ICLR 2020 Spotlight!从梯度信噪比来理解深度学习泛化性能 | AI TIME PhD
深度学习在诸多应用领域取得了巨大的成功,但是其背后的基础理论确相对有些滞后。与传统浅层学习模型不同,深度学习所得到的深度神经网络(DNNs)层次更为复杂,然而泛化性能却很好!在第二期 AI Time PhD ICLR 专题分享直播间,毕业于北京大学的刘锦龙博士,从全新的角度和大家探讨了这个问题!一起来看看这篇 ICLR 顶会焦点论文,是如何从梯度信噪比来理解深度学习的泛化性能为什么这么好吧!
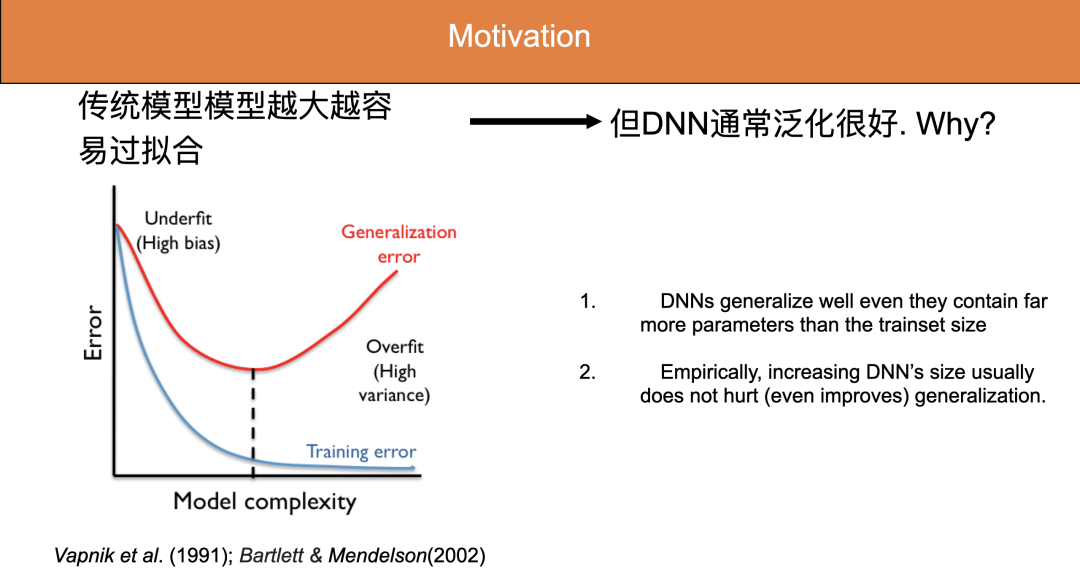
对传统的机器学习浅层模型(比如线性回归、SVM)而言,参数量越大,越容易过拟合,泛化性能也就越差。
相比之下,深度神经网络模型包含巨大的参数量, 通常比训练样本数目多得多,按照经典泛化理论,应该会出现严重的过拟合问题。
然而在实践中,在真实数据上训练的深度学习模型通常具有很好泛化性能。很多时候 DNN 模型越大,泛化效果可能会越好。传统的泛化理论无法解释其中机理!
