CVPR 2018 | 使用CNN生成图像先验,实现更广泛场景的盲图像去模糊
来源:机器之心
“现有的最优方法在文本、人脸以及低光照图像上的盲图像去模糊效果并不佳,主要受限于图像先验的手工设计属性。本文研究者将图像先验表示为二值分类器,训练 CNN 来分类模糊和清晰图像。实验表明,该图像先验比目前最先进的人工设计先验更具区分性,可实现更广泛场景的盲图像去模糊。”
简介
盲图像去模糊(blind image deblurring)是图像处理和计算机视觉领域中的一个经典问题,它的目标是将模糊输入中隐藏的图像进行恢复。当模糊形状满足空间不变性的时候,模糊过程可以用以下的方式进行建模:
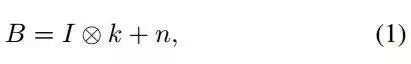
其中⊗代表的是卷积算子,B、I、k 和 n 分别代表模糊图像、隐藏的清晰图像、模糊核以及噪声。式(1)中的问题是不适定性,因为 I 和 k 都是未知的,存在无穷多个解。为了解决这个问题,关于模糊核和图像的额外约束和先验知识都是必需的。

图1:一个去模糊的例子。本文提出了一个判别图像先验,它是从用于图像去模糊的深度二分类网络中学习得到的。
二值分类器
最近的去模糊方法的成功主要来自于有效图像先验和边缘检测策略方面的研究进展。然而,基于边缘预测的方法常常会涉及到启发式的边缘选择步骤,当边缘不可预测的时候,这种方法表现不佳。
为了避免启发式的边缘选择步骤,人们提出了很多基于自然图像先验的算法,包括稀疏性归一化(normalized sparsity)[16]、L0 梯度 [38] 和暗通道先验(dark channel prior)[27]。
这些算法在一般的自然图像上表现良好,但是并不适用于特殊的场景,例如文本 [26]、人脸 [25] 以及低光照图像 [11]。大多数上述的图像先验都有相似的效果,它们更加适用于清晰的图像,而不是模糊的图像,这种属性有助于基于 MAP(最大后验)的盲图像去模糊方法的成功。
然而,大多数先验都是手工设计的,它们主要是基于对特定图像统计的有限观察。这些算法不能很好地泛化以处理自然环境中的多种场景。所以,开发能够使用 MAP 框架来处理不同场景的图像先验是很有意义的。
为达到这个目的,研究者将图像先验表示为能够区分清晰图像和模糊图像的二值分类器。具体来说,他们训练深度卷积神经网络来分类模糊图像 (标记为 1 ) 和清晰图像 (标记为 0 )。由于基于 MAP(最大后验)的去模糊方法通常使用 coarse-to-fine(由粗到精)策略,因此在 MAP 框架中插入具有全连接层的 CNN 无法处理不同大小的输入图像。
为了解决这个问题,他们在 CNN 中采用了全局平均池化层 [ 21 ],以允许学习的分类器处理不同大小的输入。此外,为了使分类器对不同输入图像尺寸具有更强的鲁棒性,他们还采用多尺度训练策略。然后将学习到的 CNN 分类器作为 MAP(最大后验)框架中潜在图像对应的正则项。如图 1 所示,本文提出的图像先验比目前最先进的人工设计的先验 [ 27 ] 更具区分性。
然而,使用学习到的图像先验去优化这个去模糊方法是很困难的,因为这里涉及到了一个非线性 CNN。因此,本文提出了一种基于半二次方分裂法(half-quadratic splitting method)和梯度下降算法的高效数值算法。这个算法在实际使用中可以快速地收敛,并且可以应用在不同的场景中。此外,它还可以直接应用在非均匀去模糊任务中。
本文的主要贡献如下:
提出了一种高效判别图像先验,它可以通过深度卷积神经网络学习到,用于盲图像去模糊。为了保证这个先验(也就是分类器)能够处理具有不同大小的输入图像,研究者利用全局平均池化和多尺度训练策略来训练这个卷积神经网络。
将学习到的分类器作为 MAP(最大后验)框架中潜在图像对应的正则化项,并且提出了一种能够求解去模糊模型的高效优化算法。
研究者证明,与当前最佳算法相比,这个算法在广泛使用的自然图像去模糊基准测试和特定领域的去模糊任务中都具备有竞争力的性能。
研究者展示了这个方法可以直接泛化到非均匀去模糊任务中。
二分类网络
我们的目标是通过卷积神经网络来训练一个二分类器。这个网络以图像作为输入,并输出一个标量数值,这个数值代表的是输入图像是模糊图像的概率。因为我们的目标是将这个网络作为一种先验嵌入到由粗到精的 MAP(最大后验)框架中,所以这个网络应该具备处理不同大小输入图像的能力。
所以,我们将分类其中常用的全连接层用全局平均池化层代替 [21]。全局平均池化层在 sigmoid 层之前将不同大小的特征图转换成一个固定的大小。此外,全局平均池化层中没有额外的参数,这样就消除了过拟合问题。图 2 展示了整个网络架构和二分类网络的细节参数。
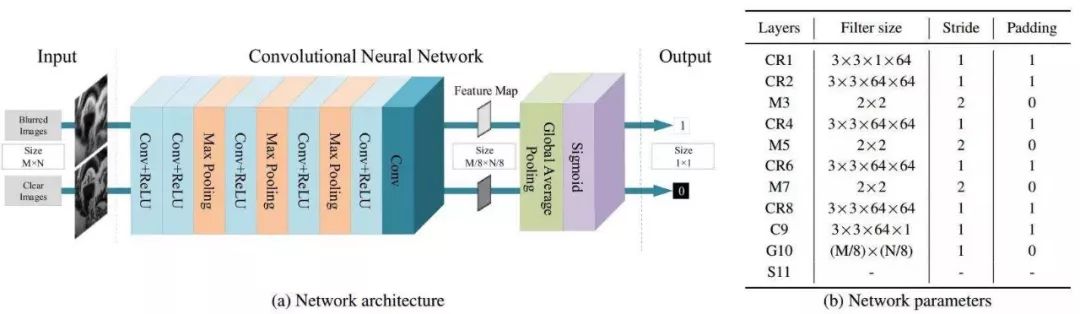
图2:本文中使用的二分类网络的架构和参数,其中使用了全局平均池化层取代全连接层来应对不同大小的输入。CR代表的是后面跟着一个ReLU非线性函数的卷积层,M代表的是最大池化层,C代表的是卷积层,G指的是全局平均化池化层,S代表的是Sigmoid非线性函数。

