这篇AAAI 2022论文申请撤稿!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
hello,大家好!我是Amusi!
前言
其实关注《如何看待AAAI22《Mind Your Clever Neighbours》疑似真实标签做无监督?》这个事件有段时间了,经常逛知乎的同学应该多少也看到过这个话题(目前已782人关注,浏览量近百万)。

https://www.zhihu.com/question/504163027
今天正好是12月18日,也是这篇AAAI 2022撤稿论文的通讯作者张平平所答应的回复deadline:"将在第一时间(不晚于12月18日)做好实验说明和分析再来更新答复"。
今早 Amusi 在吃娱乐圈巨瓜的时候(懂得都懂),点开了这个AAAI 2022论文话题(因为知乎又推送了一遍),看到通讯作者张平平于12月17日晚 23:21更新了回复:所有作者一致同意将向AAAI组委会申请撤稿。
AAAI 2022 论文撤稿起因

Mind Your Clever Neighbours: Unsupervised Person Re-identifification via Adaptive Clustering Relationship Modeling
论文链接:https://arxiv.org/abs/2112.01839
撤稿的原因主要是"错误使用文件名问题",这里转载几个知乎回答,大家便能全部了解。
作者:匿名用户
https://www.zhihu.com/question/504163027/answer/2259411683
刚刚在arxiv上发现了这篇文章,标签显示已经被AAAI2022接收,拉到最下面看实验结果,性能真的是匪夷所思,几乎达到了有监督的水平。本人也是做这个方向的,看到这篇文章感觉很绝望,因为UDA形式的指标可能都没有达到这个水平(本人查阅论文能力有限,本人没有看到文章有这么高的指标,但是也许存在),但是这篇号称完全无监督的已经到了这个程度。于是就拜读了这篇文章,发现这篇文章使用了一个先验性特别强的条件,就是将所有的图片按照名字进行排序,然后再依据这个排序做所谓的无监督训练。但是做这个方向的人应该都知道,文章中使用到的dukemtmc和market1501的训练集的图片的命名就是按照ID进行的,如果按照文件名进行排序,那么几乎就约等于是使用了真实标签,与文章所说的完全无监督相背了。对于这篇文章能入选AAAI2022有些不解,希望圈内大佬能帮着消化消化,是不是我对这篇文章的理解有误
作者:匿名用户
https://www.zhihu.com/question/504163027/answer/2261735071
今天看到这个问题,本来在准备很重要的事情,特地打印了这个论文好好拜读了一波。先说我自己的结论:使用了图片名进行排序一定会导致标签泄漏,不能称之为无监督,本文的确有问题,这一点没得洗!
这篇论文出发点是用Graph来优化feature,这个想法虽然不新鲜,但是也合情合理,最近也有不少人这么做。不说这个论文四个繁琐得没必要的图和别的components,直接说按照图片名排序这个问题,做reid的同学应该都知道他有问题,我主要是给不做reid的吃瓜群众说一下(感觉审稿人也不做reid,所以没发现这个问题):
作者也在文章里说:“There is such a prior knowledge in the Re-ID task that if we sort the training set, the images with the same identity will gather together.”这个论文的二作也在本问题下说他做了很久reid了。那么作者应该知道,数据集中同一个行人的图像是来自于不同的camera下的。数据集的提供者在给图像进行标号的时候,文件名也大部分是以 "PersonID_CameraID_其他信息.jpg"构成的。所以按照图片名排序之后,同一个人的图片就出现在了一起。这时候,无论怎么划分序列,作者都用到了标注中跨camera的标注信息!而本身reid问题难点和实际意义,就是跨camera的正样本难以匹配啊,近期即使有用标注信息做半监督或弱监督的,也是用的同一个camera下的ID信息,这一点也是合理的,毕竟同一个camera下的图片是一个视频序列,tracking本身就能获取到一个行人连续几帧的图。但是大家都不会用跨camera的ID信息啊。这个就是作弊没得洗的!
