如何解决计算机视觉中的深度域适应问题?

本文最初发布于 Towards Data Science,经原作者 Branislav Holländer 授权由 InfoQ 中文站翻译并发布。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
过去十年来,计算机视觉领域如盛壮之时的骐骥,一日而驰千里。这一进展主要归功于卷积神经网络不可否认的有效性。如果使用高质量、带注释的训练数据进行训练,卷积神经网络(Convolutional Neural Networks,CNN)可以进行非常精确的预测。例如,在分类设置中,你通常会使用一种标准的网络架构(如 ResNet、VGG 等),并使用你的数据集对其进行训练。这可能会得到非常好的性能。
另一方面,如果你没有为特定问题提供手动注释的大型数据集,卷积神经网络还允许利用已经通过迁移学习训练一个类似问题的网络的其他数据集。在这种情况下,你可以使用一个在大型数据集上预训练的网络,并使用你自己的带注释的小型数据集对其一些上层进行调优。
这两种方法,都假定你的训练数据(无论大小)都代表了基本分布。但是,如果测试时的输入与训练数据有显著差异,那么模型的性能可能不会很好。举个例子,假设你是一名自动驾驶汽车工程师,你想要分割汽车摄像头拍摄的图像,以便了解前方的情况(如建筑物、树木、其他汽车、行人、交通信号灯等)。NYC 数据集有很好的人工生成的注释,你可以使用这些注释来训练一个大型网络。你在曼哈顿的街道上测试你的自动驾驶汽车,一切似乎都很顺利。然后你在巴黎街道测试同样的系统,突然情况变得非常糟糕。这辆汽车再也无法探测到交通信号灯,它看到的汽车也非常不一样(因为巴黎的出租车没有黄色的),街道也不再那么笔直了。
你的模型在这些场景中表现不佳的原因是问题域发生了变化。在这种特殊情况下,输入数据的域发生了变化,而任务域(标签)保持不变。在其他情况下,你可能希望使用来自相同域的数据(针对相同的基本分布绘制)来完成新任务。同样,输入域和任务域可以同时发生变化。在这些情况下,域适应 就会来拯救你。域适应是机器学习的一个子学科,它处理的 场景是,在不同(但相关)的目标分布的背景下,使用在源分布上训练的模型。通常,域适应使用一个或多个源域中的标记数据来解决目标域中的新任务。因此,源域和目标域之间的关联程度通常决定了适应的成功程度。
域适应有多种方法。在“浅层(不是深度)”域适应中,通常使用两种方法:重新加权源样本,在重新加权样本上进行训练,并尝试 学习共享空间来匹配 源和目标数据集的 分布。虽然这些技术也可以应用于深度学习,深度神经网络 学习的深度特征,通常会产生更多的可转移表示(一般来说,在较底层中具有高度可转移的特征,而在较高层中可转移性就急剧下降了,请参阅 Donahue 等人的论文 DeCAF: A Deep Convolutional Activation Featurefor Generic Visual Recognition(《DecAF:通用视觉识别的深度卷积激活特征》))。在 深度域适应 中,我们尝试使用深度神经网络的这一特性。
以下的总结主要是基于 Wang 等人的这篇综述论文:Deep Visual Domain Adaptation: A Survey(《深度视觉域适应研究综述》),以及 Wilson 等人的这篇评论文章:Unsupervised Deep Domain Adaptation(《无监督深度域适应》)。在这项工作中,作者区分不同类型的域适应,取决于任务的复杂性、可用的标记 / 未标记数据的数量以及输入特征空间的差异。它们特别定义了域适应问题,即任务空间相同,区别仅在与输入域的散度(divergence)。根据这个定义,域适应可以是同构(homogeneous)的(输入特征空间相同,但数据分布不同),也可以是异构(heterogeneous)的(特征空间及其维度可能不同)。
