23个CVPR 2020收录的新数据集,都在这里了!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

整理不易,希望点个在看或者转发,支持一下
前言
Amusi 之前整理了1467篇CVPR 2020所有论文PDF下载资源,以及300篇+CVPR 2020代码开源论文项目,详见:300+篇CVPR 2020代码开源的论文,全在这里了!
本文旨在从数据集的角度,对CVPR 2020部分论文进行整理,相信很多同学并不知道这些新数据集,也许能给你的科研带来一点帮助。数据集方向涵盖:目标检测、分割、目标跟踪、场景文本检测&识别、行为识别等方向。
目标检测
DRN:用于旋转和密集目标检测的动态优化网络
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
论文下载链接:https://arxiv.org/abs/2005.09973
代码和数据集:https://github.com/Anymake/DRN_CVPR2020
本文提出DRN新网络,并提出SKU110K新数据集。
作者团队:中科院&腾讯优图&快手等

分割
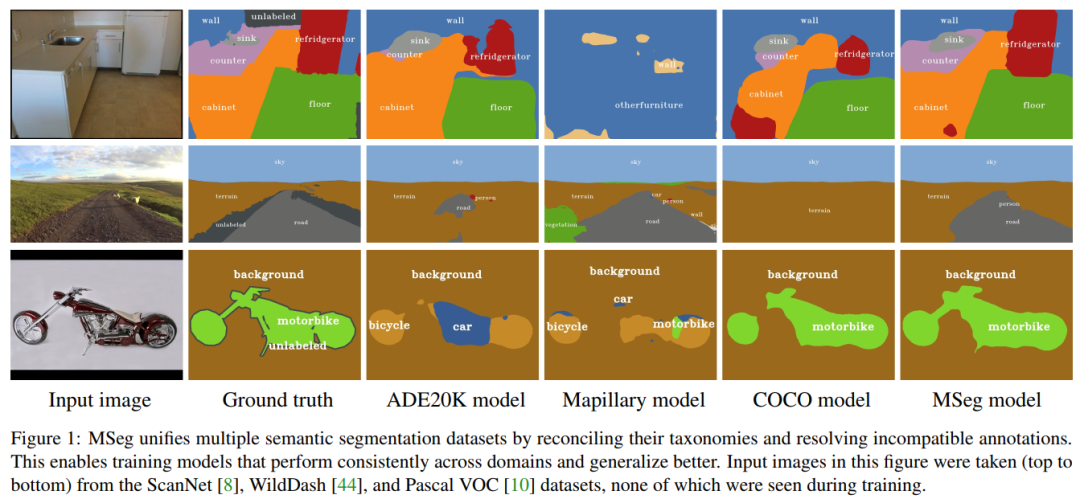
MSeg:用于多域语义分割的合成数据集
MSeg: A Composite Dataset for Multi-domain Semantic Segmentation
论文:http://vladlen.info/papers/MSeg.pdf
代码:https://github.com/mseg-dataset/mseg-api
数据集:https://github.com/mseg-dataset/mseg-semantic
该数据集汇集了COCO、ADE20K、Cityscapes、KITTI、PASCAL VOC/Context、Mapillary、SUN RGBD等语义分割数据集!现已开源!
