【平行讲坛】平行图像:图像生成的一个新型理论框架
来源:德先生
平行图像:图像生成的一个新型理论框架
王坤峰1,2 鲁越1,3 王雨桐1,3
熊子威3 王飞跃1,4
1(中国科学院自动化研究所 复杂系统管理与控制国家重点实验室北京100190)
2(青岛智能产业技术研究院 平行视觉创新技术中心 青岛266000)
3(中国科学院大学 计算机与控制学院 北京100049)
4(国防科学技术大学 军事计算实验与平行系统技术研究中心 长沙410073)
摘要:为了提高计算机视觉系统的泛化能力,要求利用大规模、多样化、带标注的图像数据集,对视觉模型进行充分的学习与评估。由于从实际场景中获取图像具有局限性,文中提出一种新的图像生成理论框架,称为平行图像。平行图像的核心单元是软件定义的人工图像系统。从实际场景中获取特定的图像“小数据”,输入人工图像系统,生成大量新的人工图像数据。文中总结平行图像的实现方法,包括图形渲染、图像风格迁移、生成式模型等。并且对比分析人工图像和实际图像的特点,讨论领域适应策略。
关键词:平行图像,模型学习,图形渲染,图像风格迁移,生成式模型
中图法分类号TP391
Parallel Imaging: A New Theoretical Framework for Image Generation
WANG Kunfeng 1,2, LU Yue1,3, WANG Yutong1,3,
XIONG Ziwei3, WANG Fei-Yue1,4
1 (The State Key Laboratory of Management and Control for Complex Systems, Institute of Automation, Chinese Academy of Sciences, Beijing 100190)
2 (Parallel Vision Innovation Technology Center, Qingdao Academy of Intelligent Industries, Qingdao 266000)
3 (School of Computer and Control Engineering, University of Chinese Academy of Sciences, Beijing 100049)
4 (Research Center of Military Computational Experiments and Parallel Systems, National University of Defense Technology, Changsha 410073)
Abstract
To build computer vision systems with good generalization ability, large-scale, diversified, and annotated image data are required for learning and evaluating the in-hand computer vision models. Since it is difficult to obtain satisfying image data from real scenes, a new theoretical framework for image generation is proposed, which is called parallel imaging. The core component of parallel imaging is various software-defined artificial imaging systems. Artificial imaging systems receive small-scale image data collected from real scenes, and then generate large amounts of artificial image data. In this paper, the realization methods of parallel imaging are summarized, including graphics rendering, image style transfer, generative models, etc. Furthermore, the characteristics of artificial images and actual images are analyzed and the domain adaptation strategies are discussed.
Key Words:Parallel Imaging, Model Learning, GraphicsRendering, Image Style Transfer, Generative Models
Citation:WANG K F, LU Y, WANG Y T, XIONG Z W, WANG F Y. Parallel Imaging: A New Theoretical Framework for Image Generation. Pattern Recognition and Artificial Intelligence, 2017, 30(7): 577-587.

平行图像:图像生成的一个新型理论框架
王坤峰 鲁越 王雨桐
熊子威 王飞跃
近年来,计算机视觉技术取得快速发展,应用于智能交通、安防监控、生物特征识别、工业测量、人机交互等领域[1–4]。计算机视觉技术的核心是视觉计算模型(简称为视觉模型)。为了提高计算机视觉系统在实际应用中的性能,要求利用大规模、多样化、带标注的图像数据集,对视觉模型进行学习与评估。但是,从实际场景中采集和标注大规模图像数据非常费时费力,通常只能获得小规模且多样性受限的图像数据集 ( 例如ImageNet, PASCAL VOC, MSCOCO), 无法覆盖复杂动态的开放环境。 例如,KITTI-Detection数据集
(http://www.cvlibs.net/datasets/kitti) 广泛应用于评价智能车辆的目标检测算法,但是KITTI-Detection是在非常有限的时空环境下拍摄,只有7481幅训练图像和7518幅测试图像,标注80256个目标(Car, Pedestrian, Cyclist)。单纯依靠KITTI-Detection数据集,无法对目标检测模型进行充分的学习与评估,因此影响智能车辆视觉系统的性能。