域适应也可以在一个步骤(一步域适应(one-step domain adaptation))中发生,或者通过多个步骤发生,遍历过程中的一个或多个域(多步域适应(multi-step domain adaptation))。在本文中,我们将只讨论一步域适应,因为这是最常见的域适应类型。
根据你从目标域获得的数据,域适应可以进一步分类为 监督(supervised)域适应(你确实标记了来自目标域的数据,尽管这些数据的数量,对于训练整个模型来说还是太小了)、半监督(semi-supervised)域适应(你既有已标记的数据,也有未标记的数据)、无监督(unsupervised)域适应(你没有来自目标域的任何标记数据)。
我们如何确定在源域中训练的模型是否可以适应我们的目标域呢?事实证明,这个问题并不容易回答,任务相关性仍然是个活跃的研究课题。如果两个任务都使用相同的特征进行决策,我们就可以将它们定义为相似的任务。另一种可能性是,如果两个任务的参数向量(即分类边界)很接近,则将它们定义为相似的(参见 Xue 等人的论文 Multi-Task Learning for Classification with Dirichlet Process Priors(《基于 Dirichlet 过程先验的分类多任务学习》))。另一方面,Ben-David 等人提出,如果两个任务的数据都可以通过一组变换 F 从固定的概率分布中生成,则这两个任务是 F 相关的(参见 Exploiting Task Relatedness for Multiple Task Learning(《利用任务相关性进行多任务学习》))。
尽管有这些理论上的考虑,但在实践中,可能有必要尝试在自己的数据集上进行域适应,看看是否可以通过使用源任务的模型为目标任务获得一些好处。通常,任务相关性可以通过简单的推理来确定,例如来自不同视角或不同光照条件的图像,或者在医学领域中来自不同设备的图像等。
一步域适应有三种基本技术:
基于散度的域适应
基于对抗的域适应,使用生成模型(生成对抗网络,GAN)或域混淆损失函数
基于重建的域适应,使用堆叠式自编码器(stacked autoencoders,SAE)或生成对抗网络。
基于散度的域适应,通过 最小化源和目标数据分布之间的散度准则来实现,从而实现 域不变的特征表示。如果我们找到这样一种特征表示,分类器将能够在这两个域上执行得同样好。当然,这是假设存在这样一种表示,而这种表示又假设任务以某种方式相关。
最常用的四种散度度量是:最大均值差异(Maximum Mean Discrepancy,MMD)、相关对齐(Correlation Alignment,CORAL)、对比域差异(Contrastive Domain Discrepancy,CCD)和 Wasserstein 度量。
MMD 是一种假设检验,将两个样本映射到一个再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS),然后通过比较特征的均值来检验这两个样本是否属于同一分布。如果均值不同,则分布也可能不同。这通常是通过使用核嵌入技巧并使用高斯核比较样本实现的。这里的直觉是,如果两个分布相同,来自每个分布的样本你之间的平均下你公司性应该等于来自两个分布的混合样本之间的平均相似性。在域适应中使用 MMD 的一个例子,可参见 Rozantsev 等人的论文 Beyond Sharing Weights for Deep Domain Adaptation(《除共享权重外的深度域适应》)。在这篇论文中,双流架构(two-stream architecture)使用的权重是不共享的,但通过使用分类、正规化和域差异(MMD)损失的组合导致相似的特征表示,如下图所示。