作者团队:Intel&加州大学伯克利分校&Argo AI等
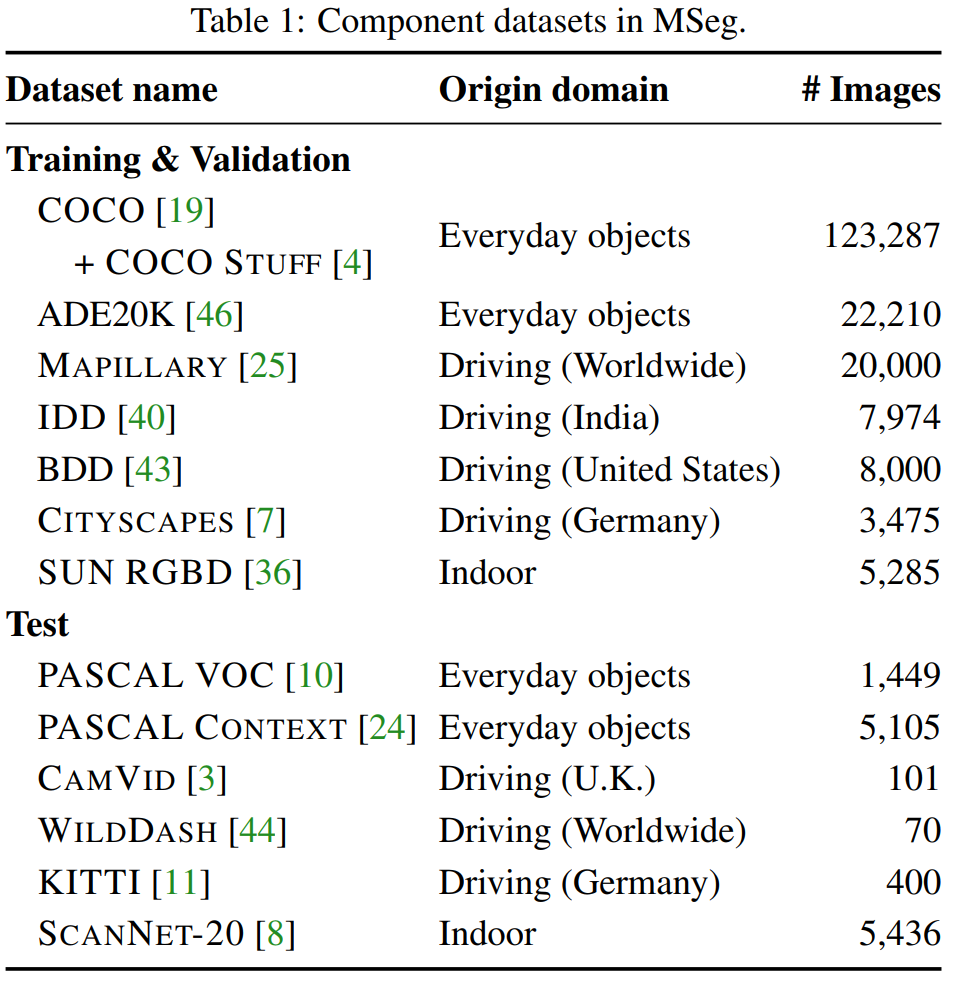
FSS-1000:用于Few-shot分割的1000种类别数据集
FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation
论文:http://openaccess.thecvf.com/content_CVPR_2020/html/Li_FSS-1000_A_1000-Class_Dataset_for_Few-Shot_Segmentation_CVPR_2020_paper.html
代码:https://github.com/HKUSTCV/FSS-1000
数据集:https://github.com/HKUSTCV/FSS-1000
共计10,000幅图像,涵盖1000种物体类别,数据集和代码现已开源!
