RGB-T新添高质量的大型基准?卢湖川团队提出一个大规模高分辨率的帧级数据集

极市导读
这篇文章中作者构建了一个用于可见热UAV跟踪(VTUAV)的大规模高分辨率的帧级数据集,其中包括500个分辨率为1920∗ 1080图像序列帧对,很好的弥补了目前RGB-T工作中缺少数据的问题。此外本文还提出了一套结合RGB与Thermal模态信息的融合策略(HMFT)。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
和往年一样,今年也有一些Thermal的mulit-modal的工作被CVPR接收,和上年一样,大约是2~3篇左右。作为Thermal的半专业玩家,想给大家带来最新的RGB-Thermal上面的工作,希望更多的朋友可以加入到热红外(Thermal)赋能RGB图像的工作中来,让我们一起探寻可见光背后的世界,另外我最近在筹备着写篇Thermal语义分割相关的文章,如果有老师或者大佬感兴趣想一起加入工作中来的话,非常欢迎加入,一起讨论。

这次那么这次就挑RGB-Thermal(RGB-T) + Tracking这个话题来聊一聊

文章地址:https://arxiv.org/abs/2204.04120
代码链接:https://zhang-pengyu.github.io/DUT-VTUAV/
说在前面的话
RGB-Thermal(以下简称RGB-T)这个工作无论是在这篇文章中的Tracking,亦或是在人群计数,街景语义分割,夜景的目标检测中都有一个非常大的问题,就是缺数据。缺数据是目前RGB-T没有办法像RGB-D一样更为人知的原因之一,在缺少数据的情况下,整体训练的效果不尽如人意,我们也无法对于RGB-T进行进一步的探索和研究。这篇文章中作者构建了一个用于可见热UAV跟踪(VTUAV)的大规模高分辨率的帧级数据集,其中包括500个分辨率为1920∗ 1080图像序列帧对,此外本文还提出了一套结合RGB与Thermal模态信息的融合策略(HMFT)。