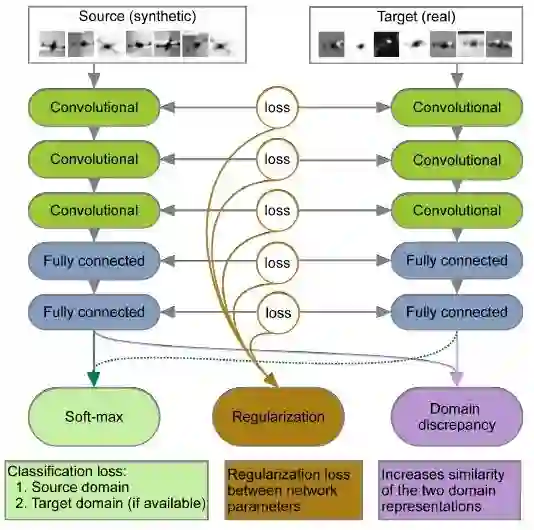
双流架构示意图
因此,设置可以是监督的、半监督的、甚至是无监督的(在目标域中没有分类损失函数)。
CORAL 类似于 MMD,但它试图调整源分布和目标分布的二阶统计(相关性),而不是使用线性变换的均值。在 Sun 等人撰写的论文 Deep CORAL: Correlation Alignment for DeepDomain Adaptation(《Deep CORAL:深度域适应的相关对齐》)中,通过使用源和目标协方差矩阵之间的 Frobenius 范数构造可微分的 CORAL 损失函数,在深度学习的环境中使用 CORAL。
CCD 也是基于 MMD 的,但也通过查看条件分布来利用标签分布。这就确保了联合域特征仍然保留 w.r.t 标签的预测性。最小化 CCD 可最大限度地减少类内差异,同时使类间差异最大化。这需要源域标签和目标域标签。为摆脱这种约束,Kang 等人撰写的论文 Contrastive Adaptation Network for Unsupervised Domain Adaptation(无监督域适应的对比适应网络)提出,在一个联合优化目标标签和特征表示的迭代过程中,使用聚类来估计损失的目标标签。在此基础上,通过聚类找到目标标签,从而使 CCD 最小化以适应这些特征。
最后,源域和目标域中的特征和标签分布可以通过考虑最优传输问题及其对应的距离(即 Wasserstein 距离)来对齐。这是在 Damodaran 等人的论文 DeepJDOT: Deep Joint Distribution OptimalTransport for Unsupervised Domain Adaptation (《DeepJDOT:用于无监督域适应的深度联合分布优化传输》)中提出的。作者提出通过优化传输来使联合深度特征表示与标签之间的差异最小化。
这种技术是尝试通过对抗训练来实现域适应。
一种方法是使用 生成对抗网络 来生成与源域相关的合成目标数据(例如通过保留标签)。然后将这些合成数据用来训练目标模型。
CoGAN 模型 尝试通过对源分布和目标分布使用两个生成器 / 判别器对来实现这一点。对生成器和判别器的权重进行共享,来学习域不变的特征空间。通过这种方式,可以生成标记的目标哦数据,这些数据可以进一步用于诸如分类等任务中。
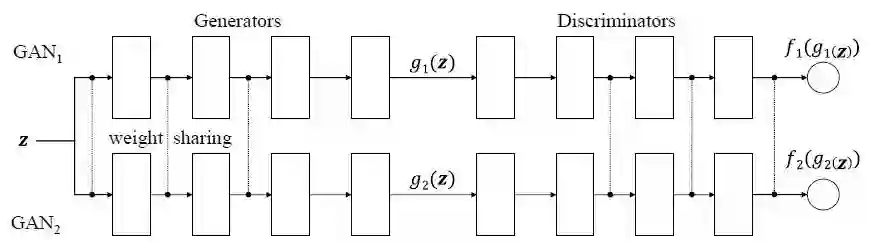
CoGAN 架构示意图
在另一个装置中,在 Yoo 等人的论文 Pixel-Level Domain Transfer(《像素级域迁移》)中,作者提出,尝试通过使用两个判别器来学习 源 / 目标转换器网络:一个用于确保目标数据是真实的,另一个用于保持源域和目标域之间的相关性。因此,生成器以源数据为条件。这种方法只需要目标域中未标记的数据。
除了当前任务的分类损失函数之外,如果使用所谓的域混淆损失函数,我们还可以完全摆脱生成器,一次性完成域适应。域混淆损失类似于生成对抗网络中的判别器,因为它试图匹配源域和目标域的分布,以“混淆”高级分类层。也许这种网络最著名的例子是 Ganin 等人提出的 域对抗神经网络(Domain-Adversarial Neural Network,DANN)。该网络由两个损失函数组成,即分类损失函数和域混淆损失函数。它包含一个 梯度反转层(gradient reversal layer)来匹配特征分布。通过最小化源样本的分类损失函数和所有样本的域混淆损失函数(同时最大化特征提取的域混淆损失函数),这就确保了对分类器而言,这些样本是无法区分的。