图3:数据集【15】中的一个很具挑战性的例子。本文提出的方法以更少的边缘震荡效应和更好的视觉预约度恢复了模糊图像。

图4:在实际的模糊图像中的去模糊结果。本文的结果更加清晰,失真较少。
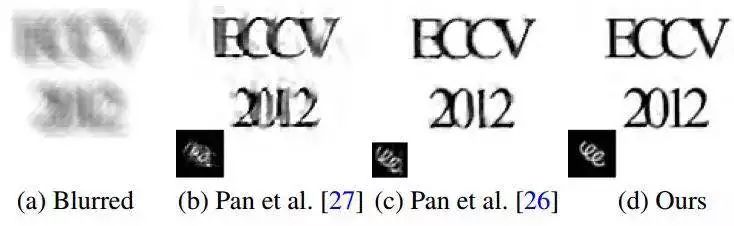
图5:本文图像上的去模糊结果。与目前最先进的去模糊算法【26】相比,本文的方法生成了更加尖锐的的去模糊图像,其中的字符更加清晰。

图6:去模糊结果和中间结果。作者在图(a)-(d)中与目前最陷阱的方法【40,27】比较了解去模糊结果,并在(e)-(h)中展示了迭代中的(从左至右)中间隐藏图像。本文的判别先验恢复了用于核估计的具有更强边缘的中间结果。
论文:Learning a Discriminative Prior for Blind Image Deblurring(学习用于盲图像去模糊的判别先验)

论文链接:https://arxiv.org/abs/1803.03363
我们提出了一种基于数据驱动的判别先验的盲图像去模糊方法。我们的工作是基于这样一个事实:一个好的图像先验应该有利于清晰的图像而不是模糊的图像。
在本文中,我们将图像先验表示为一个二值分类器,它可以通过一个深度卷积神经网络 ( CNN ) 来实现。学习到的先验能够区分输入图像是否清晰。嵌入到最大后验 ( MAP ) 框架中之后,它有助于在各种场景 (包括自然图像、人脸图像、文本图像和低照明图像) 中进行盲去模糊。
然而,由于去模糊方法涉及非线性 CNN,因此很难优化具有学习已图像先验的去模糊方法。为此,本文提出了一种基于半二次分裂法和梯度下降法的数值求解方法。此外,该模型易于推广到非均匀去模糊任务中。定性和定量的实验结果表明,与当前最优的图像去模糊算法以及特定领域的图像去模糊方法相比,该方法具备有竞争力的性能。
*推荐文章*
CVPR2018|DiracNets:无需跳层连接,训练更深神经网络,结构参数化与Dirac参数化的ResNet