一步泛化比例 (OSGR):在梯度下降过程的每一步迭代中,测试集的 loss 下降和训练集的 loss 下降的期望值的比值。该指标用于刻画梯度下降法训练过程中的泛化性能。
一般测试集的 loss 下降比训练集的 loss 下降更慢,意味着每一步迭代中,这个比值应该小于1。OSGR 越接近 1,泛化性能越好,反之则越差。
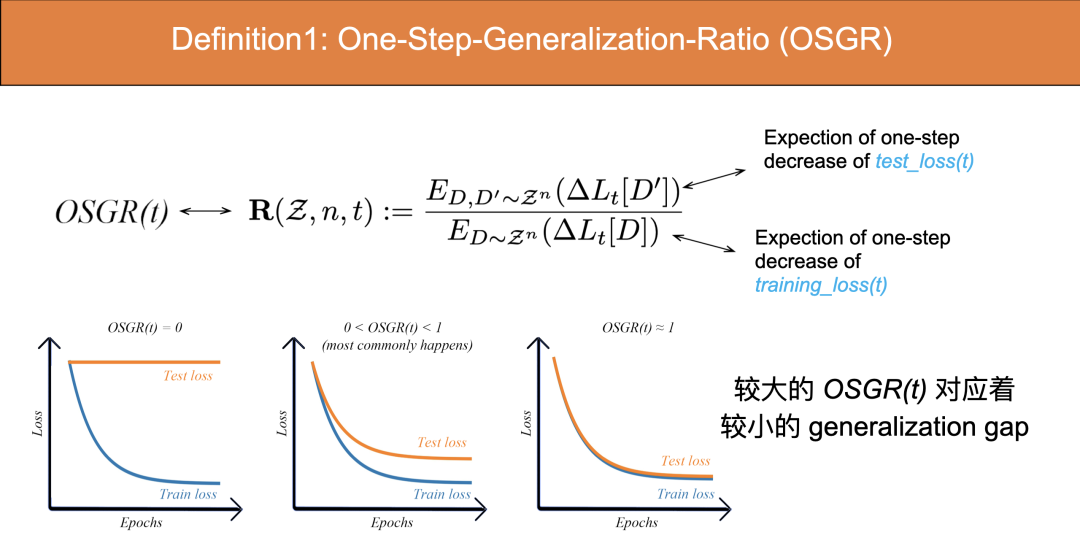
上图分别为OSGR值为0、0~1以及1的情况。
OSGR=0时,training loss在下降,但test loss无变化;OSGR=1时,test loss和training loss的下降速度一致,说明没有generation gap,泛化性能为最为理想;然而OSGR大部分处于0~1之间,中间这种曲线在训练中最为常见。
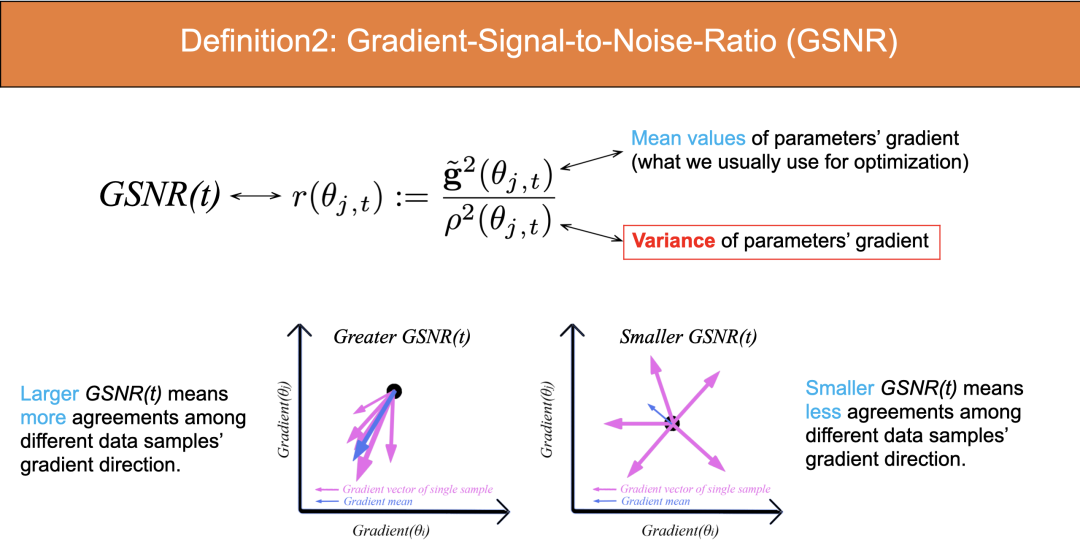
b)Gradient Signal to Noise Ratio
参数的梯度信噪比 (GSNR):在所有样本逐个分别计算每个参数的梯度,对每个参数分别计算 sample-wize 的梯度均值和方差,得到梯度的均值的平方与梯度的方差之间的比值。该指标刻画了在梯度下降过程中不同 sample 的梯度的一致性。
如果所有 sample 梯度一样,则方差为 0,梯度信噪比为无穷大。因此 GSNR 值越大,各个 sample的梯度方向的一致性越高。
刘博士提出:梯度信噪比越大,一步泛化比例越接近于 1,即 Larger GSNR leads to better generalization。
该结论基于两个假设:
(1)Learning rate 足够小(接近于零)。
(2)训练集的平均梯度和测试集的平均梯度服从同一分布。(训练后期此条假设不成立,因为模型参数在训练后期会很好地拟合训练集,使得训练集的梯度和测试集的梯度不再服从同一分布。)

上式中,左边代表OSGR,与右边的GSNR有关。
也就是说,如果训练过程中各个 sample 之间梯度方向趋于一致,则 test loss 和 training loss 的 gap 比较小,泛化性能比较好,测试集和训练集的下降速度就比较接近;如果不同 sample 的梯度方向相差很大,分布不一致,那么训练过程中 training loss 和 test loss 下降速度的比值会很小(接近与 0),泛化性能也就很差。具体的结论推导过程可以参考文章。
由于等式左边可以通过定义计算,右边也可以统计均值、方差从而计算出来。因此我们可以通过实验验证该等式是否成立!
