【学界】基于平行视觉的特定场景下行人检测
作者:张文文
审校:王坤峰
【导读】本文介绍了来自中国科学院自动化研究所复杂系统管理与控制国家重点实验室的研究成果。在特定场景的智能监控中,训练数据与测试数据通常存在巨大的分布差异,影响目标检测模型的性能。于是,张文文博士生、王坤峰副研究员、王飞跃研究员等提出了一种基于平行视觉的特定场景下行人检测方法[1]。他们利用增强现实技术将虚拟行人添加到特定场景背景中,构成人工场景;从人工场景中收集大量的带标注数据,训练行人检测模型;再应用到特定场景,取得良好的行人检测效果。
论文的下载地址如下:
https://arxiv.org/abs/1712.08745

平行视觉理论基础
平行视觉是一种虚实互动的智能视觉计算方法,是王坤峰、王飞跃等将复杂系统建模与调控的ACP (Artificial Societies, Computational Experiments, and Parallel Execution)方法推广到视觉计算领域而提出的。平行视觉的核心是利用人工场景来模拟和表示复杂挑战的实际场景,通过计算实验进行各种视觉模型的设计和评估,最后借助于平行执行来在线优化视觉系统,实现对复杂场景的智能感知与理解。图1显示了平行视觉的基本框架。
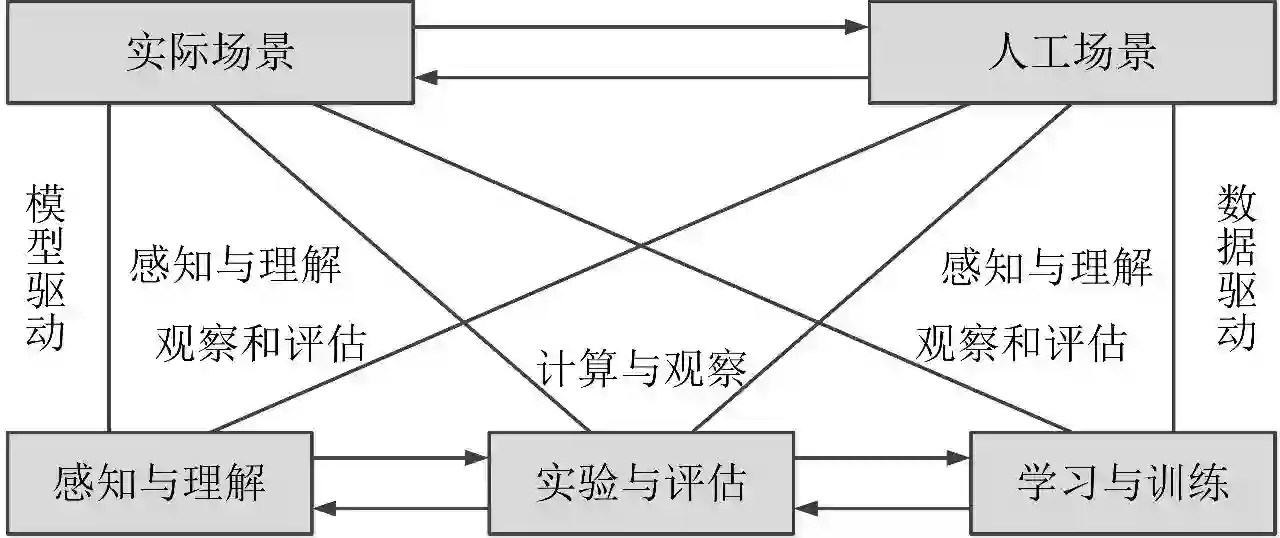
图1. 平行视觉的基本框架
平行视觉方法主要包括ACP三个步骤:
第一步:人工场景。构建色彩逼真、模型丰富、布局合理的人工场景,通过调节人工场景的组成要素,可以模拟得到大量不同环境条件下的人工场景,渲染并收集大规模多样化的虚拟图像数据集。利用人工场景中已知的结构布局信息,可以自动生成虚拟图像的标注信息,避免了费时费力的手动标注。
第二步:计算实验。结合实际场景与人工场景的数据集,可以进行可控、可观、可重复的计算实验,把人工场景变成视觉计算研究的实验室。计算实验分为两种操作模式,即学习与训练、实验与评估。学习与训练是针对视觉算法设计而言,实验与评估是针对视觉算法评价而言。
第三步:平行执行。将视觉算法在实际场景与人工场景中平行执行,使模型训练和评估在线化、长期化。通过实际与人工之间的虚实互动,持续优化视觉系统。由于应用环境的复杂性、挑战性和变化性,不存在一劳永逸的解决方案,只能接受这些困难,以交互反馈方式进行在线调节和改善。
构建特定场景的人工场景
