新一代多模态文档理解预训练模型LayoutLM 2.0,多项任务取得新突破!

LayoutLM 2.0模型结构
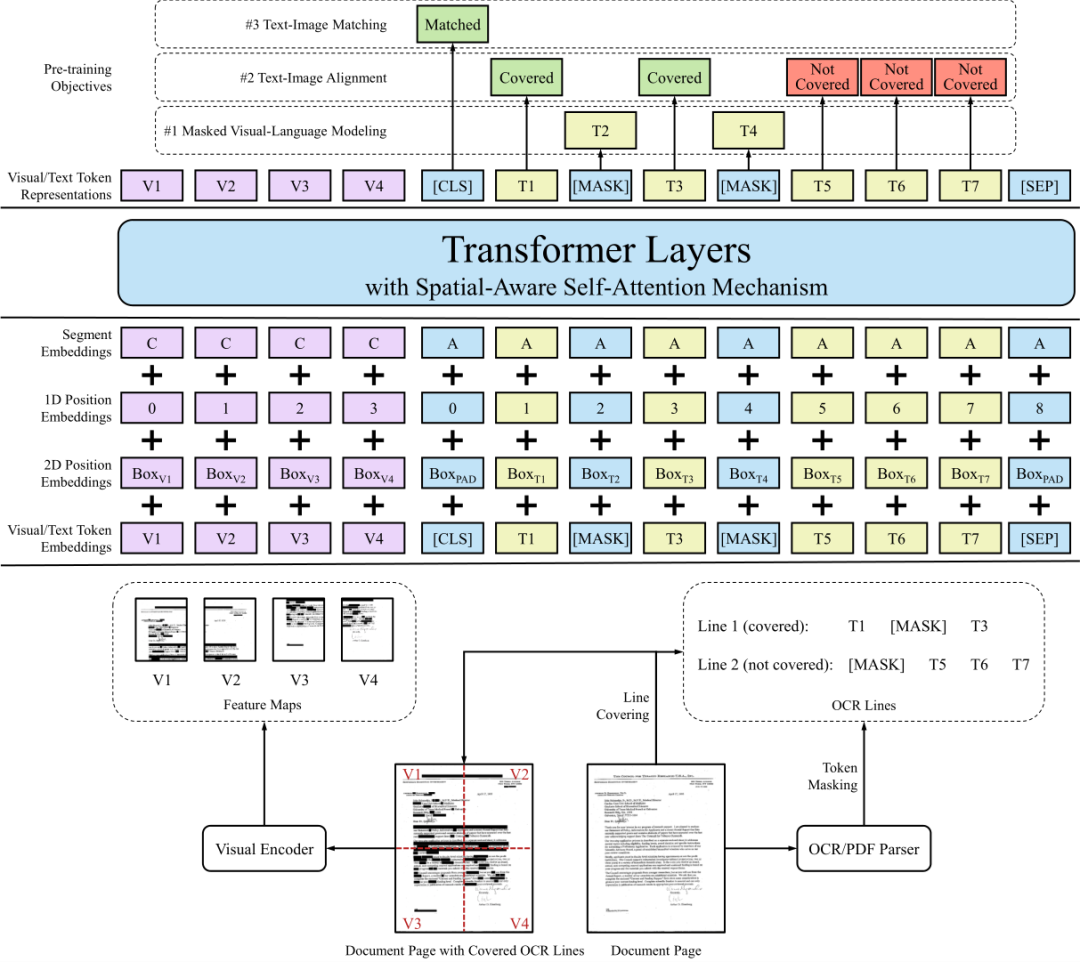
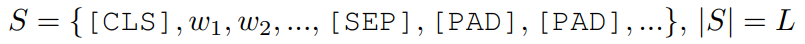
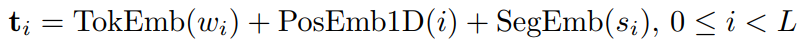
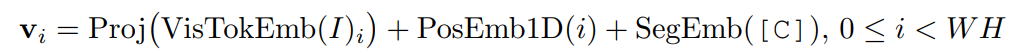
