深度学习与计算机视觉任务应用综述
Mask- RCNN进行目标检测(Object detection)和实例分割(instance segmentation)
想做计算机视觉吗?深度学习是当今技术发展的方向。大规模数据集加上深度卷积神经网络( CNNs )强大的表达能力,形成了超精确和鲁棒的模型。只有一个挑战仍然存在:如何设计你的模型。
对于像计算机视觉这样广泛和复杂的领域,解决方案并不总是清晰的。计算机视觉中的许多标准任务都需要特别考虑:分类(classification)、检测(detection)、分割(segmentation)、姿态估计(pose estimation)、增强和恢复(enhancement and restoration)以及动作识别(action recognition)。尽管用于每一个最先进的网络具有了共同的模式(结构),但是它们都需要自己独特的结构设计。
那么,我们如何为所有这些不同的任务建立模型呢?让我向你展示如何用深度学习来完成计算机视觉中的所有事情!
分类(classification)
其中最著名的!图像分类网络从固定大小的输入开始。输入图像可以有任意数量的通道(channels),但是对于RGB图像通常是3个。当你设计你的网络时,分辨率在技术上可以是任何大小,只要它足够大,可以支持你在整个网络中进行的下采样(downsampling)。例如,如果你在网络中进行4次下采样,那么你的输入至少需要4 = 16×16像素大小。
随着你的网络变得更深,空间分辨率将会降低,因为我们试图压缩所有的信息,并得到一维向量表示。为了确保网络始终有能力传送它提取的所有信息,我们根据深度成比例地增加特征图(feature map)的数量,以适应空间分辨率的降低。也就是说,我们在下采样过程中丢失了空间信息,为了弥补这一损失,我们扩展了特征图以增加语义信息。
在你选择了一定量的下采样后,特征图将被矢量化并馈送到一个全连接网络中。最后一层的输出与数据集中的类别数量一样多。

目标检测(Object Detection)
目标检测有两种类型:一阶和二阶。两者都从“anchor boxes”开始;这些是默认边界框。我们的检测器(detector)0将预测这些boxes和真是object之间的差异,而不是直接预测这些boxes。
在二阶检测器中,我们有两个网络:一个box proposal网络和一个分类网络。box proposal网络为给出boxes的边界;相当于标出boxes。然后,分类网络获取这些边框中的内容,并对其中的潜在对象进行分类。
在一阶检测器中,proposal和分类器网络融合成一个网络。网络直接预测边界框坐标和位于该框内的物体类别。因为两个阶段融合在一起,所以一阶检测器往往比两级检测器更快。但是由于两个任务的分离,两阶检测器具有更高的精度。
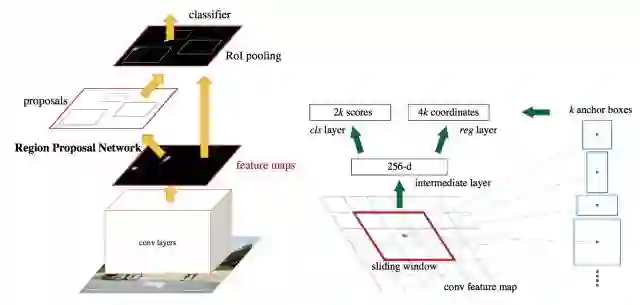
Faster-RCNN二阶目标检测体系结构

SSD一阶目标检测体系结构
分割(Segmentation)
分割是计算机视觉中比较独特的任务之一,因为网络需要学习低级和高级信息。按像素精确分割图像中每个区域和对象的低级信息,以及直接对这些像素进行分类的高级信息。这导致网络被设计成将浅层的信息和high-resolution(低纬空间信息)与更深层和low-resolution(高级语义信息)相结合。
正如我们在下面看到的,我们首先通过标准分类网络处理我们的图像。然后,我们从网络的每个阶段提取特征,从而使用从低到高的信息。每个信息级别在依次将它们组合在一起之前都是独立处理的。随着信息的组合,我们对feature map进行了上采样(upsample),以最终获得完整的图像。
要了解关于深度学习如何进行图像分割的更多细节,请查看本文:https://towardsdatascience.com/semantic-segmentation-with-deep-learning-a-guide-and-code-e52fc8958823。
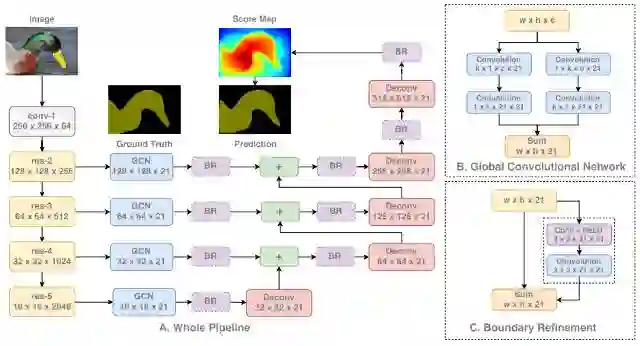
GCN 图像分割体系结构
姿态估计(Pose Estimation)
姿势估计模型需要完成两项任务: ( 1 )检测图像中每个身体部位的关键点( 2 )找出如何正确连接这些关键点。这分三个阶段完成:
( 1 )使用标准分类网络从图像中提取特征
( 2 )给定这些特征,训练一个子网络来预测一组2D热图。每个热图与一个特定的关键点相关联,并且包含每个图像像素的关于关键点是否可能存在的置信度值
( 3 )再次给定分类网络的特征,训练一个子网络来预测一组2D矢量场(vector fields),其中每个矢量场编码关键点之间的关联程度。然后,具有高关联度的关键点被认为是相连接的。
以这种方式与子网络一起训练模型将共同优化关键点的检测,并将它们连接在一起。