近年来,随着硬件计算能力的快速提升,深度学习在视觉计算研究中发挥了重要作用。例如目标检测、图像分类等应用,在深度学习的支持下都取得了空前的进步。但是深度学习是一种数据驱动的技术,需要进行大规模多样化训练数据的收集和标注。传统上主要采用手动标注数据的方式,费时费力,效率极低。
通用场景与特定场景在摄像机角度、光照、天气等条件不同,训练数据与测试数据存在巨大的分布差异,直接利用通用场景的数据集训练行人检测模型,在特定场景下的检测精度急剧下降。而基于特定场景进行数据收集,是一项费时而繁重的工作。
利用计算机图形学和增强现实技术,可以为特定场景构建人工场景。一方面,人工场景中的目标外观与运动属性具有逼真性、多样性,与实际场景中的情形一致。另一方面,人工场景具有可控、可观、可重复、可自动标注等特点,增加了数据采集的灵活性,降低了数据标注成本。最终,将来自人工场景的大数据,转化为面向特定场景的“小知识”。
于是,张文文等基于平行视觉理论,在论文[1]中提出了面向特定场景的行人检测方法。他们采用增强现实技术,将虚拟的行人叠加到特定场景的背景图像,构建人工场景,生成带有标注信息的虚拟数据集。利用人工场景生成带标注的虚拟数据,训练特定场景的行人检测模型,取得了良好的效果。图2展示了特定场景的虚拟数据的生成过程。
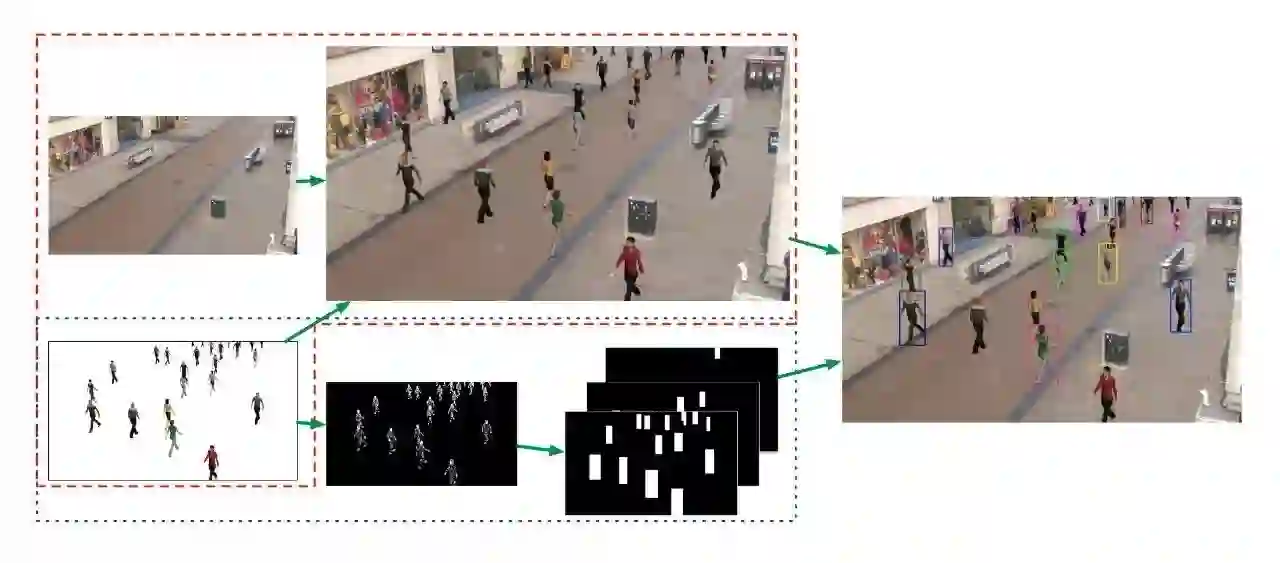
加入虚拟行人并生成数据
根据得到的摄像机参数和场景的几何分布,结合常见的3D模型工具,将3D目标模型加入特定场景中,形成逼真的图像。下面的视频展示了渲染得到的虚拟数据。

生成标注信息
根据人工场景中行人的位置信息,通过顶点渲染得到行人的轮廓信息与位置的前后信息,通过最终的计算得到行人的边框标记信息,图3展示了行人边框标注生成的基本过程。

图3. 行人边框标注生成过程的示意图
利用人工场景数据进行模型训练
利用人工场景数据,对目标检测模型进行训练,然后将训练好的模型应用于实际的特定场景。这是平行视觉的计算实验的内涵之一。
实验结果
为了验证平行视觉方法在特定场景下行人检测中的作用,作者利用收集的数据集,在若干特定场景的行人检测任务上,分别利用目标检测模型DPM(Deformable Parts Model)和Faster R-CNN进行验证,都取得了改进的检测性能。利用特定场景的人工场景数据,训练的目标检测器,应用于特定场景时,在精度上超过了利用通用数据训练的通用检测器。图4展示了论文[1]中实验采用的特定场景及其人工场景。