2016年,王坤峰等[5]将复杂系统建模与调控的ACP(人工社会(Artificial Societies)、计算实验(Computational Experiments )、平行执行( Parallel Execution))方法[6–12]推广到视觉计算领域,提出平行视觉的概念、框架和关键技术。 平行视觉致力于建立复杂环境下视觉感知与理解的理论和方法体系:利用人工场景模拟和表示复杂挑战的实际场景,使采集和标注大规模多样性数据集成为可能,通过计算实验进行各种视觉模型的学习与评估,最后借助虚实互动的平行执行在线优化视觉系统。在平行视觉中,人工的虚拟空间是解决复杂视觉问题的新的另一半空间,同实际的物理空间一起构成求解复杂视觉问题的完整的“复杂空间”。 从人工虚拟空间中获取满足具体应用要求的图像,是平行视觉研究的基础。
本文提出一种新的图像生成理论框架,称为平行图像(Parallel Imaging)。平行图像是平行视觉的一个分支,提供平行视觉需要的图像数据。平行图像的核心单元是软件定义的人工图像系统。从实际场景中获取特定的图像“小数据”,输入人工图像系统,生成大量的人工图像数据。这些人工图像数据和特定的实际图像数据一起构成解决复杂视觉问题所需要的平行图像“大数据”集合,用于视觉模型的学习与评估研究。
传统的图像生成方法主要利用摄像机在实际场景中拍摄图像,然后直接利用此图像或者在图像上加入随机噪声,作为视觉模型学习的输入。但是从实际场景中采集和标注大规模图像数据不仅费时费力,并且难以保证图像数据的多样性[13–14]。针对传统图像生成方法存在的局限,本文提出平行图像理论框架。
平行图像是平行视觉[5]的一个分支,可以为平行视觉研究提供大规模多样性的图像数据(包括实际和人工)。图1显示以平行图像为观察角度的平行视觉框架结构。首先利用人工图像来扩展和补充实际图像,获得虚实结合的平行图像“大数据”。然后通过计算实验进行各种视觉模型的学习与评估,最后借助平行执行来在线优化视觉模型,实现对复杂环境的智能感知与理解。
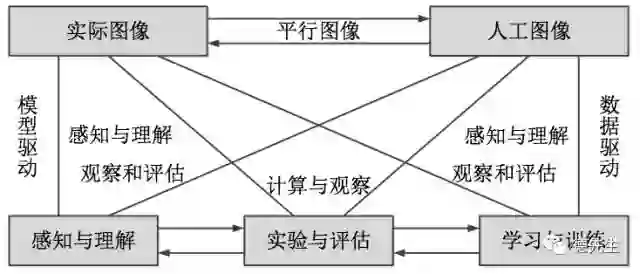
图1 平行视觉的基本框架
Fig. 1 Basic framework of parallel vision
图2显示了平行图像的技术流程。从实际场景中采集得到实际图像“小数据”,输入软件定义的人工图像系统,通过解析和吸纳实际图像的特点,自动生成大量新的人工图像数据。这些人工图像数据和实际图像“小数据”一起构成虚实结合的平行图像“大数据”,在此基础上进行平行视觉的计算实验和平行执行,通过学习提取得到应用于某些具体场景或任务的“小知识”。这里的“小”是针对所需解决具体问题的特定智能化的知识,而不是指知识体量上的小。图2虚线方框内显示了平行图像的核心单元,即软件定义的人工图像系统。人工图像系统的实现方法包括图形渲染、图像风格迁移、生成式模型等。
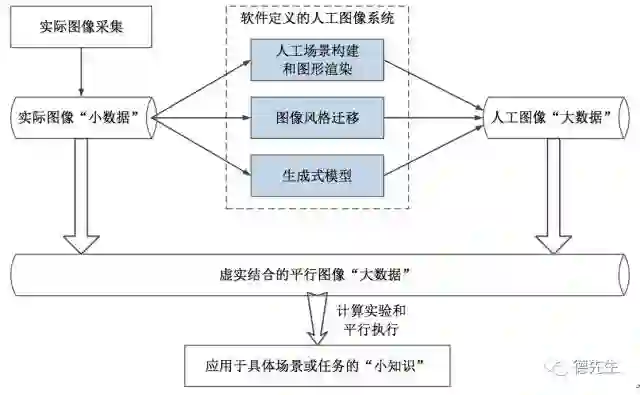
图2 平行图像的技术流程图
Fig. 2 Technological flowchart of parallel imaging
由于学习在计算机视觉中的重要性,平行图像与平行学习[15–16]也密切相关。特别是平行学习中的预测学习和集成学习思想,可以引入到平行图像中,指导人工图像生成的方向。使用预测学习解决如何随时间发展对人工图像进行探索。实际图像中的场景布局、目标属性、光照、天气等因素在动态变化,计算机生成的人工图像也应该模仿这些因素变化,仿真预测可能的未来,并通过观察和学习来理解真实世界如何运行,提前建立适应未来状况的视觉模型。使用集成学习解决如何在空间分布上对人工图像进行探索。可以针对某个视觉模型学习任务,建立多个学习器,每个学习器独立地根据自己获取的图像数据来进行学习。各学习器是时间同步的,但是所获取的图像数据可以是时空局部的。这一思想可以用来探索人工图像的解空间。
平行图像包括实际图像“小数据”和人工图像“大数据”。实际图像由摄像机从实际场景中拍摄得到,人工图像则是由人工图像系统在计算机上生成。人工图像系统的实现方法有多种:可以利用计算机图形学技术来合成,先构建人工场景,然后通过图形渲染得到;可以对已有图像进行风格迁移,改变已有图像的外观风格;还可以建立生成式模型,直接输出符合要求的人工图像。本节对这3种实现方法进行探讨。
借助先进的计算机图形学、虚拟现实、微观仿真等技术,构建逼真的人工场景,模拟和表示复杂挑战的实际场景,通过渲染生成特定风格的人工图像[5]。已经有一些开源或商业游戏引擎和仿真工具,例如OpenStreetMap、CityEngine、Google 3D Warehouse、3ds Max、Unity3D、Blender等,可以用于人工场景构建和图形渲染。
人工场景由许多要素构成,包括静态物体、动态物体、季节、天气、光源等。例如,人工室外场景的构成要素如表1所示。使用Agent表示场景要素,按照物理规律进行多Agent仿真。 使用Agent表示人工场景中的物体对象和环境因,每个Agent拥有自己的属性。将静态Agent添加到人工场景的相应位置,让动态Agent(行人、车辆等)在人工场景中运动起来。动态Agent具有运动行为模型,以实现路径规划、障碍物规避等功能。相关的Agent之间具有通信机制,例如当车辆在道路上行驶时,应自动获取其它Agent的实时信息,从而规划当前的局部路径和行为。可以利用赛博空间(Cyberspace)海量且丰富的静态和动态物体的三维模型。季节和天气直接影响人工场景的渲染效果,要求与物理世界的自然规律一致,例如春季植物开花、冬季地面有雪、晴天投射阴影、雾天物体模糊等。白天光源主要是太阳,夜间光源主要是路灯和车灯。从白天向夜间过渡时,会自动开启路灯和车灯;从夜间向白天过渡时,会自动关闭路灯和车灯。总之,要求人工场景的构成要素尽可能逼真并且多样化。
表1 人工室外场景的构成要素
Table 1 Components for artificial outdoorscenes

在构建人工场景的基础上,进行图形渲染。在人工场景中设置虚拟摄像机,“拍摄”得到色彩逼真、丰富多样的人工图像。图3显示了我们在人工场景中设置不同的天气条件,渲染得到的人工图像。可以看出,经过图形渲染,人工图像的风格非常接近实际图像。另外,实际场景通常不可控、不可重复,并且难以标注。与之相比,人工场景具有可控、可重复、可自动标注的特点,可以完全控制人工场景中的目标外观和运动模式、光照和天气条件、摄像机位置和视角等因素,生成多样化的虚拟图像。利用人工场景还可以进行加速实验。例如,面向目标检测与分割研究,我们可以在时域相邻图像中渲染改变目标的外观颜色,快速获得多样化的人工图像,而这在实际场景中是不可能做到。如图4所示,在每帧图像中,我们渲染改变道路上车辆的颜色,极大提高了图像数据的多样性。

(左上:阴天;右上:晴天;左下:雾天;右下:雨天。)
Fig. 3 Effects of graphicsrendering given different weather conditions
(Left top: cloudy weather; righttop: sunny weather; left bottom: foggy weather; right bottom: raining weather.)