上图展示了摄像机移动、目标形变、极端照明、部分遮挡、完全遮挡、尺度变化、低分辨率等分别在RGB和Thermal模态中出现的图像数据信息不完整的问题,就比如在可视环境差的时候RGB无法有效识别,但是在Thermal可以有效的识别出来。在热聚集的区域,Thermal就会对整个热聚集区域产生响应,但是RGB则不会受此干扰依然保证完整信息。通过RGB与Thermal相互间的信息互补可以达到较为完整的图片信息效果。浪漫主义一点来说就是”相互扶持,相互成就“。
文章的主要贡献以及取得的成绩
本文主要做出的贡献概括起来主要就是两点
1、提出了一个高质量的数据集,高质量体现在:数据质量高、数据量高这两个方面,可以算是标杆级别的数据集了。
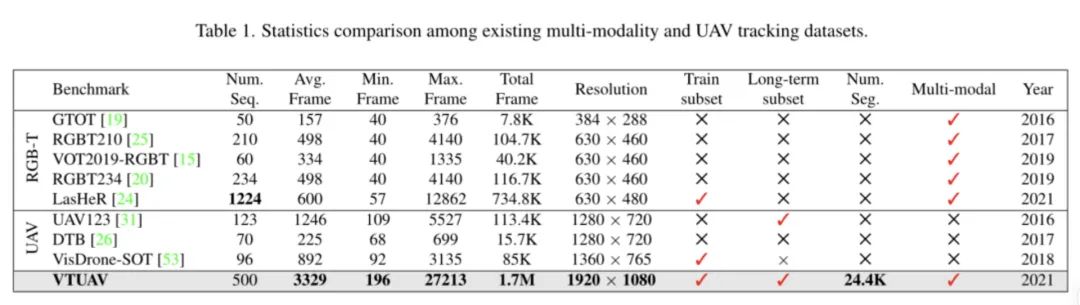
2、提出了一种多模态的融合方法——HMFT。一种包括了图像融合、特征融合和决策融合的新型多模态决策融合的架构。在速度上保持T-3行列内的情况下,依旧屠了3个数据集的榜单,涨点效果相当的不错。
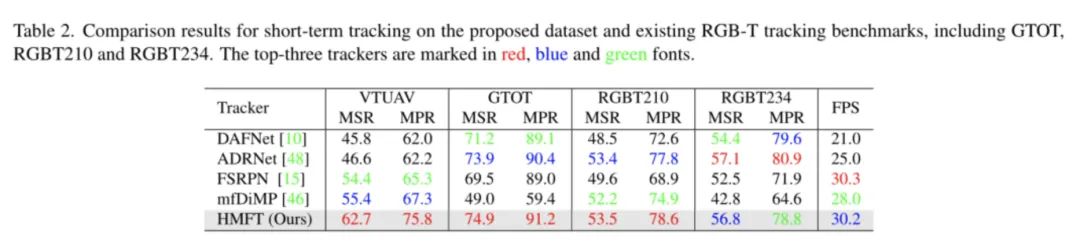
数据集分析
RGB-T的图像采集会有多种方式,一种是使用RGB相机+Thermal成像仪的组合方向进行采集,另一种是采用RGB-Thermal一体式的相机进行工作。文章使用的是第二种的方式,采用了大疆的 DJI Matrice 300 RTK UAV 无人机搭禅思 Zenmuse H20 系列RGB-Thermal相机进行拍摄。(@DJI大疆创新 我这边也是做RGB-Thermal,能不能谈谈合作啊!)大疆的无人机大家可以放心,在夜间,在极端的环境下都可以完成平稳的飞行(大风、大雾、黑夜)都没有问题。数据的采集高度在5-20m,所以大家要注意一点,我们需要识别的目标有可能由于size是比较多样化的。
此外,本文所提出的数据集相较于以往的标签注释,要更加多样化一点。还提出了13个挑战,也就是上文说到的目标模糊(TB)、摄像机运动(CM)、极端照明(EI)、变形(DEF)、部分遮挡(PO)、完全遮挡(FO)、尺度变化(SV)、热交叉(TC)、快速移动(FM)、背景聚类(BC)、视野外(OV)、低分辨率(LR)和热可见分离(TVS)。总结的这些挑战其实涵盖了很多情况下Thermal和RGB模态之间的GAP,我觉得是目前为止我看见过的RGB-T工作中把问题整理得最细的工作了。
因为不同模态之间的成像原理不一致,导致的物体时空分布不一致的问题,作者也通过了一些手段方式完成了配准和对齐,所以大家follow工作的时候可以放心大胆的使用数据集。
此外作者还提供了边界框、分割掩码和类别注释这些不同任务的labels,分别去适配不同的视觉任务,这一点可谓是圈粉之极。
HMFT结构
HMFT结构,它包括三个主要模块:互补图像融合(CIF)、判别特征融合(DFF)和自适应决策融合(ADF),其中CIF主要学习两个模态之间的共享信息,DFF主要是对于通道组合进行进行筛选,ADF主要是选择出合适的候选分类目标。
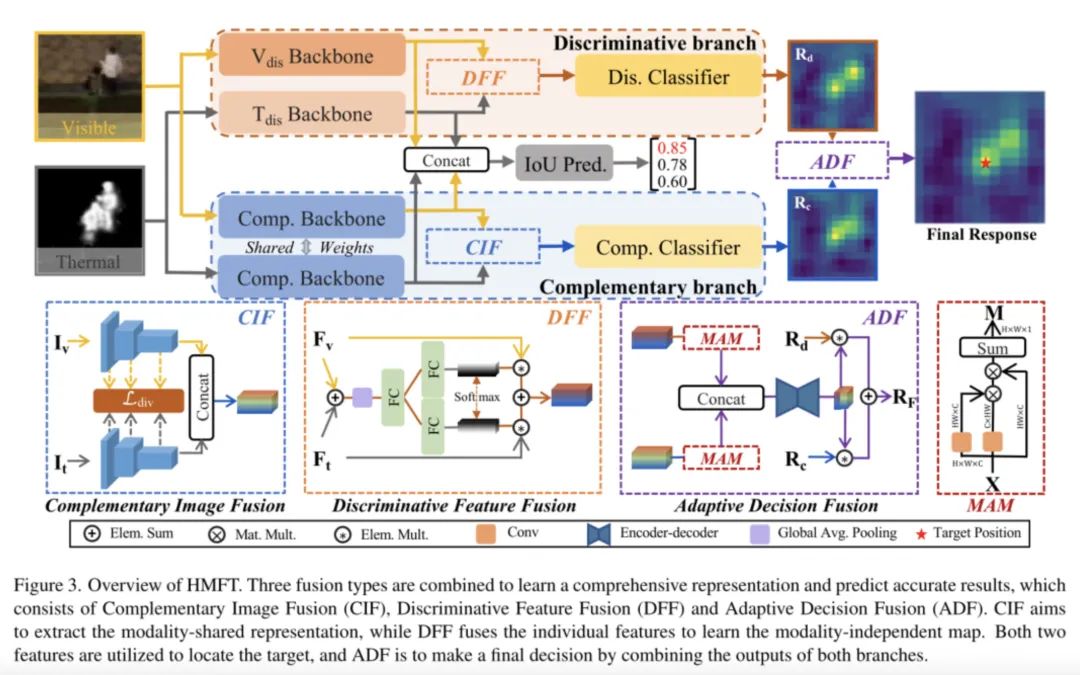
CIF结构
