【泡泡图灵智库】DeepVoting:部分遮挡下语义部分检测的强大可解释深度网络
泡泡图灵智库,带你精读机器人顶级会议文章
标题:DeepVoting: A Robust and Explainable Deep Network for Semantic Part Detection under Partial Occlusion
作者:Zhishuai Zhang,Cihang Xie,Jianyu Wang,Lingxi Xie,Alan L. Yuille
来源:CBMM Memo No. 086,2018
编译:皮燕燕
审核:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是—DeepVoting:部分遮挡下语义部分检测的强大可解释深度网络,该文章发表于CBMM Memo No. 086,2018。
本文研究了部分遮挡下检测物体的语义部分(例如汽车的车轮)的任务。文章提出所有的模型都应该在没有看到遮挡的情况下进行培训,基于无遮挡下获得的信息对有遮挡的情况进行处理。上述方法缓解了为了覆盖所有遮挡模式的而收集指数型大数据集的困难,并且更为重要。在这种情况下,基于提案的深度网络,如RCNN系列,通常会产生不令人满意的结果,因为提案提取和分类阶段可能会被不相关的遮挡物混淆。为了解决这个问题,“Detecting semantic parts on partially occluded objects”提出了一种投票机制,它结合了多个局部视觉线索来检测语义部分。即使由于遮挡导致某些视觉线索丢失,语义部分仍然可以被检测到。然而,这种方法是手动设计的,因此很难以端对端的方式进行优化。文章提出的DeepVoting将“Detecting semantic parts on partially occluded objects”所示的鲁棒性结合到深度网络中,从而可以对整个流程进行联合优化。具体来说,它在深度网络的中间特征之后增加了两层,例如VGGNet的pool-4层。第一层提取局部视觉线索的证据,第二层利用视觉线索和语义部分之间的空间关系执行投票机制。我们还通过从对象外部的上下文中学习视觉线索来提出改进的版本DeepVoting +。在实验中,DeepVote比包括Faster-RCNN在内的几种基线方法在遮挡下实现语义部分检测的性能显着提高。此外,深度投票具有可解释性,因为可以通过查找投票线索来诊断检测结果。
介绍
主要贡献有:
1、提出了DeepVoting和DeepVoting+两种适用于部分遮挡下实现语义功能的的端对端的检测框架。
2 、将Deep-Voting与Faster-RCNN等进行了比较,除了对遮挡情况下检测精度更高,测试速度提高了2.5倍,而且提供了通过查找投票来解释检测结果的可能性。
算法流程

图1 DeepVoting的框架
1、 将图片输入到16层的VGGNet中获得pool-4特征;
2、 pool-4特征输入到VC层得到视觉概念图;
3、 视觉概念图经由投票层得到语义部分图;
4、基于语义部分图,文章执行边界框回归,然后进行非最大抑制以获得最终结果。
主要结果
1、 无遮挡语义部分检测
如图2所示是文章在无遮挡图片上的语义部分检测精度。无论是通过K-Means聚类还是DeepVoting获得视觉概念,投票和DeepVoting的平均检测精度都明显高于使用单个视觉概念进行检测。。
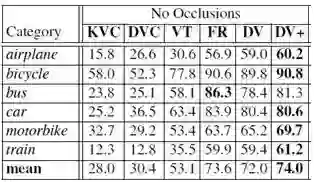
图2 6种方法对无遮挡图片的检测精度(平均AP,%)
1.1 尺度预测精度
在超过75%的情况下,预测的相对误差不超过10%。 实际上,这些预测结果DeepVoting来说足够准确。 即使提供了地面真实尺度并且文章相应地重新缩放图像,检测精度也从72.0%略微提高到74.5%。

图3 预测尺度与真实尺度比值的分布图
2、 有遮挡语义部分检测
如图4所示,在遮挡是L1、L2以及L3级别下DeepVoting方法的检测精度相比Voting和Faster-RCNN方法的高很多。
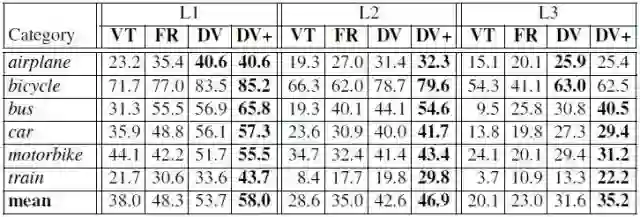
图4 4种方法对有遮挡图片的检测精度(平均AP,%)
为了验证Faster-RCNN在对有遮挡的图片进行语义部分检测时proposal召回和分类器有明显的退化,文章对proposal召回和分类器的准确性进行了评估。 结果如图5所示。图中左侧四列的结果可以看到随着遮挡的级别越高proposal召回的值显著变低。图中中间三列是基于Faster-RCNN方式处理不同级别的有遮挡照片的mAPs(%), 图中右侧三列是基于DeepVoting+方式处理不同级别的有遮挡图片的mAPs(%),可以看出DeepVoting+优于Faster-RCNN。
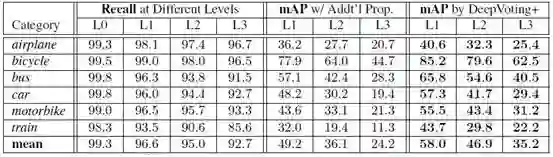
图5 proposal召回和分类器评估结果
3、可视化视觉概念和热图
图6展示了一些典型的学习视觉概念和空间热图。可以看到,学习的视觉概念和空间热图在语义上是有意义的,即使在训练期间只有语义部分级监督。

图6 视觉概念和空间热图的可视化
4、检测结果解释
基于DeepVoting以及DeepVoting+方法能够解释检测结果。如图7所示,文章给出了三个例子,分别为无遮挡、部分遮挡和完全遮挡。发现 DeepVoting可以推断遮挡语义部分,并且还能够查找投票(支持)视觉概念进行诊断,挖掘错误并了解文章方法的工作机制。

图7 DeepVoting可实现检测结果解释

Abstract
In this paper, we study the task of detecting semantic parts of an object, e.g., a wheel of a car, under partial occlusion. We propose that all models should be trained without seeing occlusions while being able to transfer the learned knowledge to deal with occlusions. This setting alleviates the difficulty in collecting an exponentially large dataset to cover occlusion patterns and is more essential. In this scenario,
the proposal-based deep networks, like RCNN-series, often produce unsatisfactory results, because both the proposalextraction and classification stages may be confused by the irrelevant occluders. To address this, [25] proposed a voting mechanism that combines multiple local visual cues to detect semantic parts. The semantic parts can still be detected
even though some visual cues are missing due to occlusions. However, this method is manually-designed, thus is hard to be optimized in an end-to-end manner.
In this paper, we present DeepVoting, which incorporates the robustness shown by [25] into a deep network, so that the whole pipeline can be jointly optimized. Specifically, it adds two layers after the intermediate features of a deep network, e.g., the pool-4 layer of VGGNet. The first layer extracts the evidence of local visual cues, and the second layer performs a voting mechanism by utilizing the spatial
relationship between visual cues and semantic parts. We also propose an improved version DeepVoting+ by learning visual cues from context outside objects. In experiments,
DeepVoting achieves significantly better performance than several baseline methods, including Faster-RCNN, for semantic part detection under occlusion. In addition, Deep-
Voting enjoys explainability as the detection results can be diagnosed via looking up the voting cues.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com