作者团队:香港科技大学&腾讯

目标跟踪
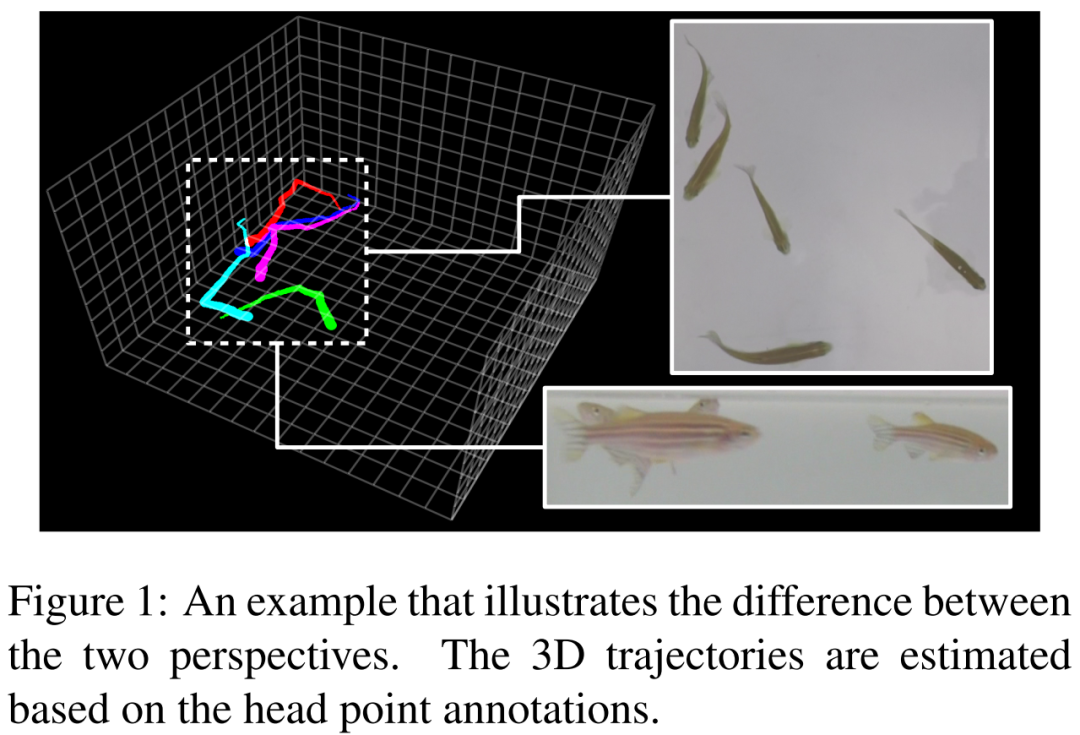
3D-ZeF:3D斑马鱼跟踪基准数据集(多目标跟踪)
3D-ZeF: A 3D Zebrafish Tracking Benchmark Dataset
主页:https://vap.aau.dk/3d-zef/
论文:https://arxiv.org/abs/2006.08466
代码:https://bitbucket.org/aauvap/3d-zef/src/master/
数据集:https://motchallenge.net/data/3D-ZeF20
数据集包含8个视频序列(2704x1520分辨率),共计86,400个点和边界框,约占14 GB,代码和数据集现已开源!
作者团队:奥尔堡大学

场景文本检测&识别
UnrealText:合成来自虚幻世界的真实场景文本图像
UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
论文:https://arxiv.org/abs/2003.10608
代码和数据集:https://github.com/Jyouhou/UnrealText/
可供多语言的场景文本检测和识别方向进一步研究,代码和数据集刚刚开源!