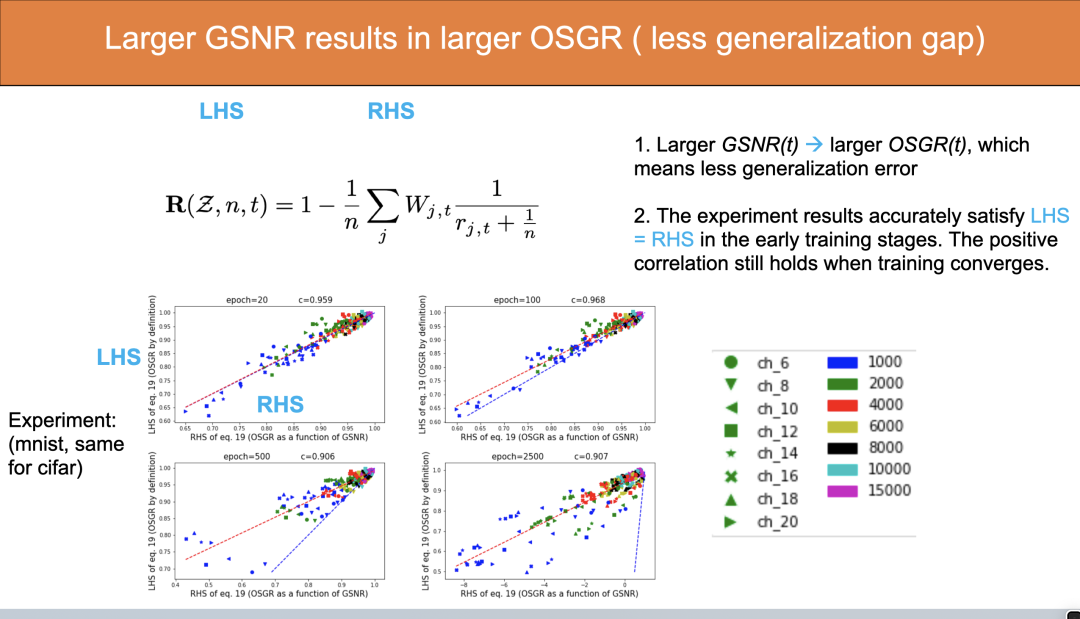
上图是在 MNIST 上的试验。训练初期,比如 epoch=20 的时候,蓝线和红线重合,表示等式左边等于右边,但是训练后期会有很大偏差。虽然后期左边不等于右边,但是左、右依然有很强的正相关性,相关系数在 0.9 以上,因此 Larger GSNR leads to better generalization 这个结论依然成立。
解释 DNN 的泛化性能
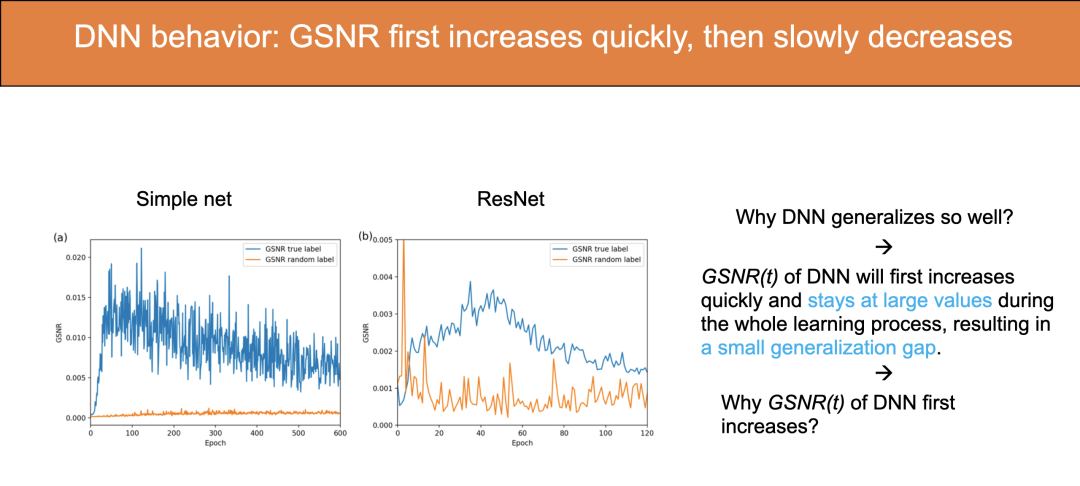
如果我们将样本标签设置成随机(randomized),仍然可以在训练集上把 loss 下降到零,但由于这样的训练集已经不包含任何知识(标签全是错的),无法学到什么,所以没有任何泛化性能。实验结果中,黄线(random label)的 GSNR 始终很低。这符合我们的结论:GSNR 可以揭示模型的泛化能力。
图中蓝线显示,深度学习 GSNR 在训练初期会有明显上升过程。按理说,随着训练进行,梯度均值会越来越小,在收敛时接近于零,同时方差会越来越大,因此梯度信噪比 GSNR 应该不断下降才对。对于浅层的模型,确实如此。
但 DNN 为什么有上升过程?
答案:正是这个 GSNR 初期上升的过程使得 GSNR 在 DNN 的训练中始终保持在一个比较高的值,这就是深度学习泛化能力较好的原因!
