干货 | NIPS 2017线上分享:利用价值网络改进神经机器翻译
编者按:机器学习领域顶会NIPS 2017将于12月4号至9号在美国加州长滩举办。微软亚洲研究院的多篇论文入选了本次大会。上周,中国科学技术大学-微软联合培养博士生夏应策应邀参加机器之心优质论文线上分享活动,就其中一篇有关神经机器翻译的入选论文进行了详细讲解。一起来看看吧!本文转载自公众号“机器之心”。
线上分享视频回顾

(以下为夏应策分享的文字整理)
神经机器翻译(Neural Machine Translation,NMT)基于深度神经网络,为机器翻译提供了端到端的解决方案,在研究社区中受到了越来越多的关注,且近几年已被逐渐应用到了产业中。NMT 使用基于 RNN 的编码器-解码器框架对整个翻译过程建模。在训练过程中,它会最大化目标语句对给定源语句的似然度。在测试的时候,给定一个源语句x,它会寻找目标语言中的一个语句y*,以最大化条件概率P(y|x)。由于目标语句的可能数目是指数量级的,找到最优的 y*是 NP-hard 的。因此通常会使用束搜索(beam search)以找到合理的 y。
束搜索是一种启发式搜索算法,会以从左向右的形式保留得分最高的部分序列扩展。特别是,它保存了一群候选的部分序列。在每个时间步上,该算法将都会通过添加新词的方法扩展每一个候选部分语句,然后保留由 NMT 模型评分最高的新候选语句。当达到最大解码深度或者所有的语句都完全生成的时候(即所有的语句都包含 EOS 符号后缀的时候),算法就会终止。
虽然 NMT 结合束搜索是很成功的,但也存在几个明显的问题,已经被研究过的包括曝光偏差(exposure bias)、损失评估失配(loss-evaluation mismatch)和标签偏差(label bias)。然而我们观察到,其中仍然有一个很重要的问题被广泛忽视,即短视偏差(myopic bias)。束搜索倾向于更关注短期奖励。例如,在第 t 次迭代中,对于候选语句 y_1,...,y_t-1(记为 y_<t),和两个词 w 和 w',当把 w 添加到 y_<t 的时候记为 y_<t+w。如果
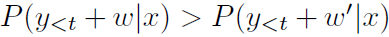
则新的候选语句 y_<t+w 相比 y_<t+w』 更可能被保留,即使 w'是在第 t 次迭代中的真实翻译,或在未来的解码中能获得更高的分数。这种源于短视的搜索错误有时候在模型很好的情况下也会提供糟糕的翻译。
为了解决短视偏差,对每一个词 w 和每一个候选语句 y_<t,我们设计了一个预测模型以在把 w 添加到 y_<t 的时候,评估长期奖励。这个过程会跟随当前使用的 NMT 模型,直到解码完成。然后我们可以在每个解码步中应用这个模型输出的预测分数帮助寻找更好的 w,以提升长句翻译性能。这种预测长期奖励的模型,恰好和强化学习中的价值函数的概念相同。
在本研究中我们开发了一个基于神经网络的预测模型,即为 NMT 设计的价值网络。该价值网络将源语句与任何部分序列作为输入,并输出预测值以估计 NMT 模型生成这一部分序列的期望总回报(例如 BLEU 分值)。在所有解码的步骤中,我们不仅基于该部分序列的条件概率选择最优的候选译文,同时还基于价值网络估计翻译效果的长期回报。
该项工作的主要贡献如下。首先我们开发了一个考虑长期回报的解码方案,它会为机器翻译逐一生成译文,这在 NMT 中是比较新的方案。在每个步骤中,新的解码方案不仅考虑源语句的条件概率,同时还依赖于未来的预测回报。我们相信考虑这两个部分将导致更好的翻译效果。
其次,我们设计了一种新颖的价值网络。在 NMT 编码器-解码器层的顶部,我们为价值网络开发了另外两个模块,即一个语义匹配模块和一个上下文覆盖(context-coverage)模块。语义匹配模块旨在估计源语句与目标语句之间的相似度,该模块直接有助于翻译质量的提升。不过我们经常观察到,随着注意力机制使用更多的上下文信息,模型能生成更好的翻译 [14, 15]。因此我们构建了一个上下文覆盖模块来度量编码器-解码器层中的上下文覆盖范围。通过这两个模块的输出,模型最终的预测将由全连接层完成。
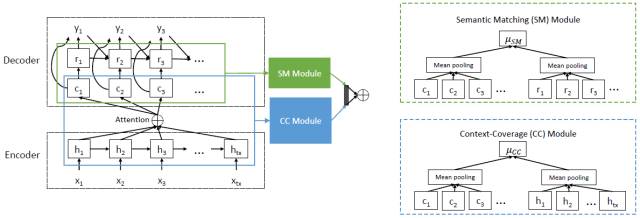
图 1:价值网络的架构

算法 1:价值网络训练

转自:微软研究院AI头条
完整内容请点击“阅读原文”


