推荐一个基于TF2.0的推荐算法仓库

前言
开源项目Recommended System with TF2.0主要是对阅读过的部分推荐系统、CTR预估论文进行复现。建立的原因有三个:
-
理论和实践似乎有很大的间隔,学术界与工业界的差距更是如此; -
更好的理解论文的核心内容,增强自己的工程能力; -
很多论文给出的开源代码都是TF1.x,因此想要用更简单的TF2.0进行复现;
当然也看过一些知名的开源项目,如DeepCTR等,不过对自己目前的水平来说,只适合拿来参考。
项目特点:
-
使用TF2.0-CPU进行复现; -
每个模型都是相互独立的,不存在依赖关系; -
模型基本按照论文进行构建,实验尽量使用论文给出的的公共数据集。如果论文给出github代码,会进行参考; -
对于实验数据集有专门详细的介绍; -
代码源文件参数、函数命名规范,并且带有标准的注释; -
每个模型会有专门的代码文档( .md文件)或者其他方式进行解释;
目前复现的模型有(按复现时间进行排序):
-
NCF -
DIN -
Wide&Deep -
DCN -
PNN -
Deep Crossing -
FM -
AFM -
DeepFM
-
BPR -
Caser -
MF -
SASRec -
NFM -
DNN
持续更新中······
数据集介绍
目前实验使用的数据集主要有三个:Movielens、Amazon、Criteo。
Movielens
MovieLens是历史最悠久的推荐系统数据集,主要分为:ml-100k(1998年)、ml-1m(2003年)、ml-10m(2009年)、ml-20m(2015年)、ml-25m(2019年)。实验中主要使用ml-1m数据集。
已处理过的数据集:ml-1m
ml-1m数据集的具体介绍与处理:传送门【https://grouplens.org/datasets/movielens/】
Amazon
Amazon提供了商品数据集,该数据集包含亚马逊的产品评论和元数据,包括1996年5月至2014年7月期间的1.428亿评论。它包括很多子数据集,如:Book、Electronics、Movies and TV等,实验中我们主要使用Electronics子数据集。
Amazon-Electronics数据集的具体介绍与处理:传送门【https://jmcauley.ucsd.edu/data/amazon/】
Criteo
Criteo广告数据集是一个经典的用来预测广告点击率的数据集。2014年,由全球知名广告公司Criteo赞助举办Display Advertising Challenge比赛。但比赛过去太久,Kaggle已不提供数据集。现有三种方式获得数据集或其样本:
-
Criteo_sample.txt:包含在DeepCTR中,用于测试模型是否正确,不过数据量太少; -
kaggle Criteo:训练集(10.38G)、测试集(1.35G);(实验大部分都是使用该数据集) -
Criteo 1TB:可以根据需要下载完整的日志数据集;
Criteo数据集的具体介绍与处理:传送门【https://github.com/BlackSpaceGZY/Recommended-System-with-TF2.0/blob/master/Dataset%20Introduction.md#3-criteo】
