ICML 2022 | 基于解耦梯度优化的可迁移模仿学习方法

©作者 | 刘明桓
单位 | 上海交通大学
研究方向 | 强化学习,模仿学习

论文标题:
Plan Your Target And Learn Your Skills: Transferable State-Only Imitation Learning via Decoupled Policy Optimization
https://arxiv.org/abs/2203.02214


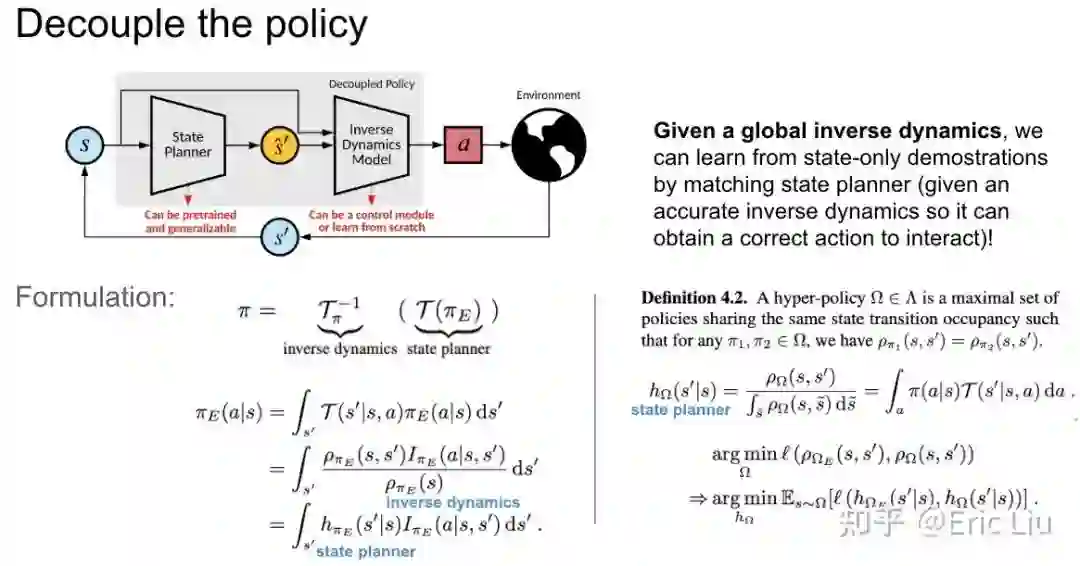
这时候如果我们可以训练得到这两个模块,他们拼在一起可以得到一个完整的 policy,而分开之后上层的 plan 模块其实可以直接用于一个新的 action space 不同的任务(只需要学一个底层的 IDM)。如果底层的 IDM 是一个给定的 ground truth,这样的 policy 也可以直接工作;如若不然,则需要通过学习得到。

监督学习
一种最直接的监督学习方式就是分开学习两个模块。但是这样做的话,上层模块只能在专家数据上学习,下层则可以在新收集的经验上学习。

一个很明显的问题,和 bc 一样,由于只在部分数据上学习,compounding error 会很严重。而且 planner 输出的 s' 也不一定能马上到,还要受到 inverse dynamics 的影响。下面我们将推导如何通过策略梯度来学习。

解耦策略梯度
首先推一个直接的形式。如果把这两部分看作是无约束无意义的 function 的话,可以直接梯度回传。这也是第一版投稿的时候的做法,但是当时这么做,始终无法得到很准的 state plan,也就是 plan 的 state 始终无法到达。
在重新推导之后,我们发现,我们想要求 state planner 是准的,必须是要假定有一个准的 IDM 啊!否则这样的学习是没有意义的,因为你学到的 s' 在和环境交互的时候也根本到不了。因此在学习的时候,底层的 IDM 应该是(local)准的,至少在学习的这部分数据上。这样的梯度才是朝向一个有意义的 plan state。