图4 在相邻图像帧中,渲染改变道路上车辆的颜色
Fig. 4 The colors of on-road vehiclesare changed by graphics rendering in consecutive frames
图像风格迁移是指模仿一幅图像(风格图像)的风格并将其迁移到另一幅图像(内容图像)的过程。风格迁移的目标是获得一幅在艺术效果上与风格图像相近,但图像内容与内容图像一致的新图像[17–22]。利用风格迁移技术,我们可以利用已有的实际图像,生成更多不同光照、时段、天气和季节的人工图像。如图5所示,风格图像是一幅夜间的城市图像((a)左图),内容图像是一幅白天的城市图像((b)左图),通过风格迁移就可以获得一幅光照与风格图像一致,但场景布局与内容图像相同的新图像((c)左图)。图5还显示了对道路图像进行光照和天气风格迁移的效果。

图5 图像风格迁移的示例效果[17]
Fig. 5 Example effects of image styletransfer
目前实现图像风格迁移的方法主要有2种:基于块拼接的纹理合成方法和基于卷积神经网络的方法。其他的风格迁移方法还包括Hertzmann等[18]提出的图像类比、Okura等[19]在此基础上提出的色彩和纹理迁移等。
Efros等[20]提出了基于块拼接的纹理合成方法,后续使用纹理合成方法的相关研究也基本沿用论文[20]中的实验步骤。该方法将内容图像分割为一个个具有一定尺寸的斑块,斑块大小由用户输入决定。该尺寸决定了风格迁移的效果,使用大斑块进行拼接时虽然能更好地保持纹理,但是会损失内容图像的结构。小斑块的作用正好相反。对每一个斑块,在风格图像中搜索一个尺寸一致的与之最匹配的斑块,贴在一张空白的图像上,就得到了一幅输出图像。搜索过程中,既需要考虑内容斑块和风格斑块之间图像强度的相似度,又需要考虑已有的相邻斑块间重叠部分的相似度。作者提出使用图像强度作为衡量内容斑块和风格斑块间匹配程度的变量。由于是斑块拼接所得的图像,斑块边界处过渡不自然,还需对每次贴上的新斑块,计算其与已有相邻斑块重叠区域的表面误差,找到该误差表面的最低成本路径并将其作为新边界,以平滑斑块边界。文中还提到,当在用户输入的斑块尺寸下操作不能得到良好效果时,会减小斑块尺寸重新进行纹理迁移直到获得满意的效果。Ashikhmin等[21]提出了加速Efros纹理迁移的方法。
Gatys等[22]提出了基于卷积神经网络(Convolutional Neural Networks, CNN)的风格迁移方法。首先将一幅噪声图像作为输出图像,分别将这幅噪声图像和风格图像、内容图像作为输入,由训练好的CNN得到各自图像的各层特征图。然后,根据定义的输出图像各层特征图与风格图像和内容图像对应层特征图间的损失函数,利用梯度下降法最小化损失函数,得到输出图像的各层特征图。最后,利用反向误差传播得到输出图像,完成风格迁移。作者定义2个损失函数:输出图像O与风格图像S在风格上的误差、输出图像O与内容图像I在内容上的误差.最终的损失函数是两者的加权和:
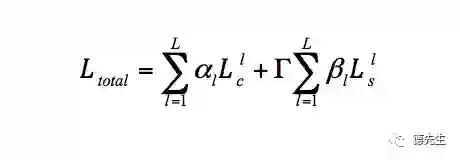
(1)
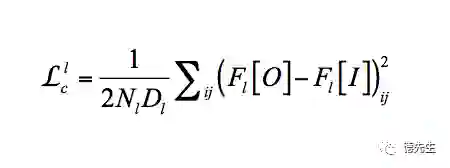
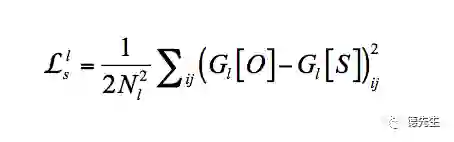
(2)
其中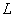
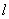




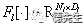
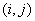
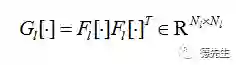
定义为向量化特征图的内积。
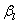
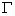
但是,Gatys等的风格迁移方法存在2个缺点:1)尽管输入的内容图像和风格图像都是实际图像,经过此风格迁移得到的输出图像仍然会失真,直边变得弯曲,规则的纹理变得起伏不平;2)没有考虑内容图像和风格图像之间场景语义的对应关系,会生成不符合真实规律的配色。
针对上述两个缺点,Luan等[17]在损失函数(1)基础上,加入了控制逼真程度的正则项,并修改了原风格损失(2)。为了保护内容图像的空间结构,将内容图像到输出图像迁移过程中的形变限制为在RGB颜色空间的局部仿射。基于Matting Laplacian算子,在式(1)中加入图像结构失真的惩罚项:
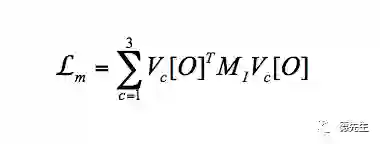
同时,为了确保迁移过程的语义精度,对风格图像和内容图像进行常见标记(天空、建筑、水面等)的语义分割,将分割掩膜作为附加的通道对风格损失进行扩充:
