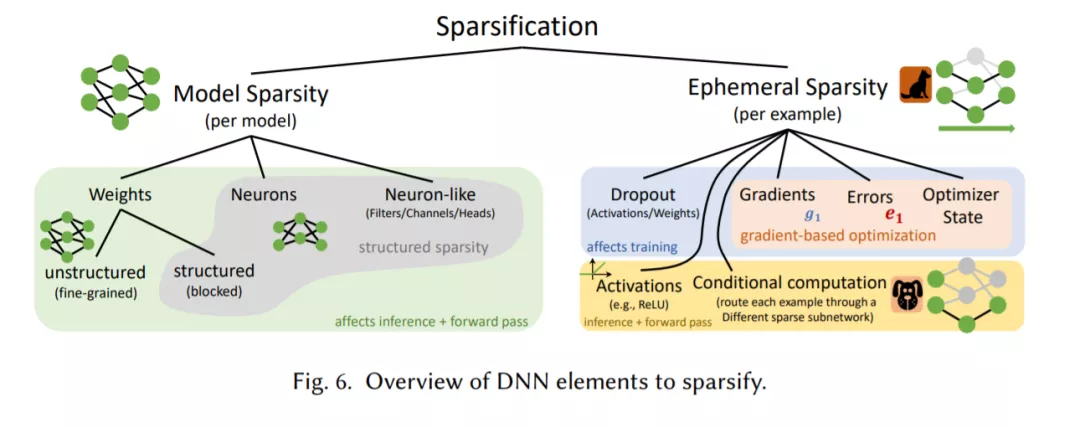
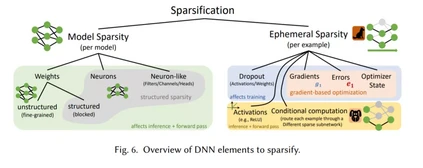
深度学习不断增长的能源耗费和性能成本,促使社区通过选择性修剪组件来减少神经网络的规模。与生物学上的相似之处是,稀疏网络即使不能比原来的密集网络更好,也能得到同样好的推广。稀疏性可以减少常规网络的内存占用,以适应移动设备,也可以缩短不断增长的网络的训练时间。在本文中,我们调研了深度学习中的稀疏性之前的工作,并为推理和训练提供了一个广泛的稀疏化教程。我们描述了去除和添加神经网络元素的方法,实现模型稀疏性的不同训练策略,以及在实践中利用稀疏性的机制。我们的工作从300多篇研究论文中提炼思想,并为希望利用稀疏性的实践者提供指导,以及为目标是推动前沿发展的研究人员提供指导。我们在稀疏化中包括必要的数学方法背景,描述诸如早期结构适应、稀疏性和训练过程之间的复杂关系等现象,并展示在真实硬件上实现加速的技术。我们还定义了一个修剪参数效率的度量,可以作为不同稀疏网络比较的基线。最后,我们推测稀疏性如何改善未来的工作,并概述该领域的主要开放问题。
在计算机视觉、自然语言处理、知识表示、推荐系统、药物发现等领域,深度学习在解决非常复杂的现实世界问题方面展现了无与伦比的前景。随着这一发展,机器学习领域正从传统的特征工程向神经结构工程发展。然而,对于如何选择正确的架构来解决特定的任务,我们仍然知之甚少。在模型设计中,采用了卷积层中的平移等方差、递归、结构权重共享、池化或局部化等方法来引入强归纳偏差。然而,任务所需的精确模型大小和容量仍然未知,一个常见的策略是训练过度参数化的模型,并将它们压缩成更小的表示。
生物的大脑,特别是人类的大脑,是分层的、稀疏的和周期性的结构[Friston 2008],我们可以得出一些类似于今天人工神经网络中的归纳偏差。稀疏性在生物大脑的缩放中扮演着重要的角色——大脑的神经元越多,大脑就越稀疏[Herculano-Houzel et al. 2010]。此外,研究表明,人类的大脑开始稀疏,在大量修剪之后有一个致密化的早期阶段,然后保持在一个相对稳定的稀疏水平。然而,即使是完全发育成熟的大脑,每天也会改变多达40%的突触[Hawkins 2017]。许多今天的工程修剪技术具有直观的生物学类比,我们将在整篇文章中提到并在第8节讨论。然而,计算基质(生物组织和CMOS)导致了非常不同的限制。
人工深度学习模型传统上是密集和过度参数化的,有时甚至可以记忆数据中的随机模式[Zhang et al. 2017],或者95%的参数可以从剩余的5%中预测出来[Denil et al. 2014]。这可能与经验证据有关,表明使用随机梯度下降(SGD)训练过度参数化模型比使用更紧凑的表示更容易Glorot et al. 2011a; Kaplan et al. 2020; Li et al. 2020a; Mhaskar and Poggio 2016]. Brutzkus et al. [2017] 和Du et al. [2019]表明,这种梯度下降技术可证明以良好的泛化最优地训练(浅)过参数化网络。具体来说,他们指出,过度参数化会导致一种强大的“类凸性”,这有利于梯度下降的收敛性。最近的理论结果[Allen-Zhu et al. 2019; Neyshabur et al. 2018]似乎支持这些发现,并指出训练动力学和泛化依赖于过度参数化。