图4. 实验采用的特定场景及其人工场景
在三个特定场景下,行人检测的平均精度和PR曲线如图5所示。从实验结果可知,利用人工场景产生的虚拟数据,能够很好地训练行人检测模型,在特定场景下的检测效果远远超过了利用通用数据训练得到的模型。
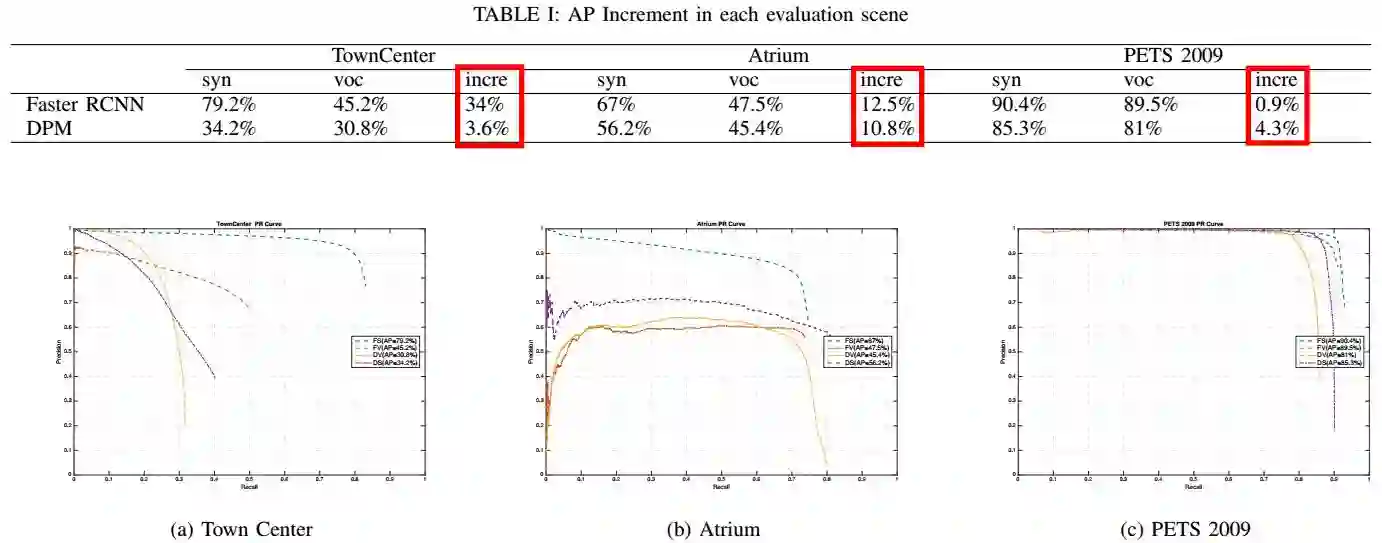
图5. 行人检测的平均精度和PR曲线
总结
利用人工场景,可以生成大规模、多样化、逼真、带标注的虚拟图像数据,解决数据采集和标注的困难,使研究人员可以把更多的精力放在视觉算法与模型的研究上。随着计算机图形学、虚拟/增强现实等技术的发展,人工场景与实际场景生成的图像几乎不可分辨。在人工场景中,可以灵活生成实际场景中没有得到关注或者极少出现的情形,为更加深入的视觉计算研究提供数据支撑。
平行视觉把视觉计算研究从单一的物理世界扩展到虚实结合的平行世界(物理世界+虚拟世界)。论文[1]验证了平行视觉方法可以用来提高特定场景视觉监控的性能,这只是平行视觉应用价值的一个实例。中科院自动化所王飞跃研究员、王坤峰副研究员带领的平行视觉研究团队,正在全面探索平行视觉理论与方法体系,大力推动视觉系统在智能交通、智能车辆等领域早日成熟应用。
参考文献
[1] Wenwen Zhang, Kunfeng Wang, Hua Qu, Jihong Zhao, and Fei-Yue Wang. Scene-Specific Pedestrian Detection Based on Parallel Vision. arXiv:1712.08745.
☞ 【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞ 【CFP】Virtual Images for Visual Artificial Intelligence
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【解析】当这位70岁的Hinton老人还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力(附Capsule)
☞ 【资源】Style2paints:专业的AI漫画线稿自动上色工具
☞ 【教程】用生成对抗网络给雪人上色,探索人工智能时代的美学
☞ 【技术】“微信身份证”AI显神威,人脸识别误判率百万分之一
☞ 【观点】LeCun:就通用智能而言,人工智能甚至还不如老鼠