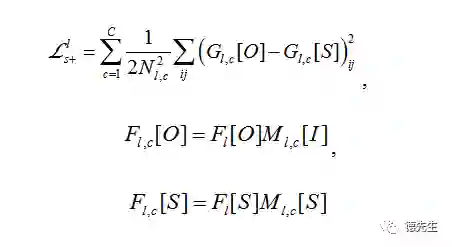


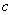
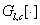
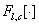
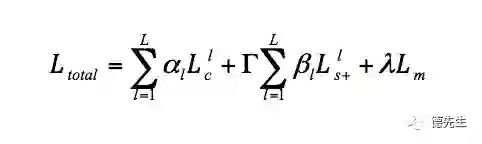
其中
Luan等[22]的能够抑制图像内容的结构扭曲,在许多情况下产生令人满意的、逼真的风格迁移,包括光照、天气、季节等的迁移。
2.3 生成式模型
生成式模型(Generative models)的基本思想是首先建立观测样本的分布的模型,再利用模型进行推理预测。它涉及对数据的分布假设和分布参数估计,并能够根据估计而来的模型采样出新的样本。一类生成式模型首先对数据的显式变量或者隐含变量进行分布假设,然后利用真实数据对分布假设的参数进行拟合或训练,最后利用学习到的分布或模型生成新的样本。这类生成式模型涉及的主要方法有最大似然估计法、近似法、马尔科夫链方法等。另一类生成式模型不直接估计或拟合分布,而是从未明确假设的分布中获取采样的数据,通过这些数据对模型进行修正[23]。生成式对抗网络(Generative AdversarialNetworks, GAN)[23-29]是这类生成式模型的研究前沿,具有强大的图像生成能力。
2014年,Goodfellow等[24]受到博弈论中的二人零和博弈的启发,提出了GAN模型。GAN设定参与游戏双方为一个生成器(Generator)和一个判别器(Discriminator),生成器的目的是尽量学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器。为了取得游戏胜利,这两个游戏参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习优化过程就是寻找二者之间的一个纳什均衡。
GAN的计算流程与结构如图6所示。任意可微分的函数都可以用来表示GAN的生成器和判别器。我们用可微分函数D和G来分别表示判别器和生成器,它们的输入分别为真实数据x和随机变量z。G(z)则为由G生成的尽量服从真实数据分布
pdata的样本。如果判别器的输入来自真实数据,标注为1。如果输入样本为G(z),标注为0。这里D的目标是实现对数据来源的二分类判别:真(来源于真实数据x的分布)或伪(来源于生成器的伪数据G(z)),而G的目标是使自己生成的伪数据G(z)在D上的表现D(G(z))和真实数据x在D上的表现D(x)一致。这两个相互对抗并迭代优化的过程使得D和G的性能不断提升,当最终D的判别能力提升到一定程度,并且无法正确判别数据来源时,可以认为生成器G已经学到了真实数据的分布。
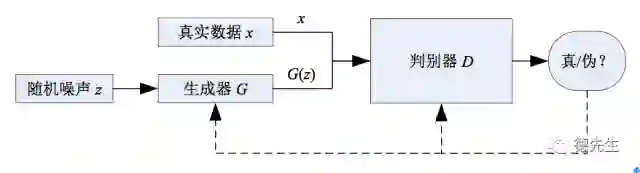
图6 GAN的计算流程与结构
Fig. 6 Computation procedure andstructure of GAN
从平行图像的角度,可以把GAN看作人工图像生成器,通过图像生成或者转换得到人工图像。例如,从随机噪声生成数字、人脸等物体图像,构成各种逼真的室内外场景,从语义图像生成原图像,给黑白图像上色,从物体轮廓恢复物体图像,从低分辨率图像生成高分辨率图像,改变图像的季节、天气和光照风格,将油画转换成照片,从文本生成图像等。这些应用示例主要由GAN的衍生模型[25-29]来实现。本节下面介绍与平行图像密切相关的3种衍生模型。
谷歌公司的Berthelot等[25]提出了BEGAN,即边界均衡GAN。这项工作针对GAN训练难、控制生成样本多样性难、平衡判别器和生成器收敛难等问题,提出了改善方法。它借鉴EBGAN (Energy-Based Generative Adversarial Networks)[26]和WGAN (Wasserstein GAN)[27]各自的优点,使用简单的模型结构,在标准的训练步骤下取得令人满意的效果。传统的GAN试图直接匹配数据分布,而BEGAN致力于匹配自编码器损失的分布。该方法为典型的GAN目标函数增加一个均衡项,平衡判别器和生成器。不仅如此,文献[25]还提出一个可以衡量收敛的超参数,实现了快速稳定的训练和很高的视觉质量。BEGAN 能够生成128×128的高质量人脸图像,包含多样化的姿态、表情、性别、肤色、光照射、胡须等特征,如图7所示。

图7 BEGAN生成的人脸图像[25]
Fig. 7 Face samples generated byBEGAN
利用计算机合成图像来训练视觉模型,能够避免昂贵的图像标注过程。但是,合成图像与真实图像之间存在分布差距,直接利用合成图像来训练模型,难以获得满意的性能。为了缩小合成图像与真实图像之间的分布差距,苹果公司的Shrivastava等[28]提出了SimGAN,提出一种模拟+无监督学习方法,利用未标记真实图像来提高合成图像的逼真性,同时保持合成图像的标注信息(例如眼球的注视方向)。图8显示了SimGAN的结构,合成图像经过Refiner神经网络R处理,得到改进后的图像,判别器D用于区分图像是真实图像还是改进后的图像。Refiner网络R和判别器D交替更新。
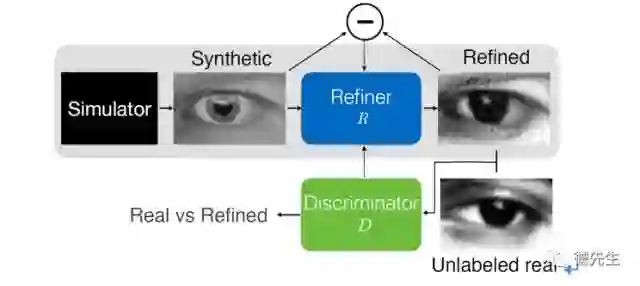
图8 SimGAN的结构[28]
Fig. 8 Structure of SimGAN
Zhu等[29]提出了CycleGAN,在不存在成对训练样本的情况下,学习将源领域图像转换成目标领域图像。GAN通常只有一个生成器和一个判别器,CycleGAN却有两个生成器和两个判别器。一个生成器(用G表示)将X域的图像转换成Y域的图像,另一个生成器(用F表示)将Y域的图像转换成X域的图像。两个判别器DY和DX试图分辨两个域的真伪图像。由于在结构上施加了循环一致性约束,CycleGAN可双向转换不丢失信息,转换后的图像不但真实,而且包含原图像的信息,避免了模式塌陷问题。CycleGAN是一种通用方法,可以应用到许多图像到图像转换任务中,包括风格迁移、目标变形、季节转换、照片增强等。图9显示了CycleGAN的实验效果。

图9 CycleGAN实现的图像到图像转换效果[29]
Fig. 9 Example results of CycleGANfor image-to-image translation
3.1 人工图像和实际图像的对比
首先,在逼真性方面,我们希望人工图像越逼真越好。对于图形渲染来说,逼真性取决于仿真模型的细节程度和渲染引擎的精准程度。为了增加细节程度,在建模时需要遵守物理规则。例如,人工场景的几何结构和物体表面纹理应该与实际场景的一致;当虚拟行人在人工场景中运动时,他们的速度和步态应该与真实行人的相似;当虚拟车辆在虚拟道路上行驶时,应该遵循真实车辆的驾驶行为。然而,所有虚拟模型都是真实模型的简化,需要对细节程度进行适当的折中。如果包含的细节太少,生成图像的逼真性太低;反之,如果包含了太多细节,模型将变得过于复杂而难以处理。另外,为了提高渲染引擎的精准程度,需要采用精确的采样和渲染过程。这在技术上不可行,计算上也不可处理。因此,经过图形渲染生成的人工图像在逼真性上存在限制,单幅人工图像的利用价值通常低于单幅实际图像的价值。幸运的是,GAN(例如CycleGAN)可以将源领域图像转换为目标领域图像,理论上能够使人工图像的逼真性无限接近实际图像的逼真性,判别器已经无法分辨。
其次,在多样性方面,人工图像具有一定优势。真实世界是多样的,在实际场景中,有各种颜色和运动模式的各种目标。但是,由于数据采集和标注的困难,实际场景数据集通常不够多样,尤其缺少不良光照和天气条件下的数据。相比之下,计算机构建的人工场景不仅多样,并且能够自动完成数据采集和标注。根据真实世界的物理规则,人工场景可以模拟各种场景布局、目标对象、光照和天气条件。我们甚至能够完全控制人工场景的构成因素,合成我们希望得到的图像。图像风格迁移、生成式模型等方法能够进一步提高人工图像的多样性。因此,与实际图像数据集相比,人工图像数据集似乎更加多样。
最后,人工图像的规模几乎不受限制。只要计算和存储资源充足,人工图像的规模可以任意大。对于图形渲染方法来说,可以在人工场景中灵活配置虚拟摄像机,“拍摄”无限多的人工图像,同时避免了在真实世界中安装摄像机的成本和麻烦。更加重要的是,人工图像的真值标记信息能够自动生成,无需费时费力的手动标注。图像风格迁移、生成式模型等方法也能够增加人工图像的规模,并且保持或者自动得到人工图像的标记信息。因此,带标记人工图像的规模可以远远超过带标记实际图像的规模。
总之,人工图像系统有潜力建立生成大规模、多样化、带标记的人工图像数据集,有助于避免视觉模型的过拟合,提高其泛化能力。理论上,人工图像的逼真性可以无限接近实际图像的逼真性,利用判别器甚至无法分辨这两种逼真性。尽管如此,由于人工图像和实际图像来自不同的领域,存在数据集偏移(Dataset bias)问题,需要进行领域适应。
人工图像数据集可以用来学习和评估视觉模型。由于人工图像和实际图像来自不同的领域,在分布上存在差距(即数据集偏移),从人工图像学习得到的模型,直接应用于实际图像时性能未必良好,或者有进一步提升的空间。可以利用3种领域适应策略,来处理数据集偏移问题。
1)无监督领域适应策略:利用大规模带标记的人工图像数据和大规模无标记的实际图像数据,来训练视觉模型。该策略不需要目标领域的任何带标记数据。最近的一些方法[30-32]基于该策略学习图像特征,使其对标记预测任务具有判别性,同时对领域变化具有不变性。
2)监督领域适应策略:利用大规模带标记的人工图像数据和小规模带标记的实际图像数据,来训练视觉模型。该策略没有使用无标记的实际数据。一种简单有效的领域适应方法[33-34]是将人工和实际数据混合,作为一个共同的训练集来训练模型;另一种常用方法[35-39]是首先利用人工数据来训练模型,然后利用实际数据来微调模型。
