CVPR—Ⅲ | 经典网络再现,全内容跟踪
炎炎夏日,不知道大家搞科研的小伙伴有没有天气的燥热?但是,我们依然会继续分享最近的小系列——CVPR!接下来,我们还会继续分享17年的CVPR经典文章和得奖文章,希望可以鼓励更多朋友去阅读,一起在学习群里讨论。
还是先推荐几篇精彩好文:
先来个小视频解解暑!(这个系统很厉害,希望后期自己也可以实现一个!)
今天最大的主角是“HeKaiming”,因为开始说说“Residual Networks”!
Residual Networks
and
Analyse
Deep residual networks

Degeneration problem
CiFAR 100 Dataset
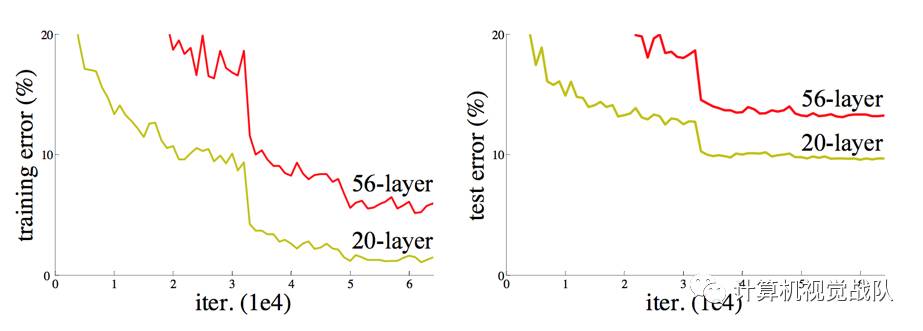
ImageNet
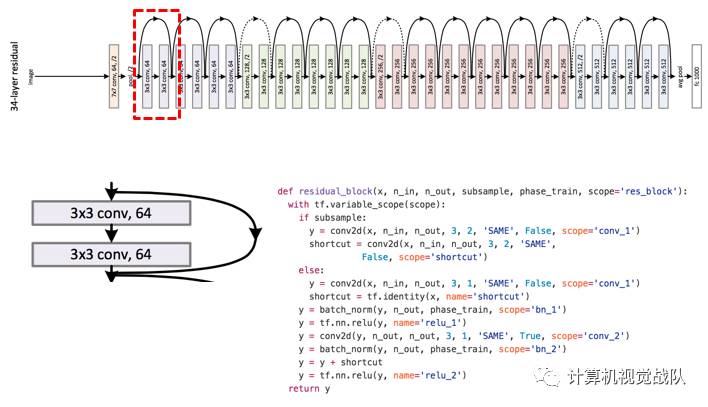
Residuallearning building block
残差网络主要的架构如下:
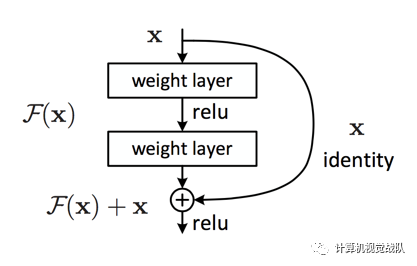
Residual learning building block

Why residual?
先假设优化残差映射比优化原始的更容易。使用了Shortcut connections。
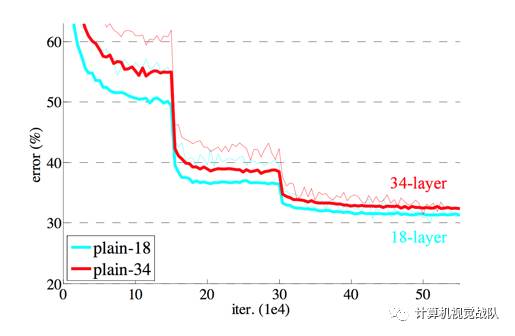
证明:deep residual nets 更容易去优化。
并且深度残差网络可以从大大增加深度的网络中轻松获得精确度,从而显着优于以前的网络。
Residualmappin
基本的残差映射(相同维度):
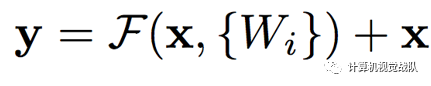
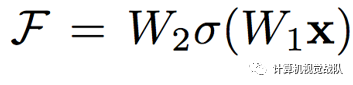
基本的残差映射(不同维度):
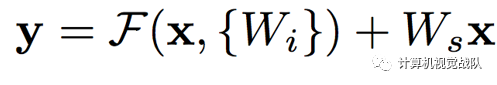
Deep residualnetwork
Deeper bottle architecture
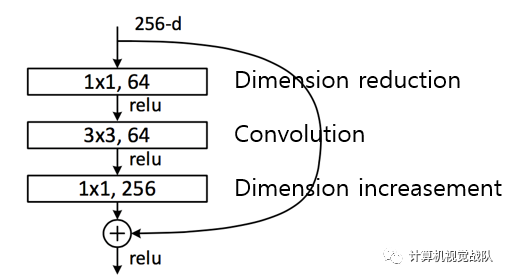