作者团队:CMU&旷视科技(姚聪)


视频理解/行为识别
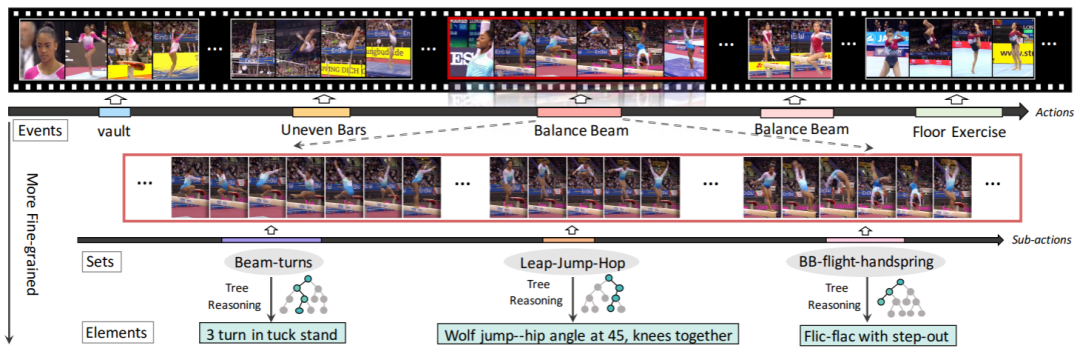
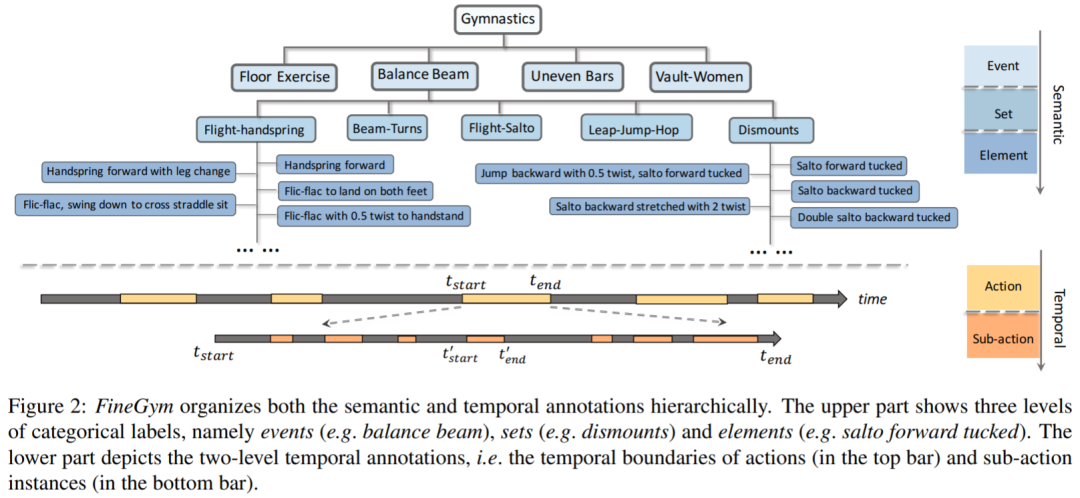
FineGym:用于细粒度行为识别的分层视频数据集
FineGym: A Hierarchical Video Dataset for Fine-grained Action Understanding
主页:https://sdolivia.github.io/FineGym/
论文:https://arxiv.org/abs/2004.06704
为了将行为识别提升到一个新的水平,本文提出了FineGym:一个基于体操视频的新数据集,含4大类事件,15种子集。数据集刚刚开源!
作者团队:港中文-商汤科技联合实验室
Oops! Predicting Unintentional Action in Video
主页:https://oops.cs.columbia.edu/
论文:https://arxiv.org/abs/1911.11206
代码:https://github.com/cvlab-columbia/oops
数据集:https://oops.cs.columbia.edu/data

Intra- and Inter-Action Understanding via Temporal Action Parsing
论文:https://arxiv.org/abs/2005.10229
主页和数据集:https://sdolivia.github.io/TAPOS/
Re-ID
COCAS:用于行人重识别的大规模换衣服数据集
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
论文:https://arxiv.org/abs/2005.07862
数据集:暂无
COCAS 包含5266人的62382幅人体图像,旨在解决换衣服的行人重识别问题,提供了具有不同衣服的相同身份的多个图像,并提出BC-Net网络。
作者团队:商汤科技&中科大&国科大等

轨迹预测
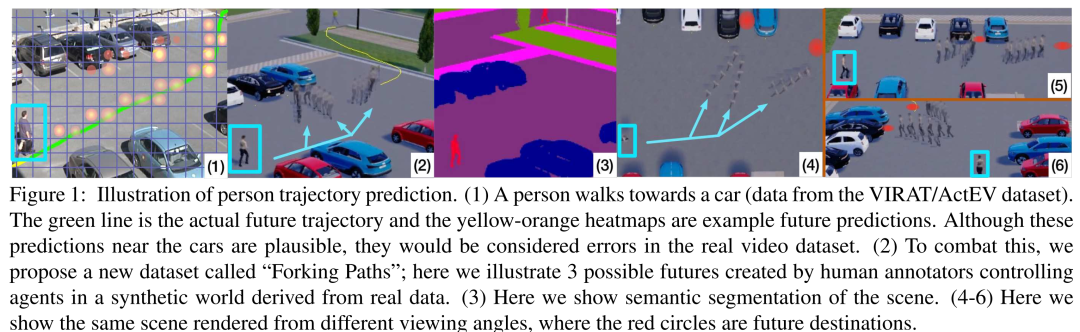
The Garden of Forking Paths: Towards Multi-Future Trajectory Prediction
论文:https://arxiv.org/abs/1912.06445
代码:https://github.com/JunweiLiang/Multiverse
数据集:https://next.cs.cmu.edu/multiverse/
其他
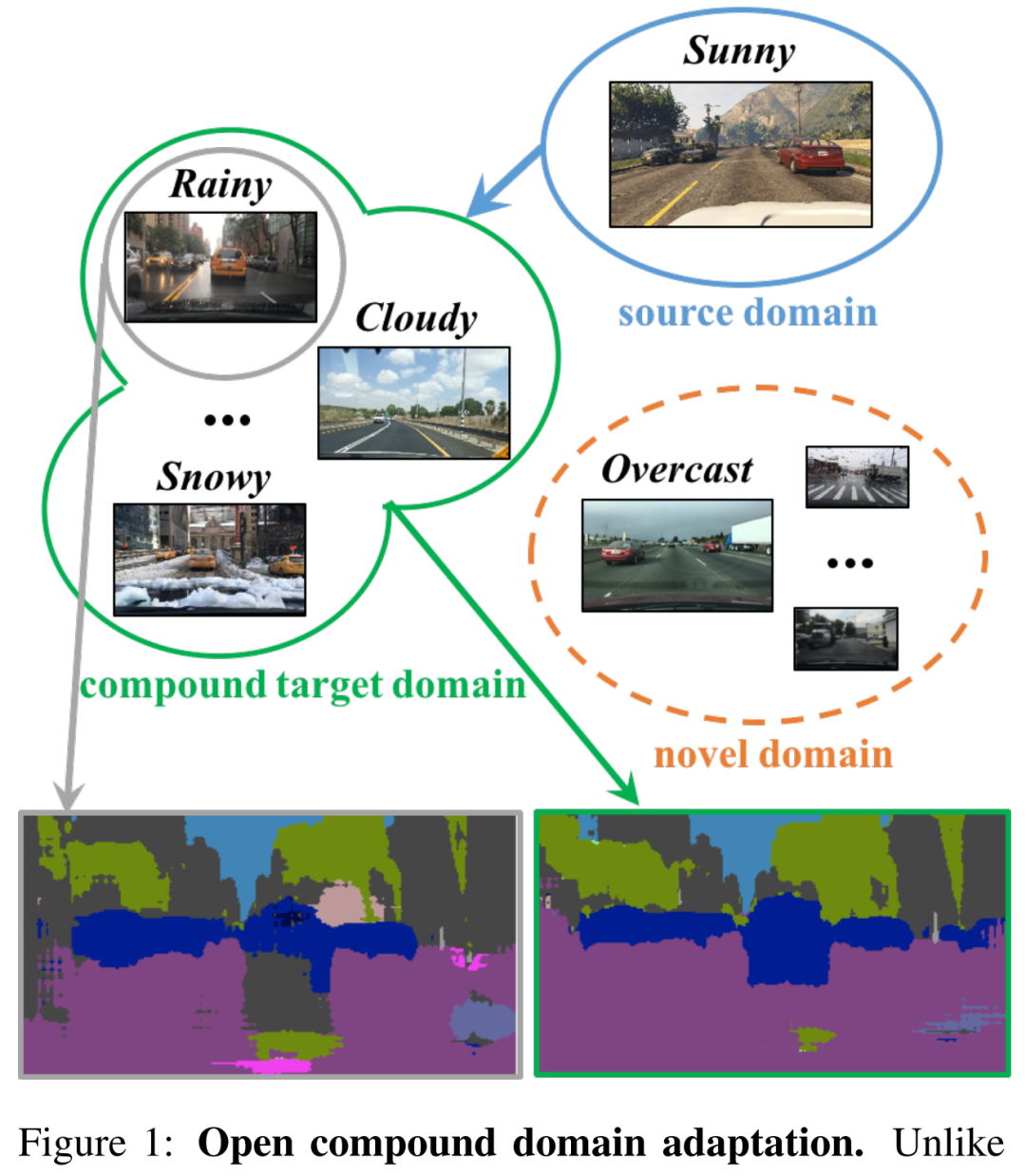