CIF是将两个模态的分支分别输入到ResNet50的骨干分支中,相互交换信息,交换信息的过程通过Ldiv(散度函数)进行控制,强制两个模态之间的模态分布一致。
Ldiv数学模型表达
DFF结构
DFF主要的做法就是决策融合,通过FC层得到的权重进行加权决策融合。加权融合的目的在于充分发挥各自模态的特点,考虑到不同模态对于不同信息的相应程度不一样,我们尽可能的保留有用的交互信息,排除掉无用的信息。但是可能我会觉得DFF的做法未必可以提供有效的加权方式,通过直接叠加后经过全局平均池化层后再通过FC层转化为权重。其实GAP—>FC—>FC的做法其实和SELayer中计算相应权重是一致的,这点比较容易大家都可能会比较容易看出来。但是后面的Softmax的做法我个人觉得除了把权重内容锁定在1之中,保证两个模态的交互的稳定性之外还有没有什么别的设计,我还没有想到,如果又想到的uu,欢迎告诉我~
ADF结构
对于CIF方式和DFF方式哪种方式会更适合模态融合呢?ADF会告诉我们。ADF是一个自适应的模块,根据CIF和DFF的模态置信度进行融合,MAM是一种自注意力网络,产生模态置信度Md和Mc,全局化的检索模态信息。
MAM部分数学原理
MAM通过1X1卷积对两个模式的特征融合信息进行整合,通过置信的方式进行进一步锁定和抉择出目标位置。给CIF和DFF一个交代,也是最后一个阶段的融合。
实验细节
先说大家感兴趣的:HMFT在Pytorch平台上实现,并在单个Nvidia RTX Titan GPU和24G内存上运行。在泰坦上跑起来的,所以有3090的伙伴们就可以直接上手了。
文章使用的loss函数
文章在不同阶段种使用了不同的损失函数作为约束,采用了加权融合loss的方式,对于不同结构(DFF、ADF)使用的不同学习率进行学习,可谓是tricks十足的意味。实验部分的话并未有很值得借鉴的地方,如果大家想复现实验的话,大家可以继续研究一下细节的优化,我这里粗略看完之后,在实验部分有进一步的工程优化的可能性,但是也仅限于工程优化,进一步的网络优化思路,大家可以接着往下看。

总结
文章中做了一个大规模数据集,而且细节完整,评估指标更加完善,最后提出来HFMT的多模态融合方案。其实我觉得HFMT的多模态融合方法似乎是对近期的加权的融合以及合并融合进行一个继承发展,最核心的novelty可能集中在ADF的自适应选择融合方式中,这对于应该模态concat融合,还是应该加权融合给出自己的思路和解决方法,我觉得是值得肯定的。
但是对于多模态图像融合工作如何更加简约上我觉得还需要下功夫,自适应区分CIF好还是DFF好的一体化方案,本质上是一体化,但是实际上还是经过了多个stages,对于实时性而言依旧有所挑战,结构也不简约,所以我觉得未来我们需要努力的方向,更多是简约高效的一体化方案。但是无可否认,这个工作所来的思考是值得我们进一步学习的。
公众号后台回复“项目实践”获取50+CV项目实践机会~

# 极市平台签约作者#

matrix明仔
知乎:战斗系牧师
一个希望百发百中CCF-A的在读美食爱好者
研究领域:目标检测、语义分割、多模态感知融合
(RGB、Thermal、Depth、Ldair等不同模态下感知信息间的决策与融合)
作品精选

“
点击阅读原文进入CV社区
收获更多技术干货