这个时候的解释就很明显了,我们希望 IDM 来告诉我们,如果要输出一个特定的 action,应该朝哪个方向去改 plan 的 state。大家可以发现我们的 formulation 虽然出发自 imitation,其实并不局限于 imitation,也适用于 RL。对于 imitation learning,只是我们要额外训练一个 Discriminator(像 GAIfO 一样)来获取 reward 信号。
但是如果这么做,还是有问题。因为我们的 IDM 一般是 NN 来拟合的,而 NN 的拟合无法做到一一映射,也就是 NN 在没见过的数据上是有不可知性的,意思是我们本来在环境里得到的训练数据是,两个相邻的 s,s' 预测一个 action a,这个是符合 MDP 的。但是如果训练了一个 NN,给一个 s 和一个很离谱的 s‘,这个 NN 也是可以输出这个 a!这个问题导致了,通过 IDM 回去的信号,不一定是一个正确的 correction,也就是 state的plan 可能是一个不相邻的 next state,但 IDM 仍可以输出一个合法的 action(因为 action space 就那么多,总会输出一个 action)来交互。但这不是我们想要的。

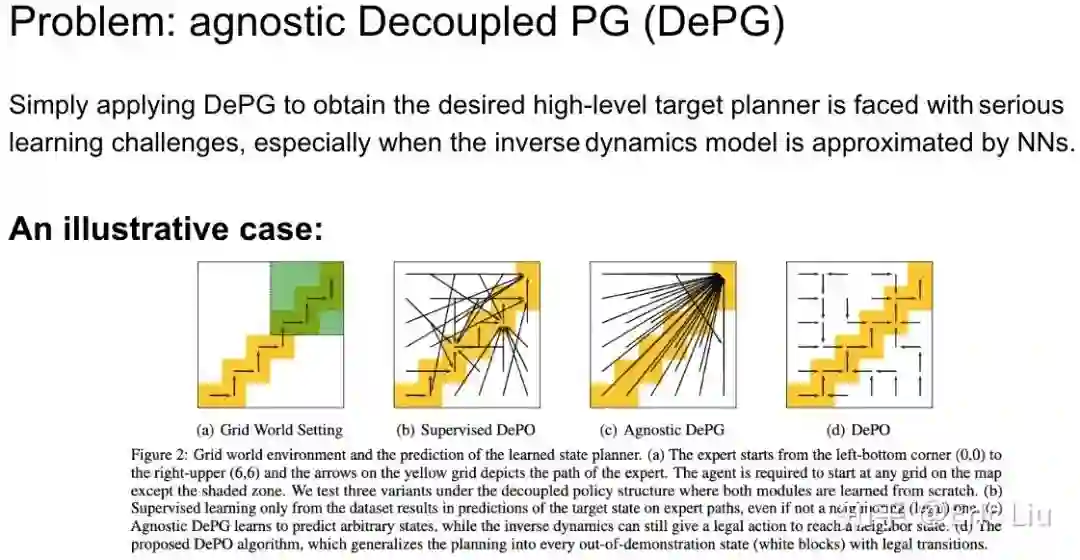
这个图里,这个问题更明显。在一个 grid world,专家是在黄色 grid 上的箭头,从左下到右上。智能体可以从除了阴影以外的任意区域出发。如果我们只做监督学习(b),可以发现 planner 的预测输出都是专家数据的 state,不会输出合法的相邻 plan。而只用上面的 DePG,也会输出不合法的 planing。而我们后面修正之后的方法,则是可以输出泛化并且合法的 plan。

修正策略梯度
怎么办呢?我们如果加一个额外的约束让前面的 planner 是输出合法的 next state 是不是就可以了?最直观的就是加一个 MLE,但是在我们的推导中我们推导了一个所谓的 CDePG 来更新,其实 PG 就是 weighted 的 MLE,用这样一个目标来更新也是更符合优化目标,这点在文中有相关推导和证明。但是在实验中,我们测试的 MLE 和 CDePG 的效果其实差不多。
但是如果只优化 CDePG,由于 s,a,s' 都是策略采集的,单纯这么做反而限制了 action 的探索。注意原本的 PG 的探索,通过 Q 值的高点不同,输出不同的 action 和环境交互再修正 Q 值。但是在我们这种方式下,action 不是直接得到的,而是先得到一个 plan,再由一个底层的 IDM 得到 action。因此,如果这里的 plan 都是见过的,底层的 action 也不会有什么变化。但是 DePG 没有对 s' 的约束,因此天然有着 explore 的能力(通过输出一个不合法的 s' 来得到一个想要的 a)。因此在实际中,我们是同时优化这两个目标(加上监督学习)。
怎么办呢?我们如果加一个额外的约束让前面的 planner 是输出合法的 next state 是不是就可以了?最直观的就是加一个 MLE,但是在我们的推导中我们推导了一个所谓的 CDePG 来更新,其实 PG 就是 weighted 的 MLE,用这样一个目标来更新也是更符合优化目标,这点在文中有相关推导和证明。但是在实验中,我们测试的 MLE 和 CDePG 的效果其实差不多。
但是如果只优化 CDePG,由于 s,a,s' 都是策略采集的,单纯这么做反而限制了 action 的探索。注意原本的 PG 的探索,通过 Q 值的高点不同,输出不同的 action 和环境交互再修正 Q 值。但是在我们这种方式下,action 不是直接得到的,而是先得到一个 plan,再由一个底层的 IDM 得到 action。因此,如果这里的 plan 都是见过的,底层的 action 也不会有什么变化。但是 DePG 没有对 s' 的约束,因此天然有着 explore 的能力(通过输出一个不合法的 s' 来得到一个想要的 a)。因此在实际中,我们是同时优化这两个目标(加上监督学习)。