开放式姿态估计体系结构
增强和恢复(Enhancement and Restoration)
增强和恢复网络是有它们自己独特的网络结构。这些网络没有进行任何下采样,因为我们真正关心的是高像素/空间精度。下采样会杀死这些信息,因为它会减少我们用于保证空间精度的像素(pixels)的数量。相反,所有处理都是直接对整张图片进行的。
首先将我们想要增强/恢复的完整的图像传送到我们的网络,而不做任何修改。网络很简单,由许多卷积和激活函数等单元组成。这些单元通常都从为图像分类开发的新技术,如残差连接单元(Residual block:https://arxiv.org/pdf/1512.03385.pdf)、全连接单元(Dense block:https://arxiv.org/pdf/1608.06993.pdf)、压缩激活单元(Squeeze Excitation block:https://arxiv.org/pdf/1709.01507.pdf),获得启发,通常是直接复制过来使用。最后一层没有激活函数,甚至没有sigmoid或softmax,因为我们想直接预测图像像素,不需要任何概率或分数。
这就是这类网络的全部内容!对整张图像进行大量处理,以提高精度,使用已被证明可用于其他任务的相同卷积。

EDSR超分辨率(super-Resolution)架构
动作识别(Action Recognition)
动作识别是少数几个特别需要视频数据才能正常工作的应用之一。为了对一个动作进行分类,我们需要了解场景随时间的变化;这自然导致我们需要视频。我们的网络必须同时学习捕捉空间(space)和时间(time)信息,即空间和时间的变化。这方面目前的完美网络是3D-CNN。
正如名字所暗示的,3D - CNN是一个使用3D卷积的卷积网络!不同于传统的CNNs,3D卷积应用于三维场景:宽度(width)、高度(height)和时间(time)。因此,每个输出像素都是根据基于其周围像素以及相同位置的前一帧和后一帧中的像素的计算来预测的!
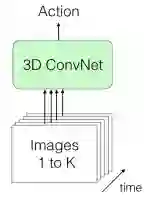
直接输入large batch图像
视频帧(video frame)可以通过几种方式传递:
( 1 )直接以large batch的形式,如第一个图所示。因为我们正在传递一系列帧,所以空间和时间信息都是可用的
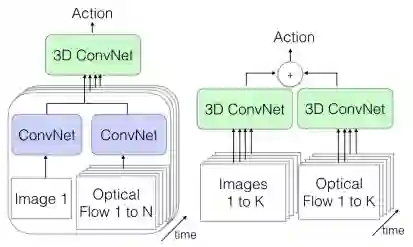
单帧+光流(optical flow)(左);视频+光流(右)
( 2 )我们也可以在一个流中传递单个图像帧(数据的空间信息)及其对应的视频光流表示(数据的时间信息)。我们将使用常规的2D CNN从这两者中提取特征,然后将它们合并到我们的3D CNN中,3D CNN合并了这两种类型的信息
( 3 )将我们的帧序列传递给一个3D CNN,并将视频的光流表示(optical flow representation)传递给另一个3D CNN。这两个数据流都有可用的空间和时间信息。这中选择速度最慢,但准确率最高,因为改架构对所有视频的所有信息的两种不同表示同时进行特定处理。
所有这些网络都输出视频的动作的类别。
往期精品内容推荐
Geffery Hinton-数字代表模型从数据中抽取的知识、AI不会有寒冬
机器学习泰斗- Michael I.Jordan-机器学习前景与挑战



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq


