一个RGB-T工作的小小感悟与总结

极市导读
作者从研究背景、原理出发详细介绍了他们中稿IROS-2021的工作:为 RGB-T 语义分割任务提出了一个两阶段的特征增强注意网络—FEANet。在实验方面,FEANet在客观指标和主观视觉比较方面优于其他最先进的 (SOTA) RGB-T方法。>>加入极市CV技术交流群,走在计算机视觉的最前沿
首先,非常激动的和大家说一个本应该三个多月前就激动的一个消息,就是我们的FEANet的工作在IROS-2021上被接收了,当然这绝对离不开老师和师兄,所以在开头先感激一下老师和师兄。也应各位很想知道我干了啥的同学的需求,如果有机会的话,可以引用一下这篇文章。

原文链接:https://arxiv.org/abs/2110.08988
第一部分
我们第一部分直观的通过2个问题快速介绍一下我们的研究背景,先让大家了解一下这篇文章的工作做了些什么。
1、RGB-T是干什么的?
答:在纹理相似、背景暗光,复杂的场景下,RGB图像往往并不能为模型训练提供更多更具有区分度的信息,因此常常会导致预测结果不准确,或者没有办法识别出物体。近年来随着热成像相机的普及,我们发现热红外信息对于照明条件差产生的识别模糊非常有效,例如在城市街景的语义分割任务中就取到了很好的效果,(RGB-T城市街景数据集链接:https://www.mi.t.u-tokyo.ac.jp/static/projects/mil_multispectral/)。因此,可以将热像仪生成的热红外图像作为重要的信息补充。

2、FEANet是干什么的?
答:我们为 RGB-T 语义分割任务提出了一个两阶段的特征增强注意网络 (FEANet)。具体来说,就是我们引入了一个特征增强注意力模块(FEAM)从通道和空间的两个方向去提高模型的信息挖掘能力和增强模型的多级特征的提取和整合能力。
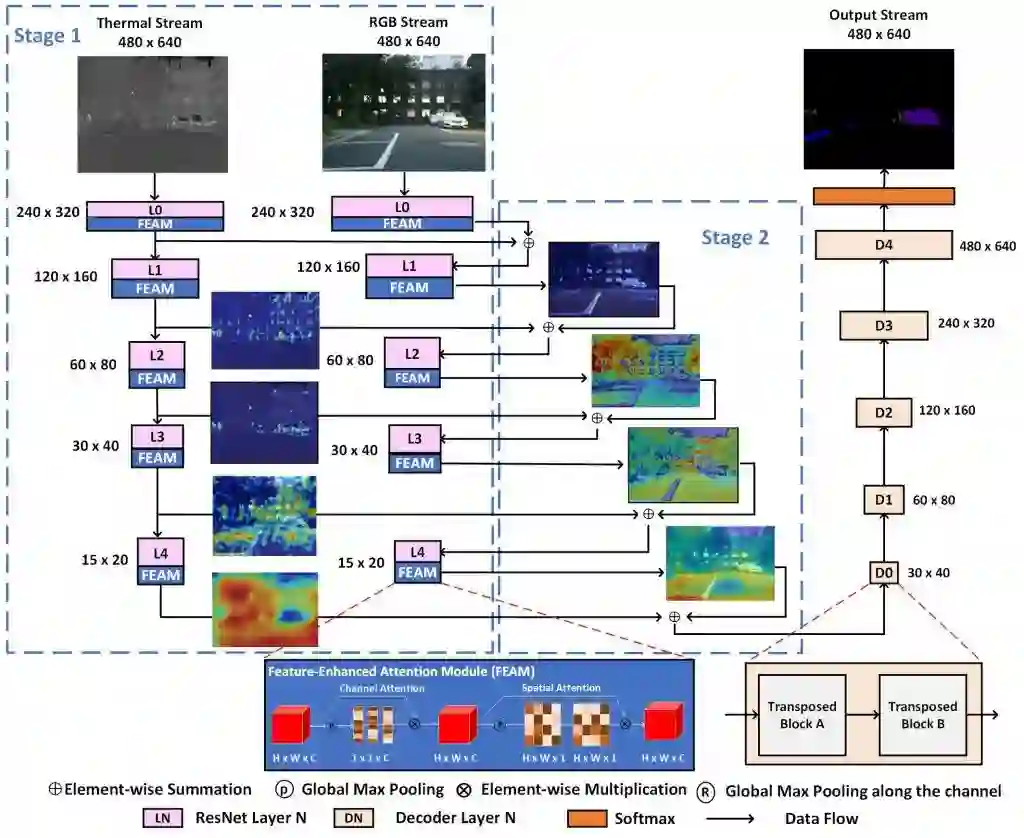
第二部分
FEANet为什么可以?在这一部分我打算把文章网络结构中的几个idea由来的始末给大家介绍一下。
Idea1:双encode,skip-connect结构
我们的FEANet的工作起初是基于RTFNet上进行改进的,在RTFNet的文中的消融实验结构充分表明了双encoder,skip-connect结构的强大之外,RTFNet其实是具有很强的可加工性的。没错其实主要的原因就是它encoder部分太像Unet了,就让人忍不住想魔改它,就这样RTFNet就成为了我们这次的baseline。然后,我们基于RTFNet在数据集上的不足点进行改进,同时,也与最新的(RTFNet的同一作者)的另一篇的FuseSeg进行一个指标上的竞技。通过与RTFNet的结果进行研究,我们很快就发现了问题。

RTFNet在物体的细节上的分割非常的粗糙以及没有办法识别出小物体(比如:色锥),结合当时注意力机制模块对与细小目标上的良好表现来看,是否可以通过引入注意力机制模块来改善上述的不足之处呢?