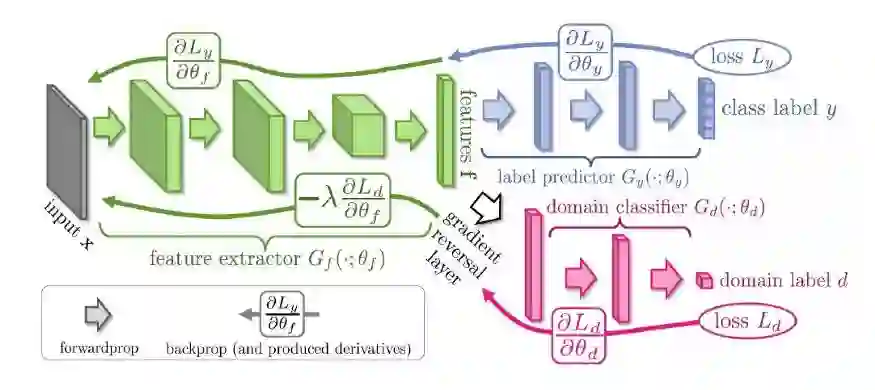
域对抗神经网络架构示意图
这种方法使用一个 辅助重建任务 为每个月创建共享表示。例如,深度重建分类网络( Deep Reconstruction Classification Network,DRCN)试图同时解决这两个任务:
(i) 源数据的分类
(ii) 未标记目标数据的重建
这确保了网络不仅能够学习正确识别目标数据,而且还能够保存目标数据的信息。在这篇论文 Deep Reconstruction-Classification Networksfor Unsupervised Domain Adaptation(《用于无监督域适应的深度重建分类网络》)中,作者还提到重建管道学习将源图像转换为类似于目标数据集的图像,这表明两者都学习了一个共同的表示方式。
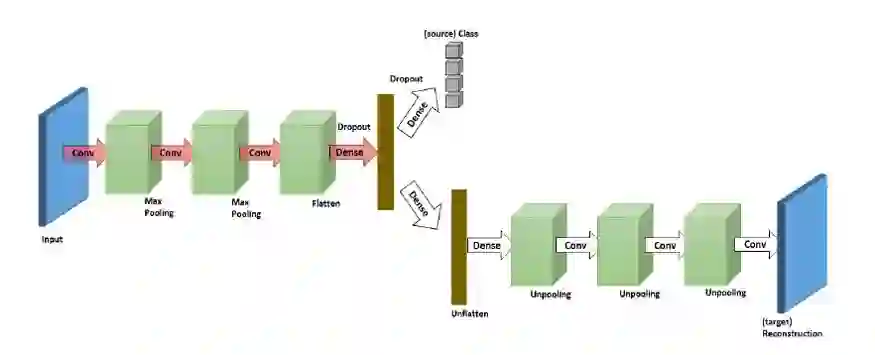
DRCN 架构示意图
另一种可能性是使用所谓的 循环 GAN。循环 GAN 的灵感来自于机器翻译中的双重学习概念。这个概念是同时训练两个相反的语言翻译器(A-B,B-A)。循环中的反馈信号由相应的语言模型和共同的 BLEU 分数组成。使用 im2im 框架也可以对图像进行同样的处理。在这篇论文 Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks(《使用循环一致对抗网络的不成对图像到图像的转换》)中,作者提出了在不使用任何成对图像样本的情况下,如何学习从一个图像域到另一个图像域的映射。这是通过同时训练分别在两个域中生成图像的两个 GAN 来实现的。为了确保一致性,引入了 循环一致性损失函数(cycle consistency loss)。这确保了从一个域转换到另一个域,然后再转换回来,得到的图像域输入的图像大致相同。因此,两个成对的网络的完全损失函数是两个判别器的 GAN 损失函数和循环一致性损失函数的总和。
最后,通过将它们的输入调整为来自另一个域的图像上,生成对抗网络还可以用于编码器 - 解码器设置中。在 Isola 等人的论文 Image-to-Image Translation with Conditional Adversarial Networks(《基于条件对抗网络的图像到图像转换》)中,作者提出,条件生成对抗网络(conditional GAN)是通过调节输入上的判别器和生成器的输出,来将图像从一个域转换到另一个域。这可以通过使用简单的编码器 - 解码器架构来实现,也可以通过使用带有跳跃连接(skip-connections)的 U-Net 架构来实现。

条件生成对抗网络的几个结果
深度域适应允许我们将源任务上的特定深度神经网络锁学的只是迁移到新的相关目标任务上。这种方法已经成功地应用于图像分类、风格转换等任务。从某种意义上说,就特定的计算机视觉任务所需的训练数据量而言,深度域适应使我们更接近人类水平的表现。因此,我认为这一领域的进展对整个计算机视觉领域至关重要,我希望它最终能引导我们在视觉任务中能够进行有效而简单的知识重用。
作者介绍:
Branislav Holländer,研究方向为计算机视觉、机器学习和通用图形卡处理器。
原文链接:
https://towardsdatascience.com/deep-domain-adaptation-in-computer-vision-8da398d3167f

你也「在看」吗?👇