复现论文
1. Neural network-based Collaborative Filtering(NCF)
模型:
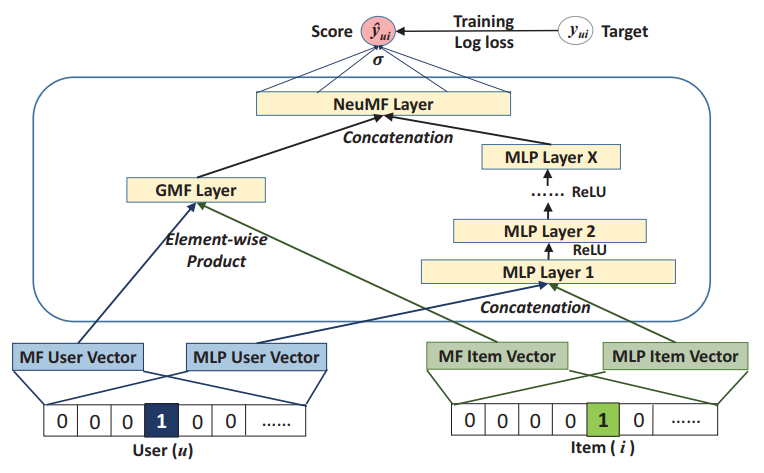
数据集:
Movielens、Pinterest
代码解析:
原文开源代码:
https://github.com/hexiangnan/neural_collaborative_filtering
原文地址:
https://arxiv.org/pdf/1708.05031.pdf?source=post_page
2. Deep Interest Network for Click-Through Rate Prediction(DIN)
模型:
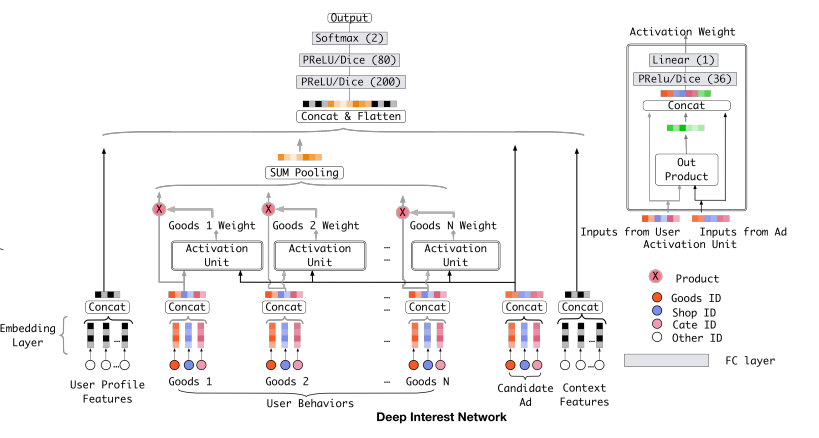
数据集:
Amazon数据集中Electronics子集。
代码解析:
参考原文开源代码地址:
https://github.com/zhougr1993/DeepInterestNetwork
原文地址:
https://arxiv.org/pdf/1706.06978.pdf
3. Wide & Deep Learning for Recommender Systems
模型:
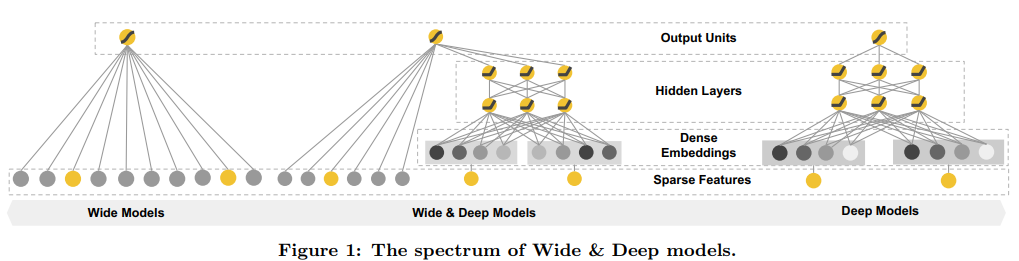
数据集:
由于原文没有给出公开数据集,所以在此我们使用Amazon Dataset中的Electronics子集,由于数据集的原因,模型可能与原文的有所出入,但整体思想还是不变的。
代码解析:
原文地址:
https://arxiv.org/pdf/1606.07792.pdf
4. Deep & Cross Network for Ad Click Predictions
模型:
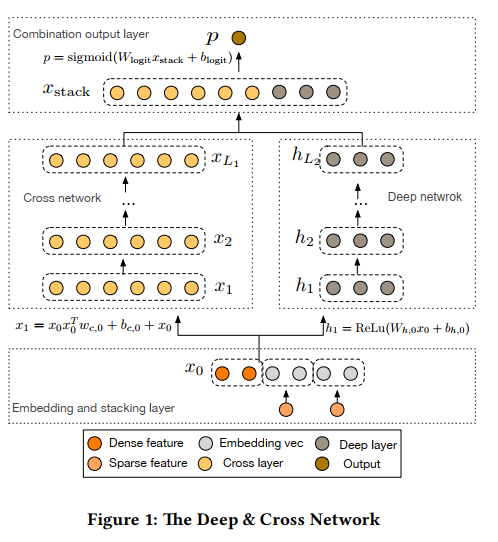
数据集:
Criteo
代码解析:
原文地址:
https://arxiv.org/pdf/1708.05123.pdf
5.Product-based Neural Networks for User Response Prediction
模型:
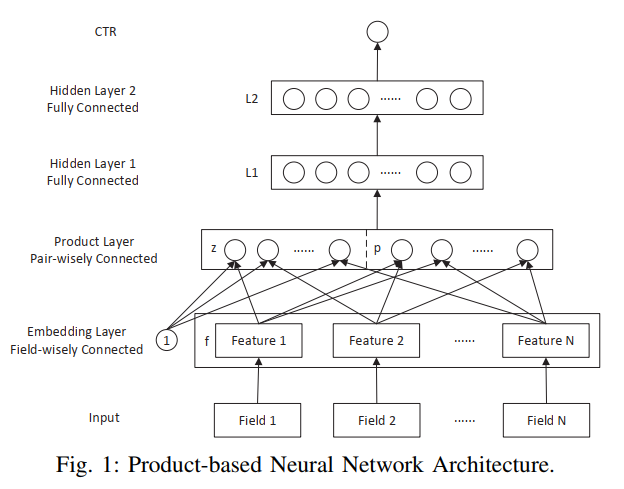
数据集:
Criteo
代码解析:
原文地址:
https://arxiv.org/pdf/1611.00144.pdf
6. Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features
模型:
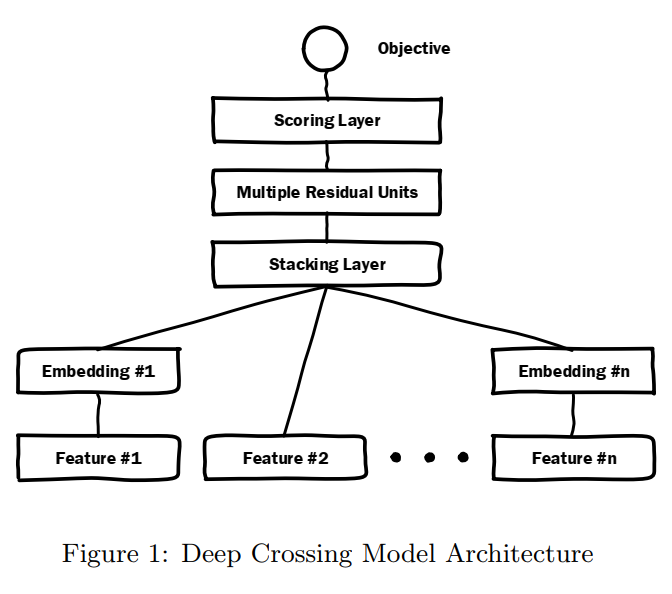
数据集:
Crieto
代码解析:
Deep Crossing代码文档
原文地址:
https://www.kdd.org/kdd2016/papers/files/adf0975-shanA.pdf
总结
希望大家给个star支持一下,非常感谢🙏
喜欢的话点个在看吧👇




