深度学习超参数简单理解
首先谢谢读者的指正,现在已经把所有遮挡的都处理完毕,谢谢您们的指正,谢谢!
正文:
说到这些参数就会想到Stochastic Gradient Descent (SGD)!其实这些参数在caffe.proto中 对caffe网络中出现的各项参数做了详细的解释。
Learning Rate
学习率决定了权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。仅靠人为干预调整参数需要不断修改学习率,因此后面3种参数都是基于自适应的思路提出的解决方案。后面3中参数分别为:Weight Decay 权值衰减,Momentum 动量和Learning Rate Decay 学习率衰减。
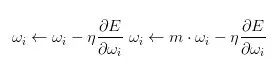
Weight decay
在实际应用中,为了避免网络的过拟合,必须对价值函数(Cost function)加入一些正则项,在SGD中加入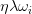
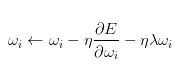
上面这个公式基本思想就是减小不重要的参数对最后结果的影响,网络中有用的权重则不会收到Weight decay影响。
在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。
Momentum
动量来源于牛顿定律,基本思想是为了找到最优加入“惯性”的影响,当误差曲面中存在平坦区域,SGD就可以更快的学习。
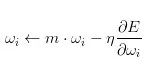
Learning Rate Decay
该方法是为了提高SGD寻优能力,具体就是每次迭代的时候减少学习率的大小。
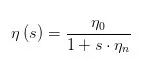
点击这里:Difference between neural net weight decay and learning rate
接下来是我在知乎查询到的一点资料(整理了供大家参考学习):
weight decay(权值衰减)的使用既不是为了提高收敛精确度也不是为了提高收敛速度,其最终目的是防止过拟合。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
momentum是梯度下降法中一种常用的加速技术。对于一般的SGD,其表达式为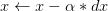
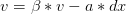

其中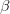

normalization(batch normalization)。batch normalization的是指在神经网络中激活函数的前面,将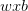
提高梯度在网络中的流动。Normalization能够使特征全部缩放到[0,1],这样在反向传播时候的梯度都是在1左右,避免了梯度消失现象。
提升学习速率。归一化后的数据能够快速的达到收敛。
减少模型训练对初始化的依赖。
关于网络调参,那就是经验。提供的资料:链接:http://pan.baidu.com/s/1pLtqfhT 密码:tkgp
如有错误请指正,谢谢!