算法
所以在算法这里,是先更新 IDM 到收敛,然后更新 D 获取 reward(如果是 imitation),最后用上面的 loss 更新 planner。


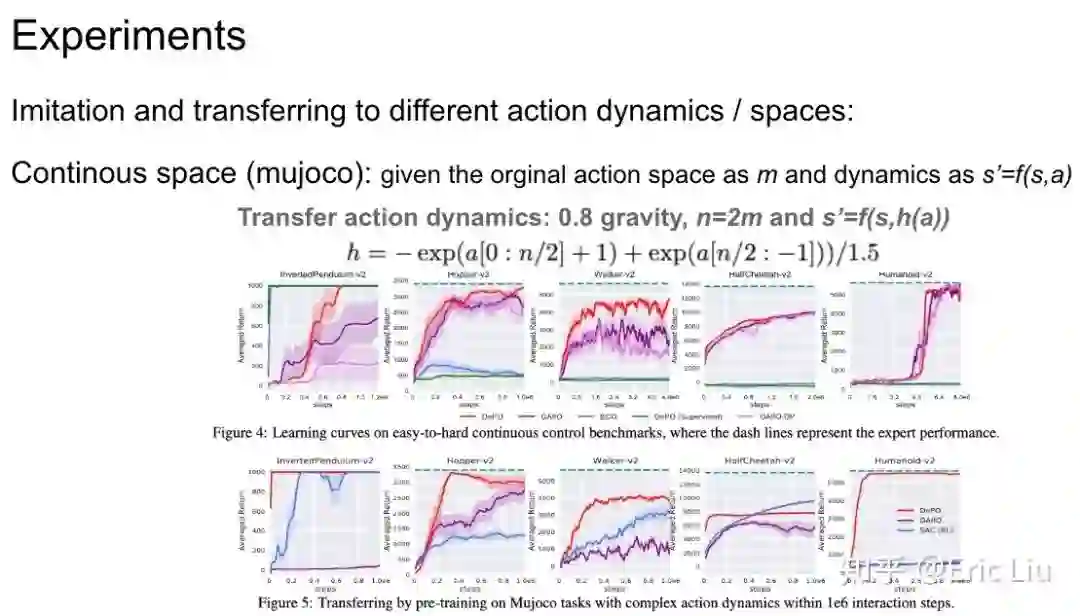
我们想做的实验主要是为了验证这样一种结构的优势。因此我们希望它可以做迁移。具体来说,在一个新的 action space 上,我们不需要重新训练 planner,而只需要训练底层的 IDM 即可。在实验中这体现出了巨大的效率优势。
首先是前面的 grid world 的离散实验。这个环境的 action space 是 k*4,也就是上下左右分别有 k 个动作可以完成。我们从 k=1 的环境训练,然后接着迁移到 k=4,发现收敛效率很高。
我们又接着做了 mujoco 上的 5 个环境的实验,结果也是非常大的迁移优势。迁移的时候,保留上层而只学习底层的 IDM,甚至比 online 的 SAC 效率都要高出一截!
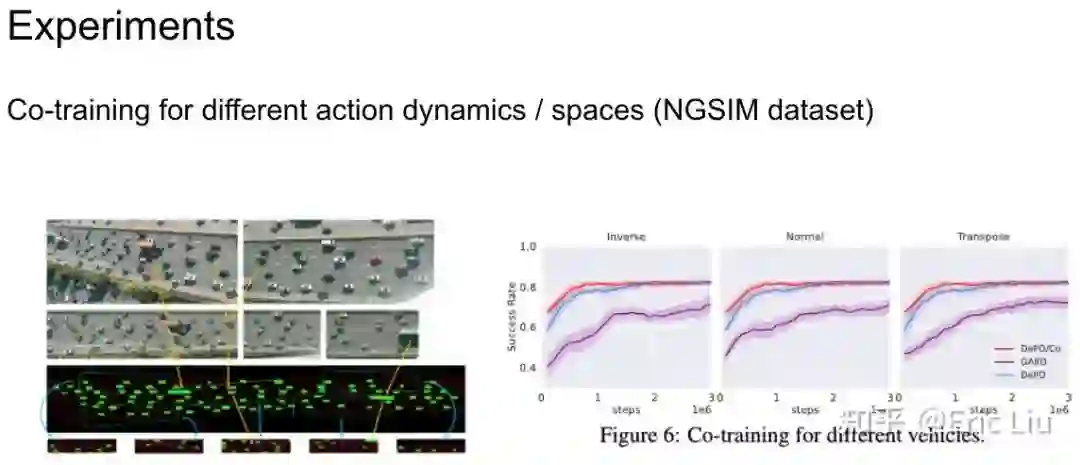
由于这个 planner 可以 share,我们又尝试了在不同 action space 下的 agent 的 co-training 实验,也就是三个人一起 sample 样本,共同训练一个 planner:
前面也提到了,我们的方法其实是 general 的,因此也可以用到 RL 的场景下的训练和迁移!
我们在可视化后发现这样学到的 state planner 是非常准的,而且可以 plan 一个很长的步数都非常准确。可以翻墙的同学可以查看 youtube 上的视频:
https://www.youtube.com/watch?v=WahVjjvcYYM
不能翻墙的同学可以看下面的图。


