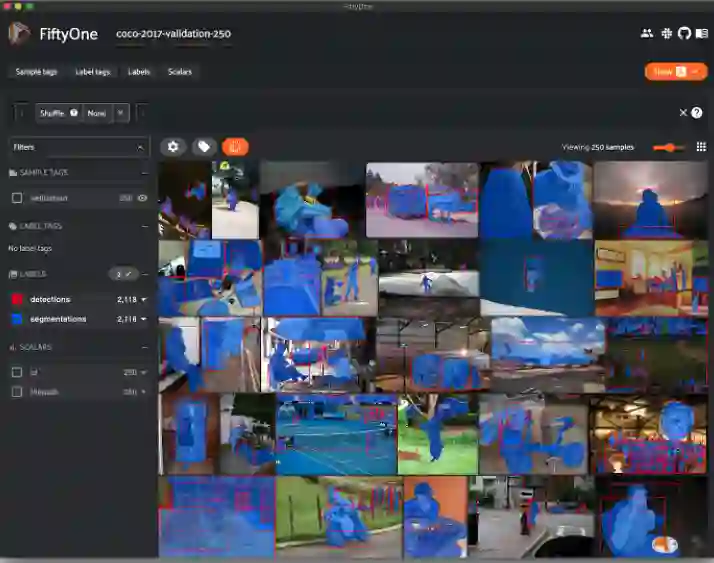
COCO数据集是2015年由微软发布的一个大型物体检测、分割和字母数据集,包含近20万个图像,91类目标、328000影响和2500000个label,标注分为目标点检测、关键点检测、实例分割、全景分割、图片标注,COCO数据集主页还提供了Matlab、Python和Lua的API接口,可以提供完整的数据的加载、parsing和可视化。
相关论文:
《Microsoft COCO Captions Data Collection and Evaluation Server》
数据集下载链接:
https://cocodataset.org/#download
IAPR TC-12数据集
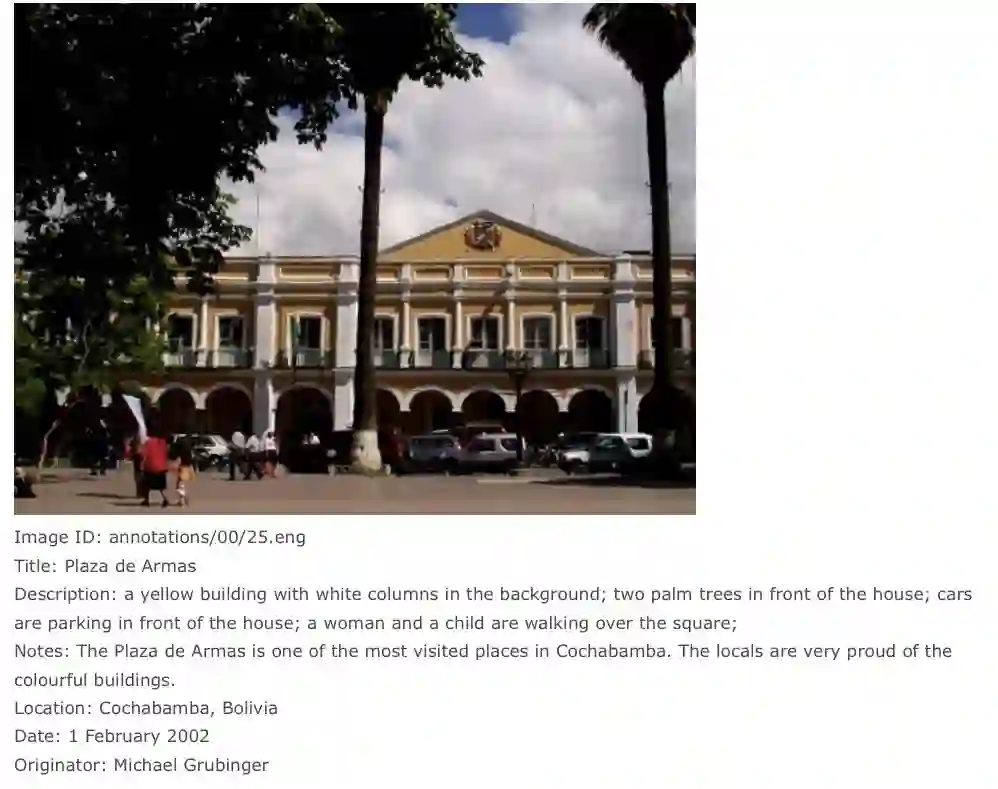
IAPR TC-12是图像模式识别协会来源自2万张拍摄于世界各地的静态自然图像,包括不同的运动和动作的照片,人、动物、城市、风景和当代生活的许多其他方面的照片。每张图片配对了三种语言英语、德语、西班牙语的标注。
相关论文:
《The IAPR Benchmark: A New Evaluation Resource for Visual Information Systems》
数据集下载链接:
https://www.imageclef.org/photodata
Conceptual Captions Dataset
该数据集于2018年出品自GoogleAI,研究者们团队通过创建自动 pipeline从数十亿的网页中提取和过滤图片标题,大约有330万张图片-文字对。
相关论文:
《Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning》
数据集下载链接:
https://github.com/google-research-datasets/conceptual-captions
![]() 任务三:多模态对话
任务三:多模态对话![]()
大规模多模态对话数据集可以对话中不同的视觉信息融入到对话中,进而生成更高质量的对话。
OpenViDial 数据集

OpenViDial 数据集于2020年创建,通过构建训练一个OCR模型提取图片+添加字幕”的形式构造得到。该数据集从影视作品抽取字幕和当前字幕的视频帧构成(句子、图片)对,保持数据分布的一致性,经过数据处理和清洗,最终得到一百万余句子以及对应的图片信息。
相关论文:
《OpenViDial: A Large-Scale, Open-Domain Dialogue Dataset with Visual Contexts》
数据集下载链接:
https://github.com/ShannonAI/OpenViDial
![]() 小结
小结![]()
本文介绍了多模态几大任务所常用的数据集,我们可以看到主要以下两种方式来构建多模态情数据集:第一种是来自网络资源例如从影视资源中截取片段构建的MELD,CH-SIMS数据集。另外一种是基于对特定情感类别进行演绎并录制,例如IECOMP。除此之外,多模态数据集的模态也可以通过包含模态区分,例如图文多模态数据集、文本视频音频组合数据集、脑电模态数据集等。由于多模态数据集的标注涉及到两种模态之间的对齐、统一标注标准等问题,相较于单模态的数据集更加复杂耗力,因此除了构建规模更大,数据更优质的数据集,制定更高效的多模态情感数据集的标注策略也是值得关注的问题。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【