详细解释一下为啥是作弊:
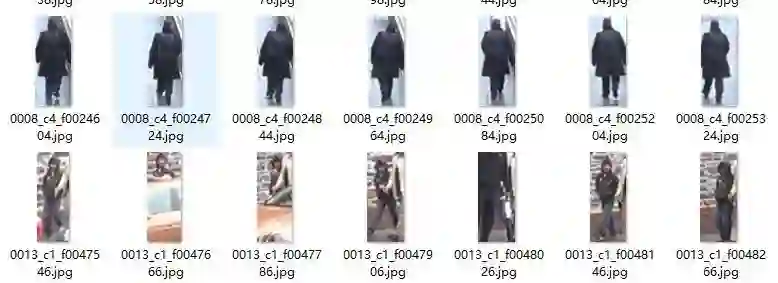
作者排序之后,按照顺序划分为n个group,每个group有16个图片。由于数据集本身平均每个人就20张图左右,所以分完之后,每个group 的情况大概就是这么几种,1)整个group全是一个人的图片,2)group里就两个人,前几张一个人,后几张一个人。3)group里就三个人,前少量几张是一个人的,后几张是一个人的,中间几张是一个人(同时也是这个人所有的图片)。比如duke,按照论文的划分,第一个group全是第一个人的图片,然后你做feature refinement,跨摄像头的图片特征互相refine一波,然后聚类,然后你说这个不作弊?
二作解释说,每个人的图片会随机分到不同的group。好,我们从每个人的图片的角度来看,无非这么几种情况:1)全部在一个group,2)分在前后两个groups,一个group的头,一个group的尾。3)连续三个及以上的groups,中间的几个groups非常干净,全是这个人的图片。另外一个很重要的问题是,ID连续的行人,完全可能是差异非常大的行人。比如下面,是duke上ID=1 和ID=2的图片。在一个group里面区分不是难事,所以一个group里面出现若干个行人的图片影响很小的。
论文表2 里的ablation study说明,论文的性能基本全依靠cluster refinement。所以这个cluster refinement应该是最重要的component,而这里又有标签泄漏……所以建议撤稿吧,以后简历里面有这个论文,去哪里找工作如果碰到面试官知道这个事情就完犊子了。
二作的解释里,大部分在强行洗,唯一有道理的是他说,不用排序,只做二次聚类,也能够达到不错的性能。这其实挺好的啊,搞不懂为啥非要弄个排序??是觉得二次聚类太trick?
---- 内容分割线 ---
Amusi 发现这篇AAAI 2022撤稿论文的二作也在本知乎话题下进行了回复,但回复的内容跟通讯作者张平平的回复比起来,显得过于"苍白无力",所以这里就不分享二作的回复了,感兴趣的同学可以上知乎看看详情。
通讯作者张平平正面回复:撤稿
作者:zhpp
https://www.zhihu.com/question/504163027/answer/2262519289
本人是该工作的通讯作者张平平,今天下午看到此问题,经所有作者讨论,回复如下:
1. 论文投稿和rebuttal经过学生已在(https://www.zhihu.com/question/504163027/answer/2261562294)中回复,arXiv论文是投稿版本,并未包含rebuttal补充的修改与实验;
