单GPU实现20Hz在线决策,最新基于序列生成模型的高效轨迹规划方法解读
机器之心转载
本文将VQ-VAE作为轨迹生成的基础模型,最终得到了一个能高效采样和规划,并且在高维度控制任务上表现远超其它基于模型方法的新算法TAP(Trajectory Autoencoding Planner)。

-
项目主页:https://sites.google.com/view/latentplan -
论文主页:https://arxiv.org/abs/2208.10291
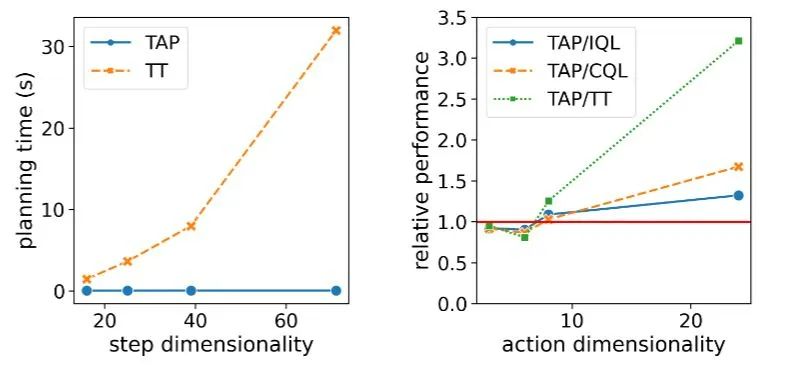
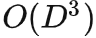 ,Diffusser 理论上会线性增长
,Diffusser 理论上会线性增长
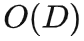 ,而 TAP 的决策速度则不受维度影响
,而 TAP 的决策速度则不受维度影响
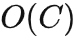 。
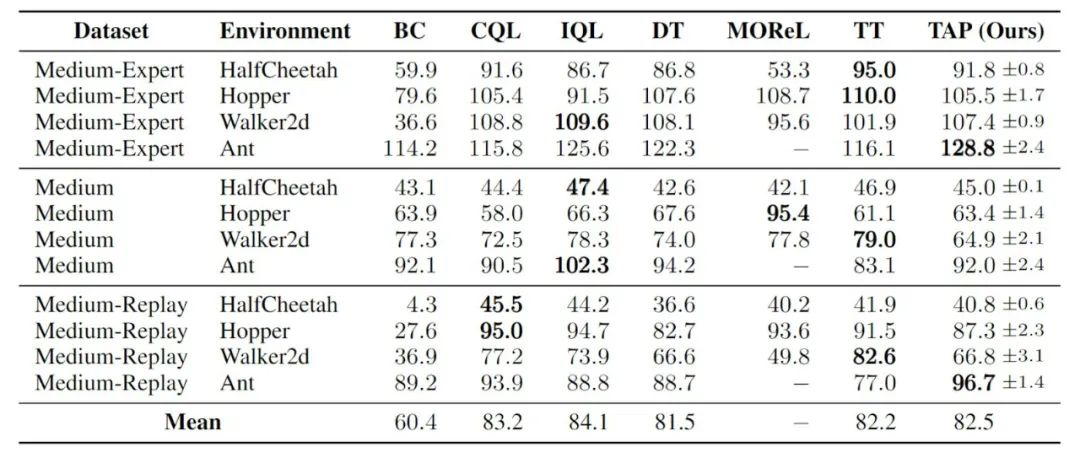
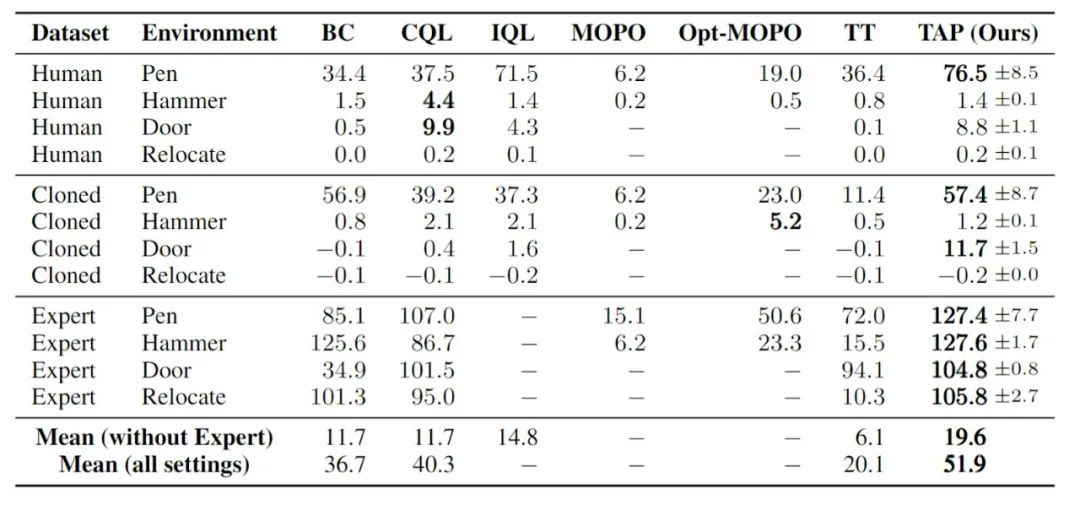
而在智能体的决策表现方面,随着动作维度增高,TAP 相对于其它方法的表现出现了提升,相对于基于模型方法(如 TT)的提升尤为明显。
。
而在智能体的决策表现方面,随着动作维度增高,TAP 相对于其它方法的表现出现了提升,相对于基于模型方法(如 TT)的提升尤为明显。