Idea2:FEAM结构(注意力机制模块)
其实FEAM是受到另一篇文章BBSNet(基于RGB-D数据所开发的网络)的启发构建的,BBSNet是一篇成功将当时非常红的CBAM模块(图中的DEM结构)植入了网络的encode部分并取得SOTA效果的网络,那么本着RGB-D和RGB-T都是多光谱的图像会不会可以相互借鉴的好奇心态,我们设计了一个FEAM模块,使用注意力机制从融合数据中学习特征,然后改进网络的预测结果。
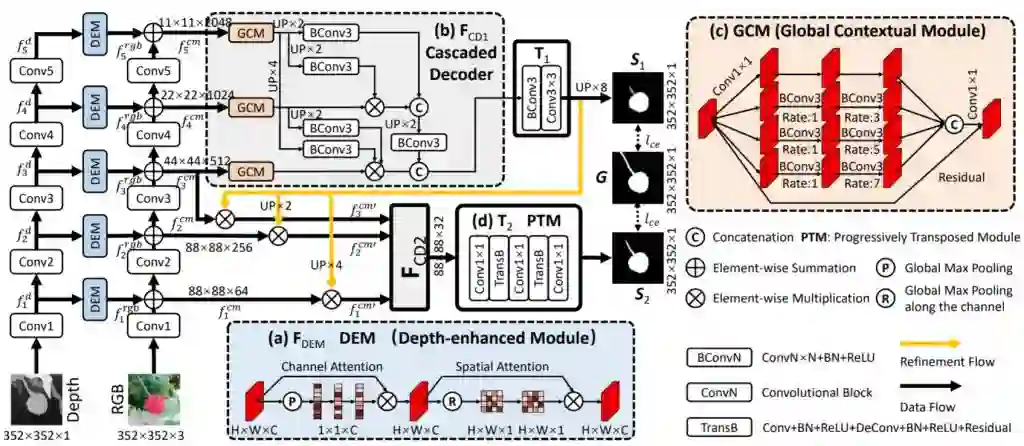
Idea3:为什么每层都添加
继续本着RGB-D和RGB-T都是多光谱的图像会不会可以相互借鉴的好奇心态,我们是否可以按照,RGB-FEAM-Thermal的结构模式去改造RTFNet呢?然后就有了我们第一版实验的。实验结果当时记得是:mAcc是69.1,mIou是54.1。其实从实验结果上看,我们已经高出了RTFNet一大截有多了,当时我都兴奋的蹦起来了,但是后面师兄看到结果后只是默默的给我发来FuseSeg这篇文章,我当时第一时间看了网络结构,哦原来是用FuseNet161换了ResNet152而已,但是当后面翻到结果一看,上面两个指标都高于目前我们设计的FEANet的的时候,人都傻了。
还记得那天晚上组会的时候老师和我们说,现在指标都高于RTFNet就先和RTFNet做比较,就用田忌赛马的策略,如果故事讲得好说不定还有中的机会。我也在那时候真正的明白到了指标竞争的残酷之处。如果故事到这里的话也许就看不见现在的每层都加的FEANet了。
记得当时还希望说能不能通过调参数的方法打倒这两个指标,在调了两天参数后的一个晚上,我看到了之前自己做的CAM可视化的一个代码,然后就试着可视化了当时的添加FEAM后每一层网络。可视化的过程我突然想到,其实Thermal本质上不是想利用热力信息对RGB中明显可以看出的物体进行补充,而是给RGB看不见的信息进行一个补充,所以两张图关注到的对象不一样。可视化后在Thermal上添加了FEAM结构后,更加坚定了每层都加的想法,所以抱着试一试的心态进行了,每层都加的实验,最后实验出来了,mAcc:71.2,mIou:54.3,然后就有你们现在看到的FEANet网络结构了。
Idea4:loss函数不是传统的交叉熵
这个损失函数组合是通过一次天池上的语义分割比赛上看到并记下来的,DiceLoss 和 SoftCrossEntropy组合。本质上就是针对样本不平衡进行进行优化的,还记得当时师兄进行实验的时候,有一个有经验的博士说过可以通过改变损失函数对于样本不平衡的现象进行优化,只是当时实验出来的结果就有种拆东墙补西墙的感觉,但是没有想到组合后的损失函数也能够顺利下降并且对各个指标有有了提升,最后就有了我们的结果:
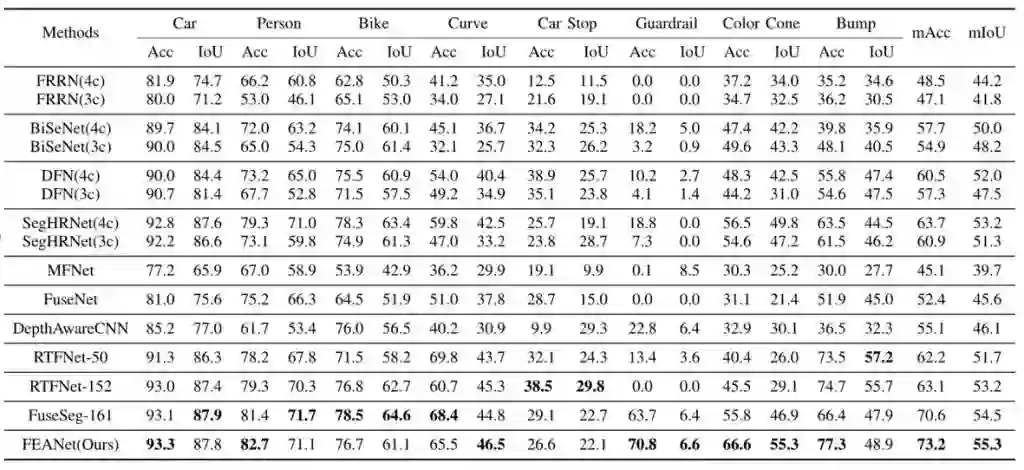