2. 正在全面的做random shuffle setting的实验,将在第一时间(不晚于12月18日)做好实验说明和分析再来更新答复;
3. 完成相关试验后,在camera-ready截止日期前根据新的结论和rebuttal阶段的讨论内容跟AAAI主席沟通是否撤稿。
======================
感谢各位网友的关注,经详细实验验证,二次回复如下:
1. 错误使用文件名问题:错误地使用图片名作为排序标准是我们的实验失误,深表抱歉;所有作者一致同意将向AAAI组委会申请撤稿。
在打乱顺序的情况下,各个数据集上的模型性能变化如下:
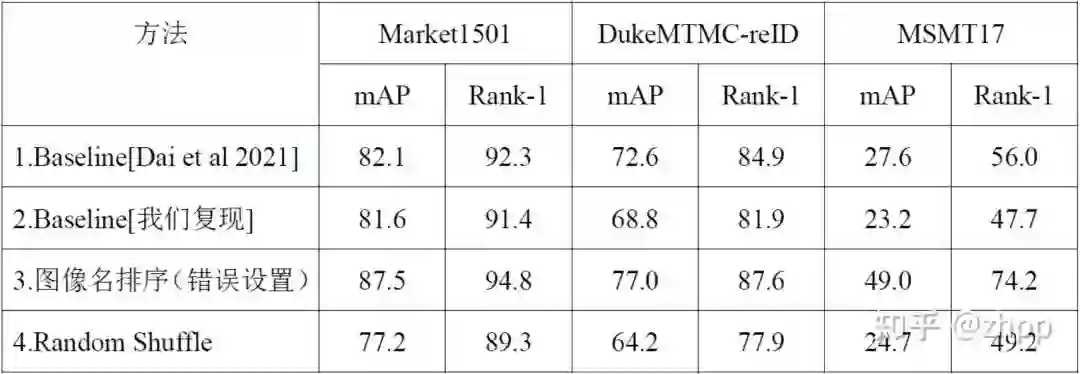
方法4:在3的模型结构基础上对训练集使用Random Shuffle操作。
Baseline[我们复现]:原论文是4卡训练,我们都是2卡训练。批次数是原论文的一半。需要指出的是:上表中我们复现的Baseline结果与原AAAI22投稿中Baseline方法(Dai et al 2021)汇报的结果有一定的差距(https://arxiv.org/pdf/2103.11568.pdf)。在重新检查Baseline论文后,我们发现Baseline原论文更新了Arxiv版本(https://arxiv.org/pdf/2103.11568v3.pdf),其结果有所变化。
2. 算法有效性问题:
在实验过程中发现的一些现象和结论,分享出来供大家参考:
(1)通过对错误排序版本和Random Shuffle版本的学习过程进行分析,发现GCL实际上需要每个小图内有相关正样本才能起到比较好的消息传播作用,否则会损害原始特征,导致效果进一步变差;
(2)在Rebuttal中我们采用了二次聚类策略来尝试给GCL好的初始化,避免使用文件名。在重新做实验的过程中,我们发现在一定条件下GCL可以起到不错的正向作用,也就是使用Baseline方法预训练的ResNet-50初始化+聚类。
其中涉及的关键技术和结论如下:
1. 为了避免标签泄露,我们对3个训练集的所有图片进行随机打乱。
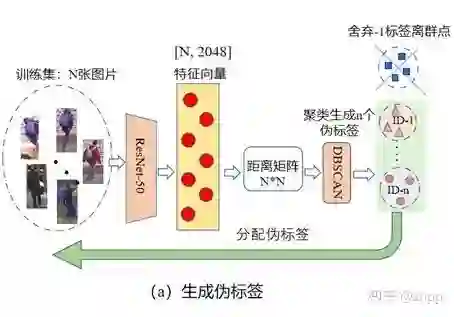
2. 使用的Baseline方法
Baseline方法参考文献 (Dai et al. 2021), 分为三步:(a)伪标签生成;(b)监督训练;(c)测试集评估。
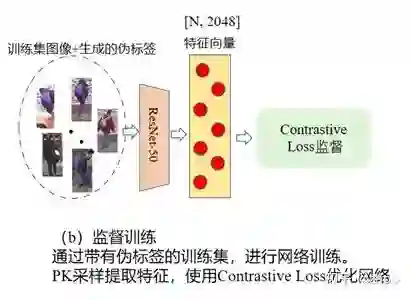