3)半监督领域适应策略:利用大规模带标记的人工图像数据、小规模带标记的实际图像数据、大规模无标记的实际图像数据,来训练视觉模型。由于利用的数据最多,该策略通常能够产生最好的性能。
我们借用Ganin等[31]提出的一个例子,来解释上述三种领域适应策略的效果。这个例子是关于训练深度CNN来识别43类交通标志,作者评价五种模型训练方法。图10显示了在训练迭代过程中,验证错误的变化曲线。图10 中,Real和Syn表示可用的带标记数据(430幅实际图像和100000幅人工图像),Adapted表示利用大约31000幅无标记的目标领域实际图像进行领域适应,半监督领域适应策略获得的性能最好。由于带标记的实际图像规模太小(只有430幅),单纯利用带标记的实际图像,训练的模型产生最高的验证错误。利用100000幅带标记的人工图像,训练的模型能够小范围地降低验证错误,但是由于数据集偏移,验证错误仍然很高。利用无监督领域适应策略,虽然缺少来自目标领域的带标记数据,大幅下降验证错误。监督领域适应策略进一步提高性能。最终,半监督领域适应策略获得的性能最好,也许因为利用最多的数据。这个例子充分说明领域适应对于模型学习与训练的重要性,其中半监督领域适应策略最有效。
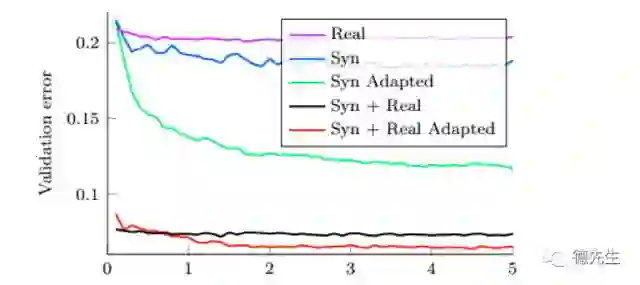
图10 五种模型训练方法得到的交通标记分类结果[31]
Fig. 10 Results fortraffic sign classification with five model training methods
我们认为,平行图像今后将朝着逼真性、多样性、快速性、智能性的方向发展,使生成的人工图像更加逼真和多样,生成速度更快,生成过程更加智能。为此,需要发展新的数学工具[40]和模型,进一步强化深度学习、对抗学习、平行学习等机器学习技术在图像风格迁移和生成式模型中的应用。并且与具体应用场景相结合,基于预测学习和集成学习思想,引导图像生成的方向。
传统上,图像生成主要依靠传感,现在却越来越依赖于计算。现代图像生成系统与传感、光学、算法、计算等紧密结合。计算摄影学、计算显微术、移动和分布式成像等新兴领域与压缩感知、贝叶斯反演等算法相结合,极大扩展了传统图像生成的范畴。由于传感和计算的深度融合,催生了一个新的交叉学科方向——计算成像(Computational imaging)。计算成像不只关注对图像的处理,更关注图像生成,以及传感与计算的融合。自从2015年国际期刊IEEE Transactions on Computational Imaging[46]创刊以来,计算成像的研究和发展速度明显加快。
本文提出的平行图像,与计算成像的思想非常契合。平行图像是一个虚实结合的图像生成理论框架,不仅包括由传感直接生成的实际图像,还包括经计算生成的人工图像。本文所述的人工图像系统尽管有多种实现方法,但整体上与计算成像系统类似,都是传感、光学、算法和计算的结合。因此,可以把计算成像系统的输出作为人工图像。可以借鉴计算成像领域的研究成果,深化平行图像的研究。
在硬件方面,目前实际图像由摄像机拍摄,而人工图像主要在计算机上生成。未来,平行图像硬件系统的集成化程度会越来越高,很可能出现将实际图像、人工图像一体化生成的新型摄像机,可以称为“平行摄像机(Parallel camera)”。平行摄像机嵌入了高速计算单元,集成了传感(生成实际图像)和计算(生成人工图像)功能,可以同时输出一路实际图像和多路人工图像,直接用来对视觉模型进行全面充分的学习与评估。
本文提出一个新型的图像生成理论框架,即平行图像。作为平行视觉的一个分支,平行图像用人工图像来扩展实际图像:从实际场景中获取特定的图像“小数据”,输入人工图像系统,生成大量新的人工图像数据。人工图像“大数据”和实际图像“小数据”一起构成解决复杂视觉问题所需要的平行图像“大数据”集合,应用于随后的计算实验和平行执行。本文还总结了已有的人工图像生成方法,包括图形渲染、图像风格迁移、生成式模型等。并且对比分析了人工图像和实际图像的特点,讨论领域适应策略。
平行图像理论与目前的计算成像研究方向密切相关。我们预测,平行图像在算法和软件上将朝着逼真性、多样性、快速性和智能性的方向发展,在硬件上会朝着传感和计算单元集成化的方向发展。最终很可能出现一种新的图像生成仪器设备——平行摄像机,能够同时生成一路实际图像和多路人工图像,我们期待这一刻的早日到来。
[1] WANG K F, LIU Y Q, GOU C, et al. A Multi-view Learning App-roach to Foreground Detection for Traffic Surveillance Applications. IEEE Transactions on Vehicular Technology, 2016, 65(6): 4144-4158.
