入门 | 神经网络训练中,Epoch、Batch Size和迭代傻傻分不清?
选自Medium
机器之心编译
参与:刘晓坤
你肯定经历过这样的时刻,看着电脑屏幕抓着头,困惑着:「为什么我会在代码中使用这三个术语,它们有什么区别吗?」因为它们看起来实在太相似了。
为了理解这些术语有什么不同,你需要了解一些关于机器学习的术语,比如梯度下降,以帮助你理解。
这里简单总结梯度下降的含义...
梯度下降
这是一个在机器学习中用于寻找最佳结果(曲线的最小值)的迭代优化算法。
梯度的含义是斜率或者斜坡的倾斜度。
下降的含义是代价函数的下降。
算法是迭代的,意思是需要多次使用算法获取结果,以得到最优化结果。梯度下降的迭代性质能使欠拟合的图示演化以获得对数据的最佳拟合。
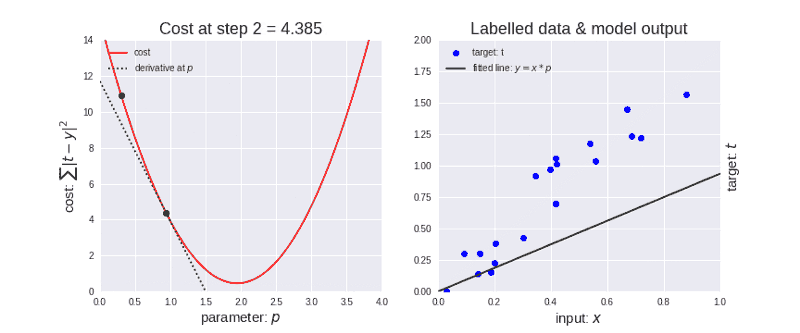
梯度下降中有一个称为学习率的参量。如上图左所示,刚开始学习率更大,因此下降步长更大。随着点下降,学习率变得越来越小,从而下降步长也变小。同时,代价函数也在减小,或者说代价在减小,有时候也称为损失函数或者损失,两者都是一样的。(损失/代价的减小是一件好事)
只有在数据很庞大的时候(在机器学习中,几乎任何时候都是),我们才需要使用 epochs,batch size,迭代这些术语,在这种情况下,一次性将数据输入计算机是不可能的。因此,为了解决这个问题,我们需要把数据分成小块,一块一块的传递给计算机,在每一步的末端更新神经网络的权重,拟合给定的数据。
EPOCHS
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
然而,当一个 epoch 对于计算机而言太庞大的时候,就需要把它分成多个小块。
为什么要使用多于一个 epoch?
我知道这刚开始听起来会很奇怪,在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但是请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。
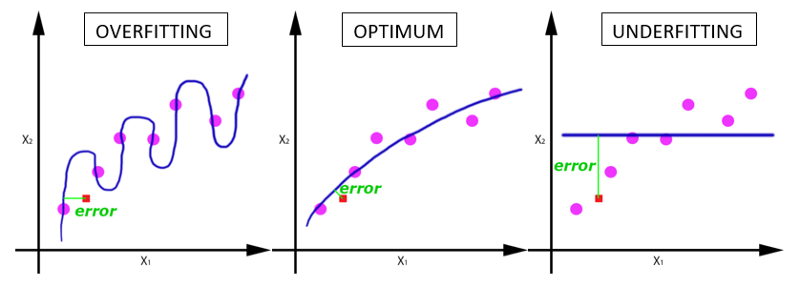
随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
那么,几个 epoch 才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的 epoch 的数量。比如,只有黑色的猫的数据集,以及有各种颜色的猫的数据集。
BATCH SIZE
一个 batch 中的样本总数。记住:batch size 和 number of batches 是不同的。
BATCH 是什么?
在不能将数据一次性通过神经网络的时候,就需要将数据集分成几个 batch。
正如将这篇文章分成几个部分,如介绍、梯度下降、Epoch、Batch size 和迭代,从而使文章更容易阅读和理解。
迭代
理解迭代,只需要知道乘法表或者一个计算器就可以了。迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,batch 数和迭代数是相等的。
比如对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
原文链接:https://medium.com/towards-data-science/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