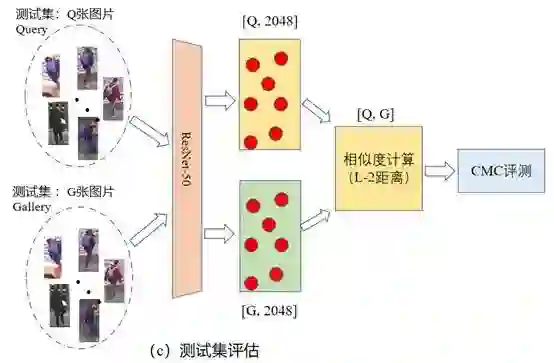
测试阶段:Baseline方法和我们方法均使用ResNet-50后的特征进行测试,流程如下图所示:
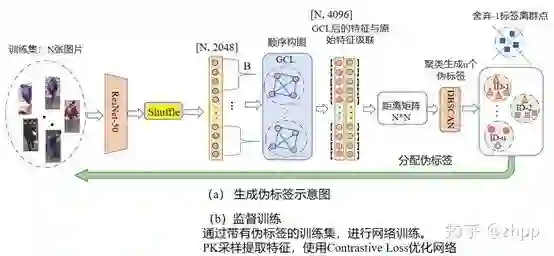
3. 投稿论文中方法
投稿论文中实际的算法流程如下图所示,核心的问题是错误地使用了图片名来排序,存在标签泄露问题。
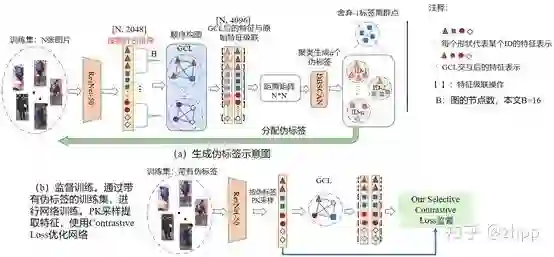
4. 全打乱顺序方法
针对各位网友关心的打乱顺序方法,我们将Random Shuffle操作应用到生成伪标签过程中,如下图所示:
5. Rebuttal阶段提到的二次聚类方法
该方法的出发点是我们利用二次聚类避免使用文件名排序,具体流程如下图所示:
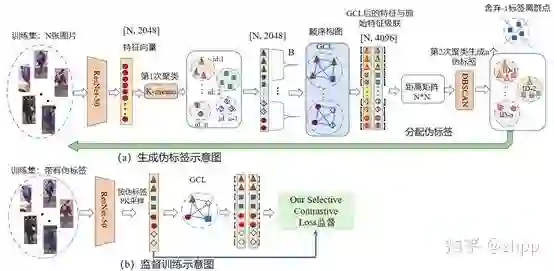
这里我们使用第一次聚类(K-means)得到的伪标签进行排序,顺序构建子图,然后每个子图施加GCL模块,得到传播后的特征。
6. 实验结果及分析
所有实验均在双卡2080ti上进行,环境主要配置:Python3.6、Pytorch1.0、Torchvision=0.3.0、Faiss=1.6.3、Cuda10.1/10.2。
Market1501数据集超参数: GCL中的参数(图的大小为16,温度参数5),K-means中的K设置为800。
DukeMTMC-reID数据集超参数: GCL中的参数(图的大小为16,温度参数为5),K-means中的K设置为750。
MSMT17数据集超参数: GCL中的参数(图的大小为16,温度参数为5),K-means中的K设置为1300。
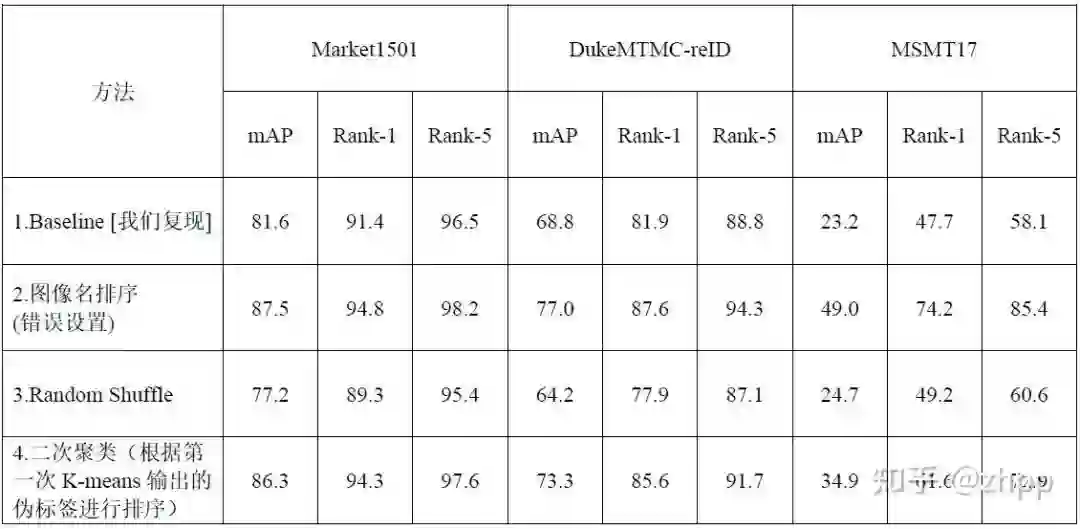
从本表中可以看出:1)在Random Shuffle设置下,GCL将会反向优化,损害模型的性能。2) GCL能起作用的条件是:子图中有比较良好的近邻关系,也就是第一次的聚类结果要比较可靠。
小结:
(1) 在能挖掘到较为良好的近邻关系时,GCL会起到正向作用,提升网络的性能;反之,打乱顺序,则GCL会反向优化。
(2) 实验结果表明,在使用伪标签排序条件下,所提模型在Market1501和DukeMTMC-reID数据集上有一定的优势,但是在MSMT17数据集上表现较差。
最后,对于给大家带来困扰再次表示抱歉,今后会更加注重实验规范性。
--- End ---
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号