[2] WANG K F, YAO Y J. Video-Based Vehicle Detection Approach with Data-Driven Adaptive Neuro-Fuzzy Networks. International Journal of Pattern Recognition and Artificial Intelligence, 2015, 29(7). DOI: 10. 1142/ S0218001415550150.
[3] GOU C, WANG K F, YAO Y J, et al. Vehicle License Plate Recognition Based on Extremal Regions and Restricted Boltzmann Ma-chines. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(4): 1096-1107.
[4] LIU Y Q, WANG K F, SHEN D Y. Visual Tracking Based on Dynamic Coupled Conditional Random Field Model. IEEE Transactionson Intelligent Transportation Systems, 2016, 17(3): 822-833.
[5] 王坤峰,苟超,王飞跃. 平行视觉:基于ACP 的智能视觉计算方法. 自动化学报, 2016, 42(10): 1490-1500.
(WANG K F, GOU C, WANG F Y. Parallel Vision: An ACP-Based Approach to Intelligent Vision Computing. Acta Automatica Sinica, 2016, 42(10): 1490-1500. )
[6] 王飞跃. 平行系统方法与复杂系统的管理和控制. 控制与决策,2004, 19(5): 485-489.
(WANG F Y. Parallel System Methods for Management and Control of Complex Systems. Control and Decision, 2004, 19(5): 485-489. )
[7] WANG F Y. Parallel Control and Management for Intelligent Transportation Systems: Concepts, Architectures, and Applications. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 630-638.
[8] 王飞跃. 平行控制:数据驱动的计算控制方法. 自动化学报,2013, 39(4): 293-302.
(WANG F Y. Parallel Control: A Method for Data-Driven and Computational Control. Acta Automatica Sinica, 2013, 39(4): 293-302.)
[9] MIAO Q H, ZHU F H, LV Y S, et al. A Game-Engine-Based Plat-form for Modeling and Computing Artificial Transportation Systems. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(2): 343-353.
[10] WANG F Y, ZHANG J J, ZHENG X H, et al. Where Does AlphaGo Go: From Church-Turing Thesis to AlphaGo Thesis and Beyond. IEEE/ CAA Journal of Automatica Sinica, 2016, 3(2): 113-120.
[11] ZHANG N, WANG F Y, ZHU F H, et al. DynaCAS: Computational Experiments and Decision Support for ITS. IEEE Intelligent Systems, 2008, 23(6): 19-23.
[12] WANG F Y, WANG X, LI L X, et al. Steps toward Parallel Intelligence. IEEE/CAA Journal of Automatica Sinica, 2016, 3(4): 345-348.
[13] TORRALBA A, EFROS A A. Unbiased Look at Dataset Bias / /Proc of the IEEE Conference on Computer Vision and Pattern Re-cognition. Washington, USA: IEEE, 2011: 1521-1528.
[14] MODEL I, SHAMIR L. Comparison of Data Set Bias in Object Recognition Benchmarks. IEEE Access, 2015, 3: 1953-1962.
[15] 李力,林懿伦,曹东璞,等. 平行学习——机器学习的一个新型理论框架. 自动化学报, 2017, 43(1): 1-8.
(LI L, LIN Y L, CAO D P, et al. Parallel Learning-A New Framework for Machine Learning. Acta Automatica Sinica, 2017,43(1): 1-8. )
[16] LI L, LIN Y, ZHENG N, et al. Parallel Learning: a Perspective and a Framework. IEEE/CAA Journal of Automatica Sinica, 2017, 4(3): 389-395.
[17] LUAN F J, PARIS S, SHECHTMAN E, et al. Deep Photo Style Transfer[ J/ OL]. [2017-06-25]. https:/ / www. cs. cornell.edu/ ~ fujun/ files/ style-cvpr17/ style-cvpr17.pdf.
[18] HERTZMANN A, JACOBS C E, OLIVER N, et al. Image Analogies / / Proc of the 28th Annual Conference on Computer Graphics and Interactive Techniques. New York, USA: ACM, 2001: 327-340.
[19] OKURA F, VANHOEY K, BOUSSEAU A, et al. Unifying Color and Texture Transfer for Predictive Appearance Manipulation / /Proc of the Euro graphics Symposium on Rendering. Berlin, Germany: Springer, 2015: 53-63.
[20] EFROS A A, FREEMAN W T. Image Quilting for Texture Synthesis and Transfer / / Proc of the 28th Annual Conference on Computer Graphics and Interactive Techniques. New York, USA: ACM, 2001: 341-346.
[21] ASHIKHMIN N. Fast Texture Transfer. IEEE Computer Graphics and Applications, 2003, 23(4): 38-43.
[22] GATYS L A, ECKER A S, BETHGE M. Image Style Transfer Using Convolutional Neural Networks / / Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2016: 2414-2423.