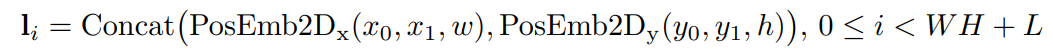
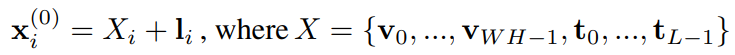
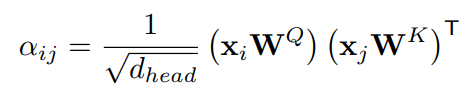
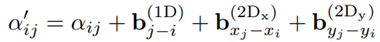
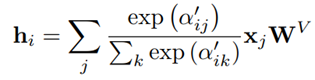
预训练任务
实验结果
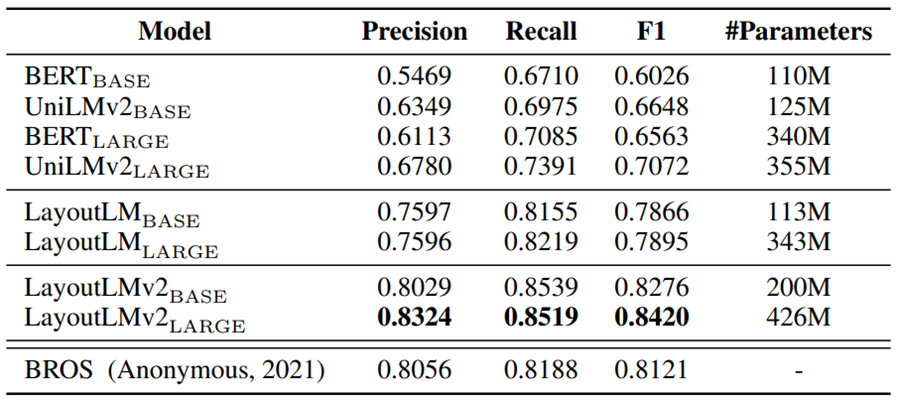
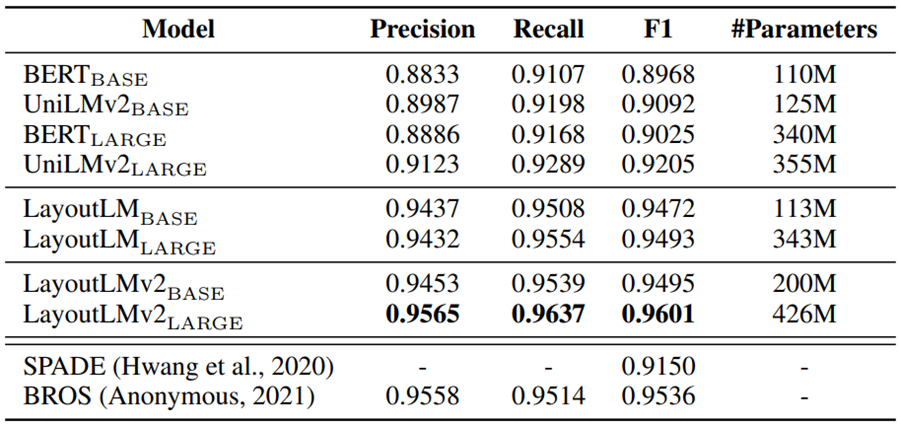
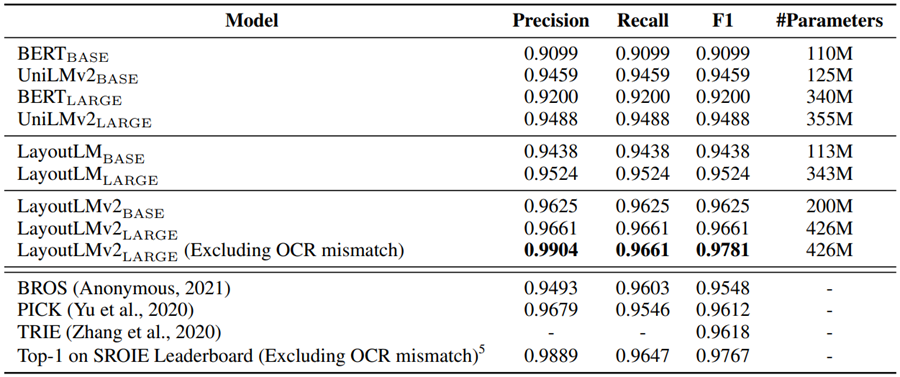
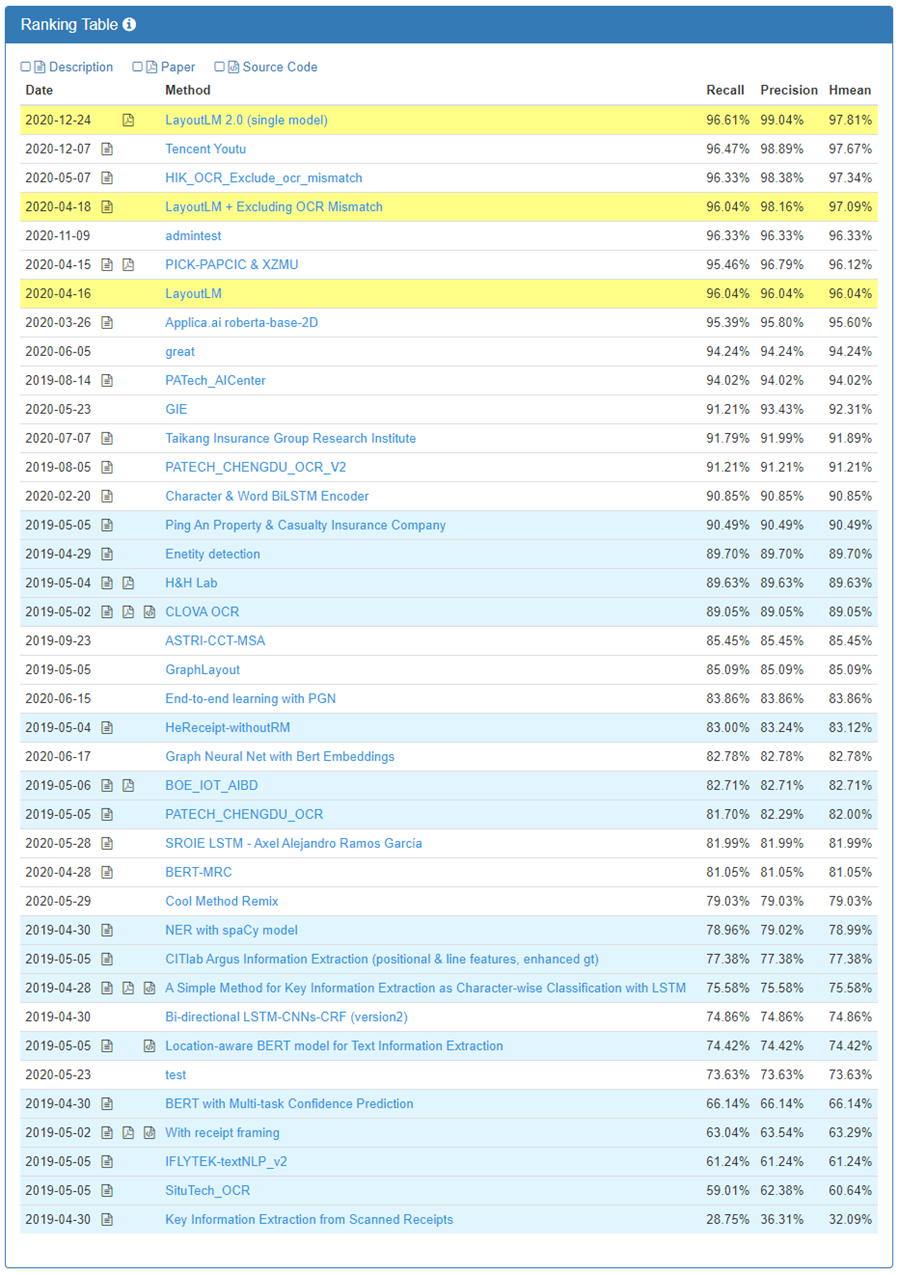
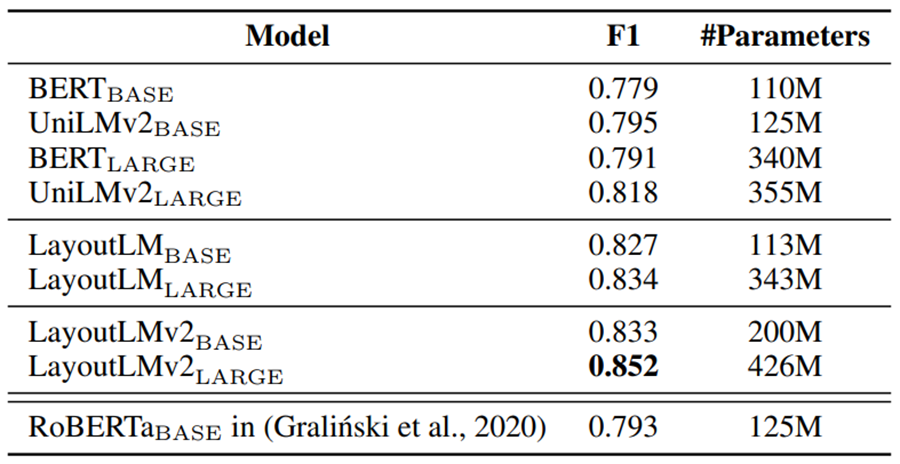