OCDA:Open Compound域自适应
Open Compound Domain Adaptation
主页:https://liuziwei7.github.io/projects/CompoundDomain.html
数据集:https://drive.google.com/drive/folders/1_uNTF8RdvhS_sqVTnYx17hEOQpefmE2r?usp=sharing
论文:https://arxiv.org/abs/1909.03403
代码:https://github.com/zhmiao/OpenCompoundDomainAdaptation-OCDA
实验证明了OCDA在数字分类,人脸表情识别,语义分割和强化学习方面的有效性,性能优于PyCDA、MTDA和IBN-Net等网络,数据集和代码刚刚开源!已收录于CVPR 2020 Oral。作者团队:港中文(林达华组)&谷歌等
TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style
论文:http://openaccess.thecvf.com/content_CVPR_2020/papers/Patel_TailorNet_Predicting_Clothing_in_3D_as_a_Function_of_Human_CVPR_2020_paper.pdf
代码:https://github.com/chaitanya100100/TailorNet
数据集:https://github.com/zycliao/TailorNet_dataset
KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations
论文:https://arxiv.org/abs/2002.12687
数据集:https://github.com/qq456cvb/KeypointNet
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
论文:https://arxiv.org/abs/2003.13845
数据集:https://github.com/lattas/AvatarMe
Learning to Autofocus
论文:https://arxiv.org/abs/2004.12260
数据集:暂无
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
论文:https://arxiv.org/abs/2003.13989
代码:https://github.com/zhuhao-nju/facescape
Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data