[23] 王坤峰,苟超,段艳杰,等. 生成式对抗网络GAN 的研究进展与展望. 自动化学报, 2017, 43(3): 321-332.
(WANG K F, GOU C, DUAN Y J, et al. Generative Adversarial Networks: The State of the Art and Beyond. Acta Automatica Sini-ca, 2017, 43(3): 321-332. )
[24] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative Adversarial Nets / / GHAHRAMANI Z, WELLING M, CORTES C, et al. , eds. Advances in Neural Information Processing Systems 27. Cambridge, USA: The MIT Press, 2014: 2672- 2680.
[25] BERTHELOT D, SCHUMM T, METZ L. BEGAN: Boundary Equilibrium Generative Adversarial Networks[C/ OL]. [2017-06-25]. https:/ / arxiv.org/pdf/1703.10717.pdf
[26] ZHAO J B, MATHIEU M, LECUN Y. Energy-Based Generative Adversarial Network[C/OL]. [2017 -06 -25]. https:/ / arxiv.org/pdf/1609. 03126.pdf.
[27] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein GAN[C/OL]. [2017-06-25]. https://arxiv.org/pdf/1701.07875v1.pdf.
[28] SHRIVASTAVA A, PFISTER T, TUZEL O, et al. Learning from Simulated and Unsupervised Images through Adversarial Training[C/OL]. [2017-06-25]. https://arxiv.org/ pdf/1612. 07828.pdf.
[29] ZHU J Y, PARK T, ISOLA P, et al. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks[C/OL].[2017-06-25]. https:/ /arxiv.org/pdf/1703.10593.pdf
[30] CHEN W Z, WANG H, LI Y Y, et al. Synthesizing Training Images for Boosting Human 3D Pose Estimation / / Proc of the 4th International Conference on 3D Vision. Washington, USA: IEEE, 2016: 479-488.
[31] GANIN Y, USTINOVA E, AJAKAN H, et al. Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Re-search, 2016, 17: 1-35.
[32] GHIFARY M. Domain Adaptation and Domain Generalization with Representation Learning. Ph. D Dissertation. Wellington, New Zealand: Victoria University of Wellington, 2016.
[33] ROS G, SELLART L, MATERZYNSKA J, et al. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes / / Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2016: 3234-3243.
[34] MOVSHOVITZ-ATTIAS Y, KANADE T, SHEIKH Y. How Use fulIs Photo-Realistic Rendering for Visual Learning? [ C/ OL ]. [2017-06-25]. https://arxiv.org/pdf/1603.08152.pdf.
[35] VÁZQUEZ D, LÓPEZ A M, MARÍN J, et al. Virtual and Real World Adaptation for Pedestrian Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(4): 797-809.
[36] XU J L, VÁZQUEZ D, LÓPEZ AM, et al. Learning a Part-Based Pedestrian Detector in a Virtual World. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(5): 2121-2131.
[37] XU J L, RAMOS S, VÁZQUEZ D, et al. Domain Adaptation of Deformable Part-Based Models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(12): 2367-2380.
[38] HANDA A, PĂTRĂUCEAN V, BADRINARAYANAN V, et al. Understanding Real World Indoor Scenes with Synthetic Data[C/OL]. [2017-06-25]. https:/ /arxiv.org/pdf/1511.07041.pdf.
[39] GAIDON A, WANG Q, CABON Y, et al. Virtual Worlds as Proxy for Multi-object Tracking Analysis / / Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2016: 4340-4349.
[40] 王飞跃,莫红. 关于二型模糊集合的一些基本问题. 自动化学报, 2017, 43(7): 1114-1141.
(WANG F Y, MO H. Some Fundamental Issues on Type-2 Fuzzy Sets. Acta Automatica Sinica, 2017, 43(7): 1114-1141. )

王坤峰, 男, 1982年生, 博士, 副研究员, 主要研究方向为智能交通系统、智能视觉计算和机器学习. E-mail: kunfeng.wang@ia.ac.cn.
(WANG Kunfeng, born in 1982, Ph.D., associateprofessor. His research interests include intelligent transportation systems, intelligentvision computing, and machine learning.)

鲁越, 男, 1994年生, 硕士研究生, 主要研究方向为平行视觉、机器学习和生成式对抗网络. E-mail: luyue2016@ia.ac.cn.
(LU Yue, born in 1994, master student. Hisresearch interests include parallel vision, machine learning, and generativeadversarial networks.)

王雨桐, 女, 1994年生, 博士研究生, 主要研究方向为计算机图形学、图像处理和智能交通系统. E-mail: wangyutong2016@ia.ac.cn.
(WANG Yutong, born in 1994, Ph.D. student.Her research interests include computer graphics, image processing, andintelligent transportation systems.)

熊子威, 男, 1996年生, 本科生, 主要研究方向为机器学习和图像处理. E-mail: noahxiong@outlook.com.
(XIONG Ziwei, born in 1996, undergraduatestudent. His research interests include machine learning and image processing.)

王飞跃(通讯作者), 男, 1961年生, 博士, 研究员, 主要研究方向为智能系统和复杂系统的建模、分析与控制. E-mail: feiyue.wang@ia.ac.cn.
(WANG Fei-Yue (Corresponding author),born in 1961, Ph.D., professor. His research interests include modeling,analysis, and control of intelligent systems and complex systems.)
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【分析】图像分类、目标检测、图像分割、图像生成……一文「计算机视觉」全分析
☞ 【智能自动化学科前沿讲习班第1期】哈工大左旺孟教授:多领域视觉数据的转换、关联与自适应学习
