

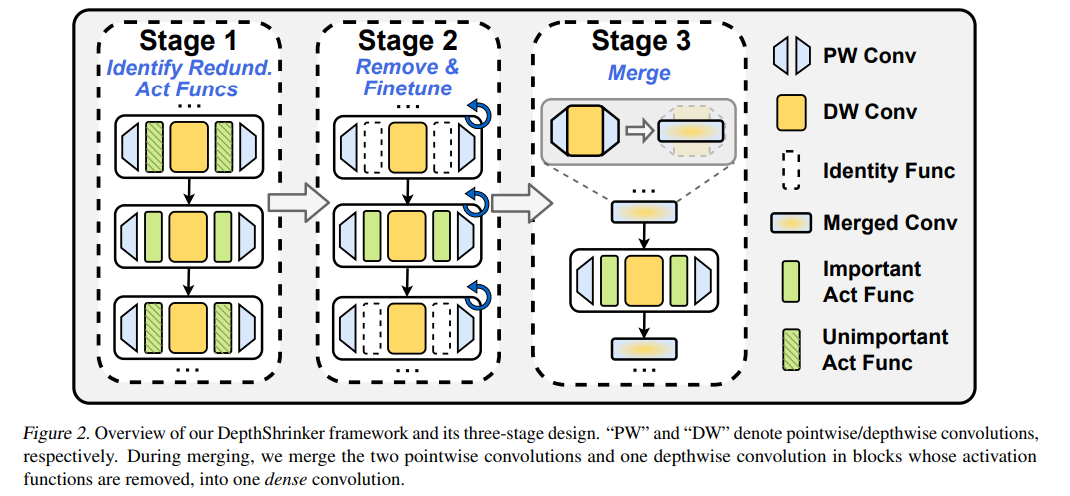
配备紧凑算子(如深度卷积)的高效深度神经网络(DNN)模型在降低DNN的理论复杂性(如权重/操作的总数)同时保持良好的模型精度方面显示出了巨大的潜力。然而,现有的高效DNN在提高实际硬件效率方面仍然有限,原因是其通常采用的紧凑算子的硬件利用率较低。在这项工作中,我们为开发真正硬件高效的DNN开辟了一种新的压缩范式,从而在保持模型准确性的同时提高硬件效率。有趣的是,我们观察到,虽然一些DNN层的激活函数有助于DNN的训练优化和达到精度,但训练后可以适当地去除它们,而不影响模型的精度。受此启发,提出了一种深度收缩框架DepthShrinker,通过将现有高效且具有不规则计算模式的深度神经网络的基本模块收缩为密集的基本模块,开发硬件友好的紧凑网络,大大提高了硬件利用率,从而提高了硬件效率。令人兴奋的是,我们的DepthShrinker框架提供了硬件友好的紧凑网络,性能优于最先进的高效DNN和压缩技术,例如,在特斯拉V100上比SOTA通道修剪方法MetaPruning更高3.06%的精度和1.53×吞吐量。我们的代码可以在https://github.com/RICEEIC/DepthShrinker上找到。
成为VIP会员查看完整内容
相关内容

Arxiv
1+阅读 · 2022年7月15日
Arxiv
14+阅读 · 2021年2月16日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2022年7月15日
Arxiv
14+阅读 · 2021年2月16日