Experimentalresults
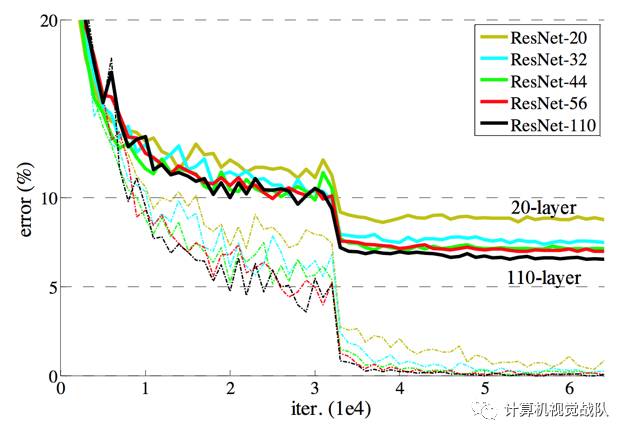
接下来说一个“深度不是最重要”的话题!
Depth is NOT that important
参考《Wide Residual Networks》
作者试图将Residual Networks尽可能薄,这样有利于增加其深度并减少参数,甚至还引入了“bottleneck”,使得ResNet模块更加的薄。
然而,我们注意到,具有identity mapping的residual block,允许训练非常深的网络同时是ResNet的弱点。 随着梯度流过网络,最后就没有可以迫使它通过residual block weights,并且可以避免在训练期间学习任何,所以有可能只有几个blocks可以学习有用的表示,或者很多blocks共享很少信息并对最终目标贡献小。
Experimental results
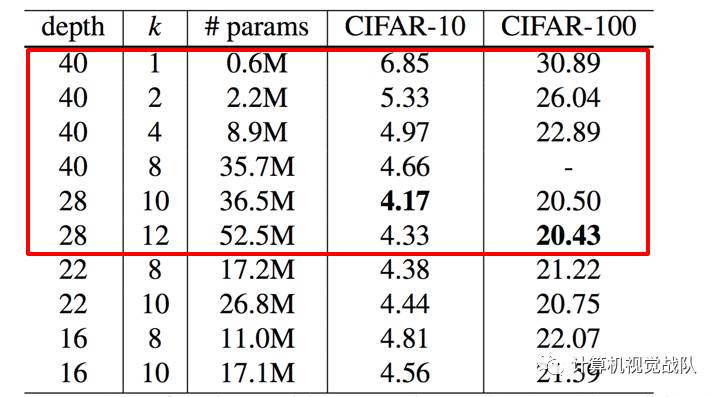
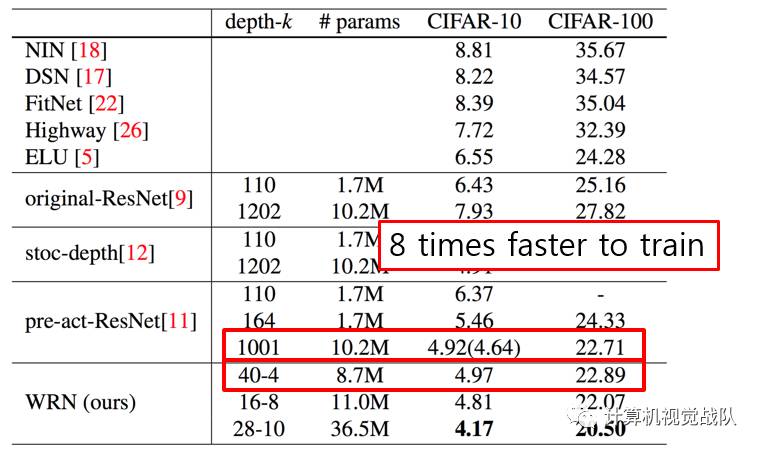
Summary
Widening consistently improves performance across residual networks of different depth;
Increasing both depth and width helps until the number of parameters becomes too high and stronger regularization is needed;
Wide networks can successfully learn with a 2 or more times larger number of parameters than thin ones, which would re-quire doubling the depth of thin networks, making them infeasibly expensive to train.
未完待续!!!