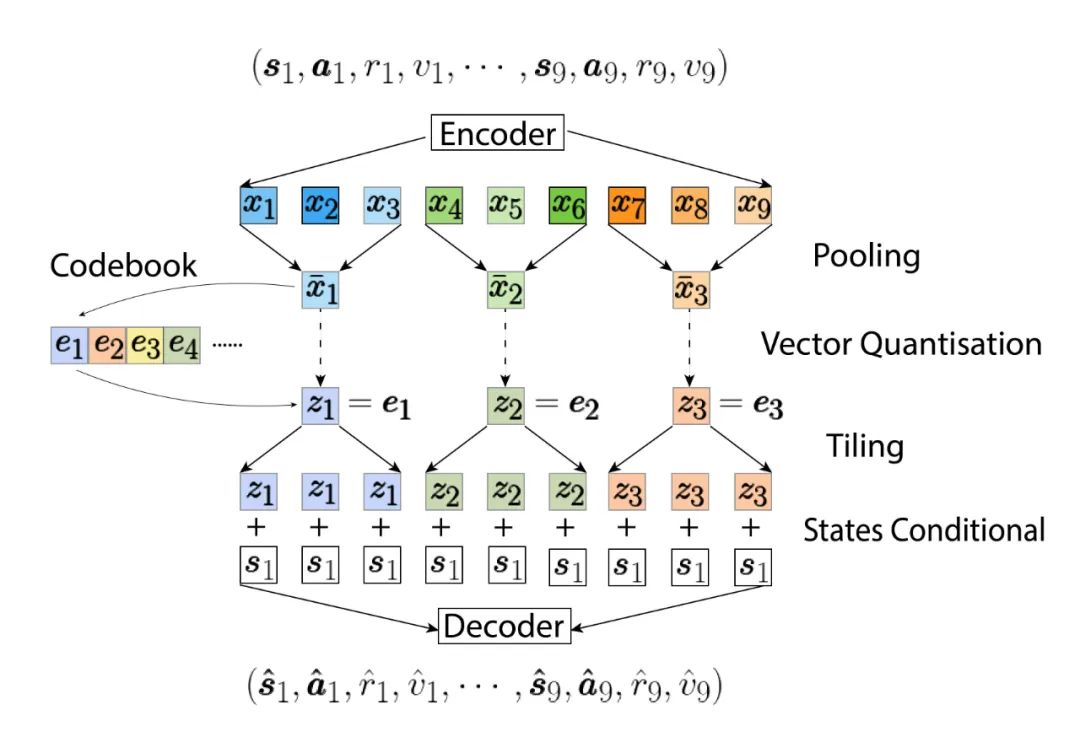
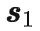 出发。
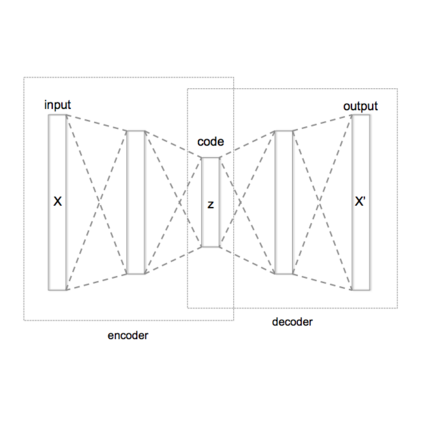
自编码器学习一个从当前状态
开始的轨迹和隐编码(latent codes)之间的双向映射。
这些隐编码和原本轨迹一样按时间顺序排列,每个隐编码会被对应到实际
出发。
自编码器学习一个从当前状态
开始的轨迹和隐编码(latent codes)之间的双向映射。
这些隐编码和原本轨迹一样按时间顺序排列,每个隐编码会被对应到实际
 步轨迹。
因为我们使用了 Causal Transformer,时间排位靠后的隐编码 (如
步轨迹。
因为我们使用了 Causal Transformer,时间排位靠后的隐编码 (如
 ) 不会将信息传到排位靠前的序列(如
) 不会将信息传到排位靠前的序列(如
 ),这使得 TAP 可以通过前 N 个隐编码部分解码出长度为 NL 的轨迹,这在后续用它
进行规划时是非常有用的。
),这使得 TAP 可以通过前 N 个隐编码部分解码出长度为 NL 的轨迹,这在后续用它
进行规划时是非常有用的。
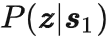 :
:
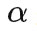 是一个远大于最高 return 的数,当轨迹的概率高于一个阈值