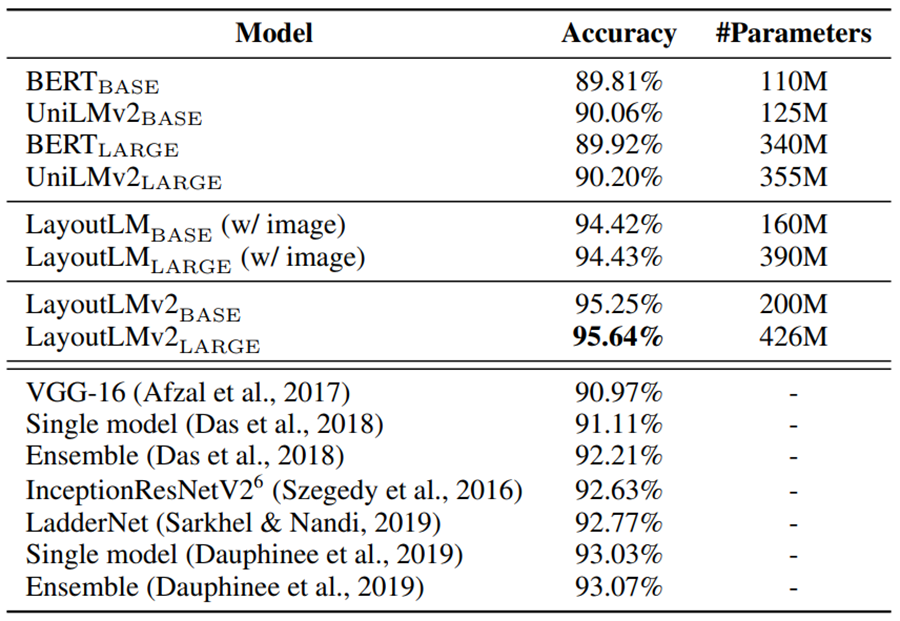
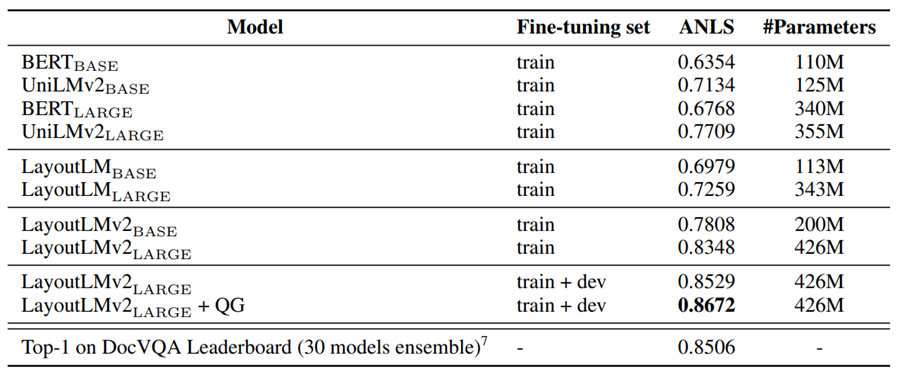
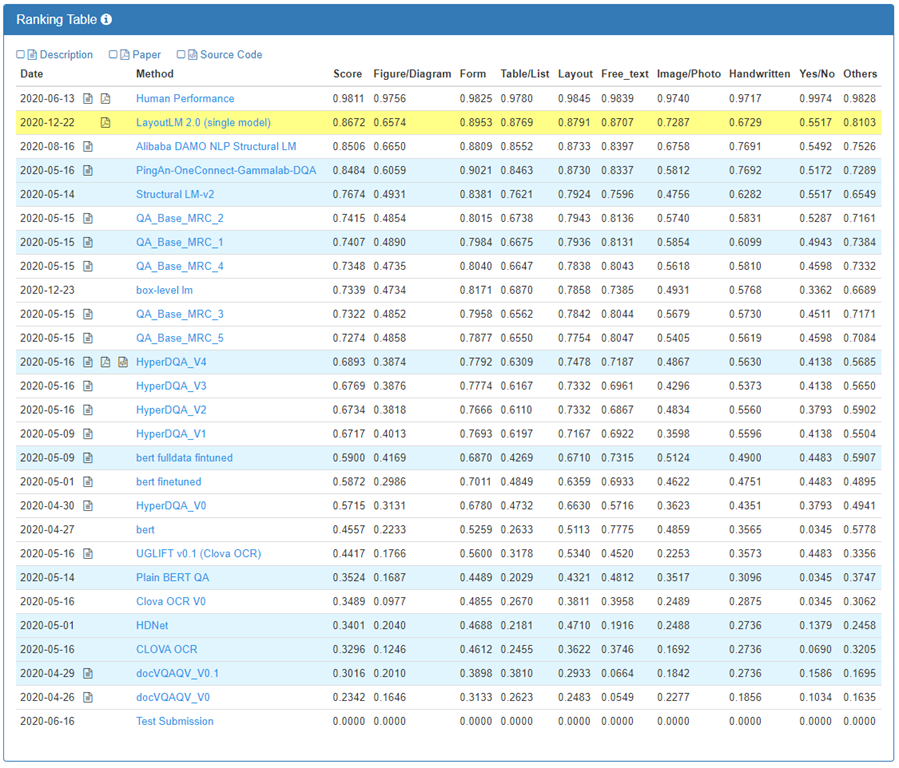

结论
食物、能源、水的短缺是人类面对的终极挑战。人工智能技术是我们面对这些挑战强有力的武器。最前沿的发展如何?我们如何突破困境?腾讯首席探索官网大为最新力作《重构地球:AI FOR FEW》,马化腾力荐!
AI科技评论为大家带来5本《重构地球:AI FOR FEW》正版新书。
在1月13日末条文章(注意不是本文!)《赠书福利!腾讯x先生论AI如何解决全球吃饭难题,马化腾力荐》留言区畅所欲言,谈一谈你对本书的看法。
AI 科技评论将会在留言区选出 5 名读者,每人送出《重构地球:AI FOR FEW》一本。

点击阅读原文,直达IJCAI小组!
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文