刘博士展示了一个简单的对比实验,用一个两层 MLP 模型,分别冻结和打开它的第一层参数,训练这个模型。显然,在冻结第一层参数的情况下,模型等价于线性回归。在这两种情况下,分别统计模型第二层的平均 GSNR,发现在冻结的情况下,GSNR 始终在下降,而在打开的情况下,GSNR 会有一个明显的上升过程。这就清楚地表明了深度学习和浅层(linear regression)模型 GSNR 不同的表现。
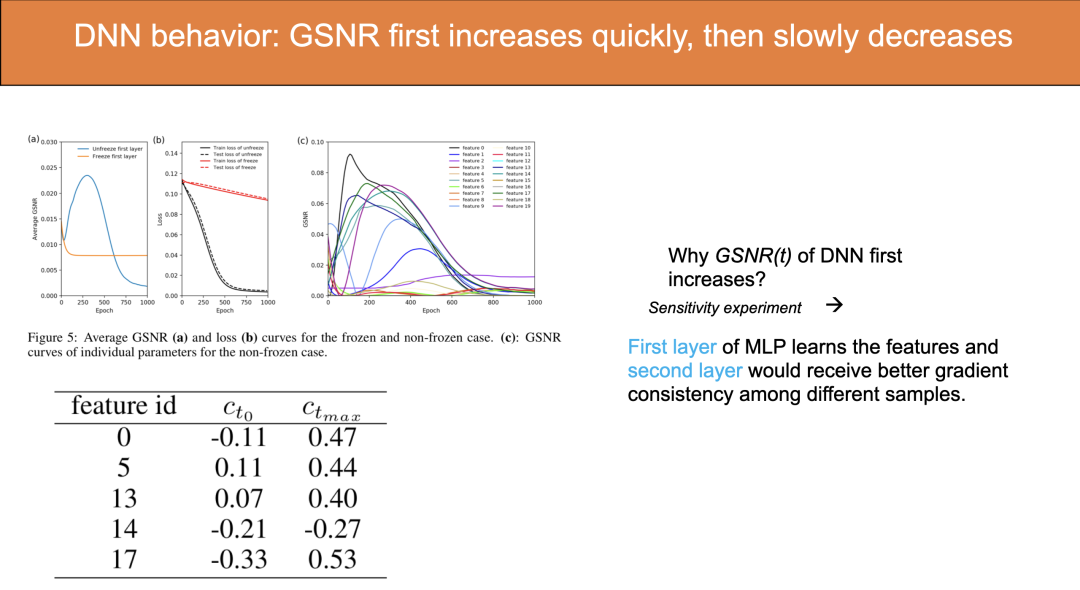
分析认为,在打开的情况下,模型第一层的参数能够学习到较好的特征,而模型第二层的和这些特征相乘的权重的梯度在不同的 sample 上会具有更好的一致性。即大部分 sample 都同时倾向于使这个权重增大或者减小,对应的此权重的 GSNR 也会较大。
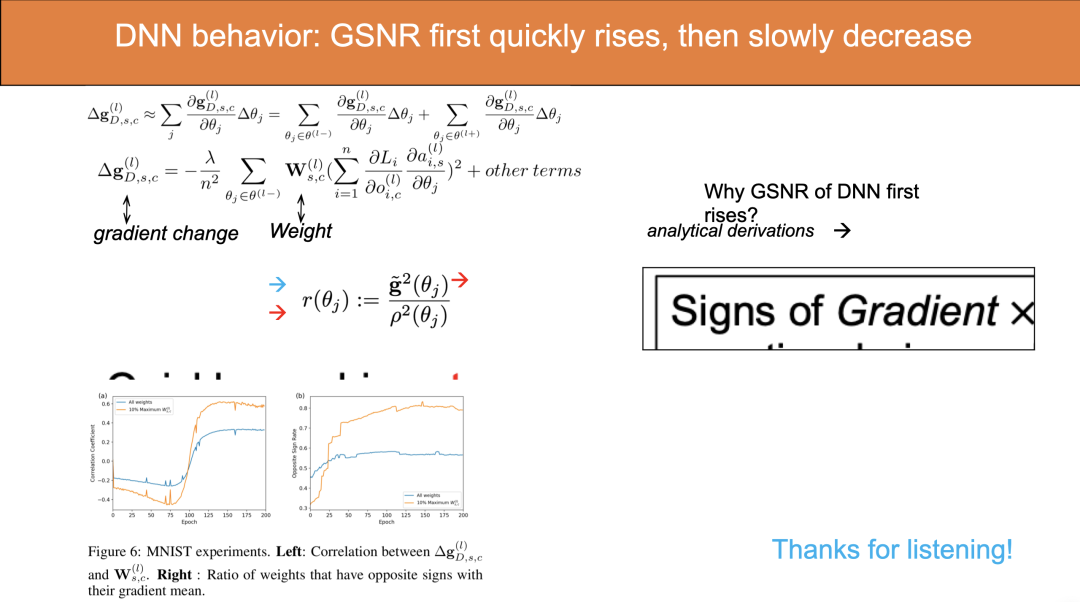
解析的分析上,刘博士在全连接网络的情况下,通过推导阐述了一个有趣的机制,这个机制使得在模型训练的初期,模型大部分参数的平均梯度(GSNR 的分子)会倾向于增大。具体大家可以参见文章。
总结
1.刘博士的团队在若干假设下证明了,对于梯度下降法,训练过程中 GSNR 越大,最终模型的泛化性能越好。
2.对于深度学习模型,训练初期会存在一个 GSNR 快速上升的现象,这个现象使得深度学习具有很好的泛化性能。它和深度学习模型的特征学习能力密切相关,可通过实验和解析分析论证这一点。
最后分享直播结束后,微信群里大家与嘉宾的部分互动。

Random label如何实现?怎么去做loss呢?例如在cifar10上如何做random label?

每个样本随机分配一个标签,这样以后数据中就不包含知识。具体可以去看2017年ICLR best paper: Rethinking Generalization.

是否考虑过不同深度学习模型,比如LSTM或CNN等?原文用的数据集都是图像分类吗?
我们实验用的就是CNN,我们的理论推导其实是一般性的推导,不依赖于模型结构。LSTM的实验确实没做。原文用的数据集都是图像分类,详情参见文章。
文章结论会受任务类型影响吗?
不会,我们也用toy回归模型验证了。因为是先理论推导,再实验验证,二者在初期能完美符合,所以我们有很强的信心不会因为任务的改变而改变。
整理:鸽鸽
审稿:刘锦龙
参考文章:
https://zhuanlan.zhihu.com/p/99516219
https://openreview.net/forum?id=HyevIJStwH