是一个远大于最高 return 的数,当轨迹的概率高于一个阈值
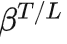 ,评判这条轨迹的标准会是它的预期收益(红色高亮),否则这条轨迹的概率本身将会是主导部分(蓝色高亮)。
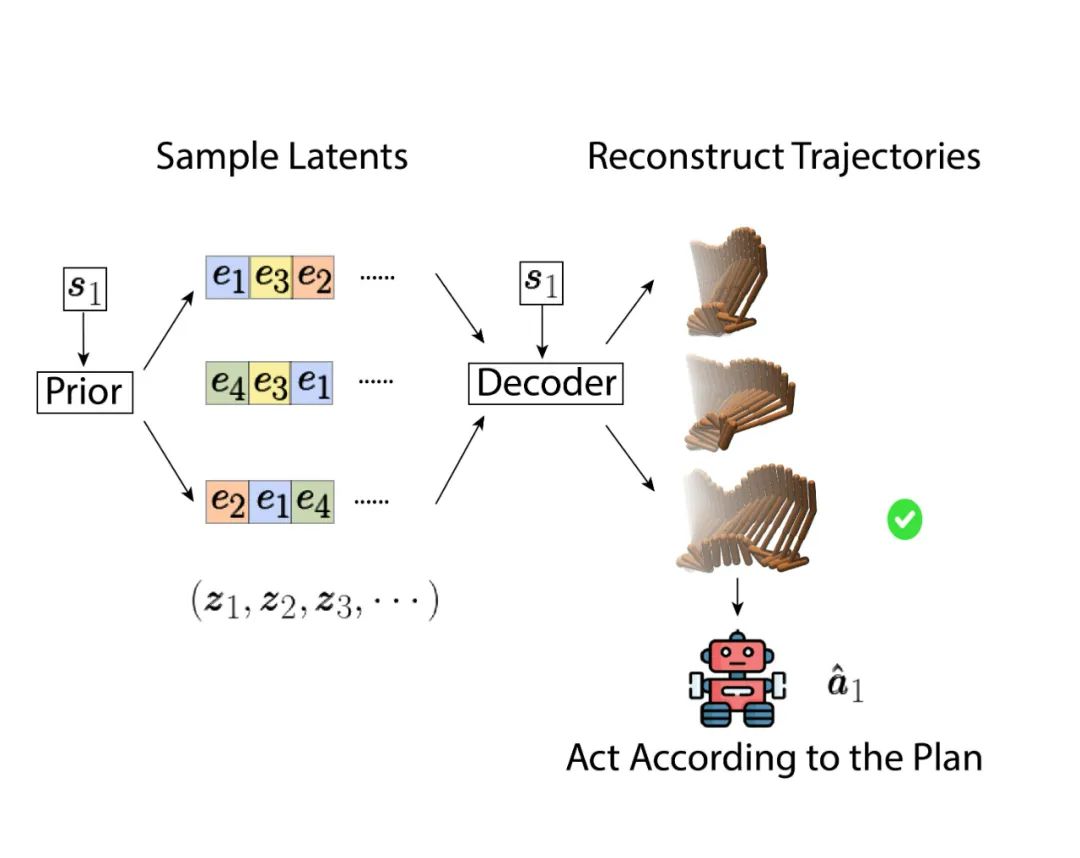
也就是说 TAP 会在大于阈值的轨迹中选择一条预期收益最高的。
,评判这条轨迹的标准会是它的预期收益(红色高亮),否则这条轨迹的概率本身将会是主导部分(蓝色高亮)。
也就是说 TAP 会在大于阈值的轨迹中选择一条预期收益最高的。
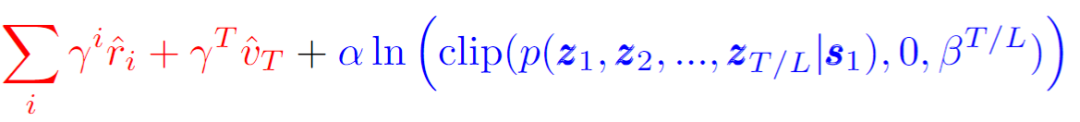


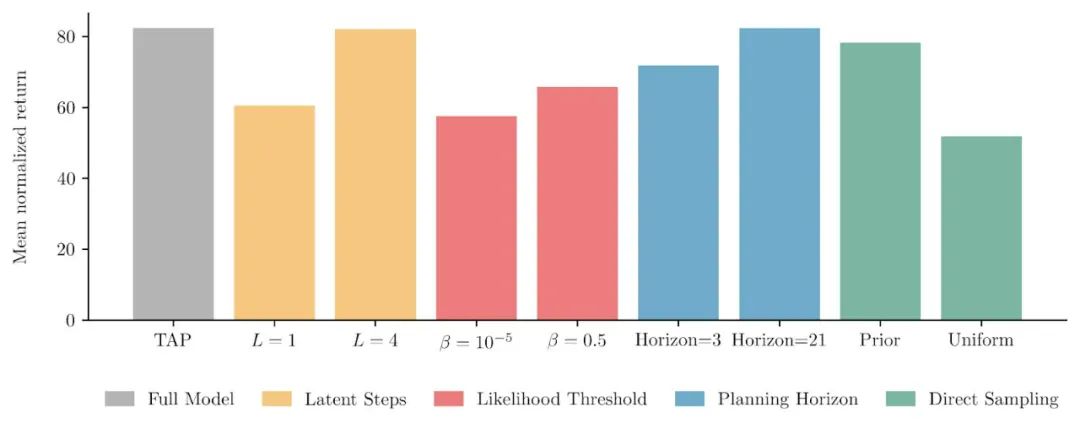
 (黄色柱状图),事实证明让一个隐变量对应多步状态转移不光有计算上的优势,在最后模型表现上也有提升。
通过调节搜索的目标函数中触发低概率轨迹惩罚的阈值
(黄色柱状图),事实证明让一个隐变量对应多步状态转移不光有计算上的优势,在最后模型表现上也有提升。
通过调节搜索的目标函数中触发低概率轨迹惩罚的阈值
 (红色柱状图),我们也确认了目标函数中两个部分确实都对模型最后表现是有帮助的。
另外一点就是向未来规划的步数(planning horizon,蓝色柱状图)对模型表现的影响反而不大,在部署后的搜索中哪怕只展开一个隐变量最后智能体的表现也只会降低 10% 左右。
(红色柱状图),我们也确认了目标函数中两个部分确实都对模型最后表现是有帮助的。
另外一点就是向未来规划的步数(planning horizon,蓝色柱状图)对模型表现的影响反而不大,在部署后的搜索中哪怕只展开一个隐变量最后智能体的表现也只会降低 10% 左右。
掌握「声纹识别技术」:前20小时交给我,后9980小时……
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

ACM应用感知TAP(ACM Transactions on Applied Perception)旨在通过发表有助于统一这些领域研究的高质量论文来增强计算机科学与心理学/感知之间的协同作用。该期刊发表跨学科研究,在跨计算机科学和感知心理学的任何主题领域都具有重大而持久的价值。所有论文都必须包含感知和计算机科学两个部分。主题包括但不限于:视觉感知:计算机图形学,科学/数据/信息可视化,数字成像,计算机视觉,立体和3D显示技术。听觉感知:听觉显示和界面,听觉听觉编码,空间声音,语音合成和识别。触觉:触觉渲染,触觉输入和感知。感觉运动知觉:手势输入,身体运动输入。感官感知:感官整合,多模式渲染和交互。
官网地址:http://dblp.uni-trier.de/db/journals/tap/
Arxiv
0+阅读 · 2022年11月22日
Arxiv
15+阅读 · 2020年2月28日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月22日
Arxiv
15+阅读 · 2020年2月28日