论文下载链接:https://arxiv.org/abs/2004.01166
代码:https://github.com/Healthcare-Robotics/bodies-at-rest
数据集:https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KOA4ML
A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
主页:https://anyirao.com/projects/SceneSeg.html
论文下载链接:https://arxiv.org/abs/2004.02678
代码:https://github.com/AnyiRao/SceneSeg
Deep Homography Estimation for Dynamic Scenes
论文:https://arxiv.org/abs/2004.02132
数据集:https://github.com/lcmhoang/hmg-dynamics
Assessing Image Quality Issues for Real-World Problems
主页:https://vizwiz.org/tasks-and-datasets/image-quality-issues/
论文:https://arxiv.org/abs/2003.12511
PANDA: A Gigapixel-level Human-centric Video Dataset
论文:https://arxiv.org/abs/2003.04852
数据集:http://www.panda-dataset.com/
IntrA: 3D Intracranial Aneurysm Dataset for Deep Learning
论文:https://arxiv.org/abs/2003.02920
数据集:https://github.com/intra3d2019/IntrA
Cross-View Tracking for Multi-Human 3D Pose Estimation at over 100 FPS
论文:https://arxiv.org/abs/2003.03972
数据集:暂无
下载
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020所有论文和300+篇代码开源的论文项目,开源地址如下:
https://github.com/amusi/CVPR2020-Code
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请点击在看支持