这种过度参数化是以模型训练和推理过程中额外的内存和计算工作为代价的。特别是,对于移动设备和电池驱动设备的推理,以及在成本意识较强的环境下,稀疏模型表示可以带来巨大的节省。具体地说,稀疏模型更容易存储,并且常常节省计算量。此外,过度参数化的模型往往会过度拟合数据,并降低泛化到看不见的例子。紧跟着Occam 's razor,稀疏化也可以看作是某种形式的正则化,可以通过有效降低模型中的噪声来提高模型质量。具体来说,最小描述长度框架提供了一个具有贝叶斯解释和数据压缩清晰解释的吸引人的公式[Grünwald 2007],我们稍后会讨论。
许多工作,特别是老的工作,集中在通过稀疏化改进泛化。早期的研究[Mozer和Smolensky 1988]关注的是具有数十到数百个参数的模型,也说明了它们的简化版本有更好的可解释性。然而,随着今天的模型使用数百万或数十亿个参数,稀疏性是否会显著提高可解释性和可解释性就有待观察了。Bartoldson等人[2020]最近的工作将剪枝作为“噪声”,类似于dropout或数据增强来解释泛化。其他近期的研究发现,稀疏性可以提高对抗对抗攻击的鲁棒性[Cosentino et al. 2019; Gopalakrishnan et al. 2018; Guo et al. 2018; Madaan et al. 2020; Rakin et al. 2020; Sehwag et al. 2020; Verdenius et al. 2020]。
最近,一组更大的工作集中在提高计算效率的同时保持模型的精度。现代网络在计算上的使用是昂贵的——例如,Inception-V3 [Szegedy等人2016],一个最先进的目标识别网络,需要57亿次算术运算和2700万个参数进行评估;GPT-3 [Brown et al. 2020],一种最先进的自然语言处理网络的实验状态需要1750亿个参数(350 GiB,假设每个参数16位)来评估。此外,训练这样的深度神经模型变得越来越昂贵,而且最大的语言模型已经需要超级计算机进行训练,每次训练可能要花费数百万美元[Brown等人2020]。因此,研究训练过程中的稀疏性对于管理训练成本是非常重要的。
我们综述的结果表明,今天的稀疏化方法可以导致模型尺寸减少10-100倍,并在计算、存储和能源效率方面获得相应的理论收益,而不会显著降低精度。如果这些加速是在高效的硬件实现中实现的,那么所获得的性能可能会导致一个阶段的变化,使更复杂的、可能是革命性的任务得到实际解决。此外,我们还观察到,在稀疏化方法方面的进展速度正在加快,因此,即使在我们编写本论文的最后几个月里,也发表了一些改进现有技术的新方法。
我们的目标是总结现有的技术,并且在第2-5节首先关注设计模型的纯定性方面。然后,在第6节和第7节中,我们将解释实现这些设计组合的架构选择,包括性能结果。