添加了FEAM结构后并没有引入了很大的参数量,也没有造成推理速度的下滑,所以
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
由此诞生
第三部分
论文成功接受后的复盘,通过下面五个问题进行一个总结复盘
1、FEAM结构会不会过时了?
答:会,当时论文发的时候TransFormer已经把CNN按在地上了,整个朋友圈CV清一色的TransFormer,但是我们在设计的时候由于TransFormer还没有蔓延到下游任务中,都是在围绕着ViT图像分类中进行的,ICCV2021的best paper SWIN-TransFormer在各类比赛中作为backbone碾压各种CNN结构的网络,也许是时候了。看着指标做来做去都是60~70,50~55,当时就连评审都说只是高了0.8%而已,所以可能只是可能啊,更好的预训练模型会不会带来更好的结果呢?
2、BBSNet后续的cascade结构为啥没有延用呢?
答:实验证明,FEANet可能真的不适合这种结构,从因为与Deep图像补充RGB同一物体信息不同,Thermal图像是补充与RGB不同物体信息的,也许过分的级联会导致特征与特征间的语义对冲,从而会导致反作用,从结果上看也确实是的,并不适合。但是会不会有更适合的结构呢?别急,下篇工作告诉你。
3、实时性只在RTX 2080TI上反映靠谱吗?
答:见人见智的问题,以前他们都是在RTX 2080TI上进行对比实验的所以我们这么对比也是为了更加直观的反映我们比他们好,所以最开始在RTX 2080TI提实时性的这个文章可能责任全在它身上了,但是我相信很快部署在例如Jetson的轻量化RGB-T很快就会到来了,别细问,问就是下一篇文章的内容。
4、skip-connect真的可靠吗?
实验表明是可靠的,但是换个角度看现在也许是可靠了,但是如果这个是RGB-T-D这种多多模态的任务呢?如果是RGB-1-2-3-4-5-6呢?还这样连吗?skip-connect我感觉还是过于粗暴了,其实可以从可视化后的两个结构融合的图像上,确实出现了对于同一物体的不同识别结果的语义对冲,那有没有更好的方式组合,能够更加降低两种特征融合发生丢失,或者冲突的问题呢?会有的,也许就是下一篇文章。
第四部分
感谢
我还记得这篇文章是寒假一个月时间赶出来的,为了投当时的3月的IROS,其实回想当时,过年的时候我们都还在拼命的研究和工作,老师和师兄都付出了非常多的心力,论文改又改,我的结构图也是画了又画,都忘记是第40几版了,非常庆幸的是我们的辛苦工作最终得到了认可,文章被接受了,但是更值得庆幸的是,我能够认识老师和师兄。最后再次的感谢各位帮助过我的师兄,还有同伴们,我们下一次顶会见。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