此外通过 pred-real 的差距也可以看出来,随着学习进行,预测的 state 和实际到达的 state 的差距越来越小:
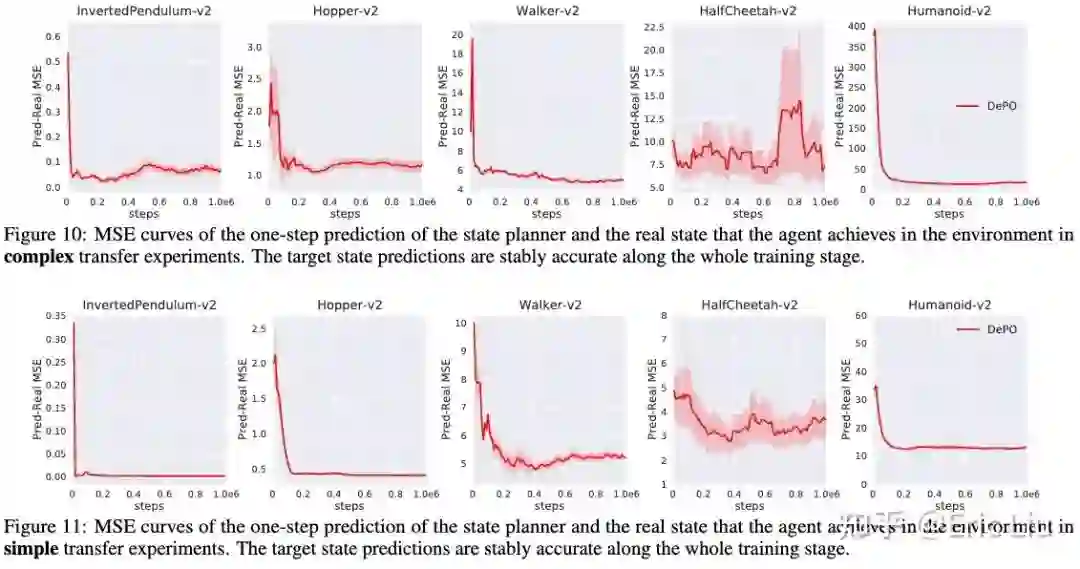
这个工作前后持续了一年,而且方法论在中间推翻重写过一次,最后得到的效果还是不错的。可惜还是有点遗憾文章其实还可以写的再清晰一些。我们觉得这样一种解耦 policy 的结构是非常有用并且可以用于很多迁移的任务当中,因为它把 state 和 action 解耦了开来,不再绑定。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



