强化学习与文本生成


说到『文本』,便离不开『自然语言』,因为文本是语言的书面化表达。目前学术界跟语言相关的研究,可以简单分成两个大方向:NLU (自然语言理解) 和 NLG (文本生成)。 这其实很符合我们人类语言的使用场景——先去理解别人说的、写的,再组织自己的语言。
从技术层面看,NLU就是去分析句子的成分、给句子中的词性等做标注,让机器更好地『理解』语言;而NLG 则是对输入的文本信息,让机器生成一段新的文本。从广义角度看,机器翻译、自动摘要、机器阅读理解、自动聊天等问题,都可以看成文本生成问题,且都可以套用经典的 encoder-decoder (编解码) 框架。
从语言的角度看,文本是有内在顺序的,小到字级别、大到篇章级别,所以文本生成,实际上也是一种『序列生成』。提到序列,我们自然而然就会想起当今很时髦的『强化学习』,其已在机器人控制、自动驾驶、推荐系统等涉及序列决策的领域广泛应用。不过相比而言,强化学习在NLG 上的应用并没有那么自然,因为强化学习中的很多关键因素,如『状态』、『动作』、『反馈』等,在 NLG 中很难显式地建模。索性我们仍然可以通过一些巧妙设计,来引入强化学习。
本文将简单探究五篇论文,讲解当前强化学习在文本生成中的应用,结合本人在组内分享所做的课件,试图归纳出一些共通的特征。本文假设读者已经具备一定的基础理论知识,如 seq2seq 模型、极大似然估计(Maximum Likelihood Estimation)等。
本节将带领读者一起,简单剖析五种比较新的算法模型,来源于五篇论文,涉及机器翻译、自动摘要、机器阅读理解,主要聚焦在这些模型是如何引入强化学习的。
论文: Minimum Risk Training for Neural Machine Translation(ACL2016)
该论文虽主打机器翻译算法,但框架依然是 seq2seq,所以有普遍意义,引用量很高。作者旨在解决传统损失函数和评价指标的不一致问题,恰好跟强化学习的reward思想不谋而合,所以我们将从强化学习的视角,重点讲解这个算法,后续模型都或多或少借鉴了这一做法。
众所周知,seq2seq 的decoder 会在每个时间步,根据输入序列和已经解码出来的文本,预测出该时间步最有可能出来的单词,看成一个多分类问题,从而基于极大似然估计推导出损失函数如下:
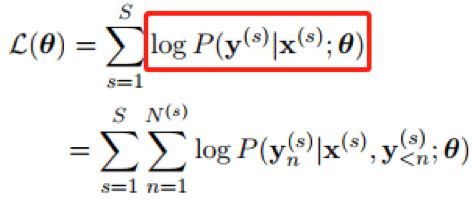
这里的 S 是训练样本总数,红框里就是由传统的极大似然估计得到的交叉熵损失函数,每一步预测出的单词yn 都会跟标准答案计算出损失值,然后在所有时间步上求和。
>>>痛点
然而跟多分类问题的不同之处在于,通常我们评价一个文本序列的优劣,并不是简单的看某一步预测出的词是否正确,而是将序列作为一个整体去考量,比如『微信是一个生活方式』和 『人们的一个生活方式是微信』所表达的意思基本一致,但这两句话进行逐字或逐词比较的话,并无半点相同。基于此,我们在评价文本序列时,通常会采用BLEU、ROUGE 等指标,去衡量他们ngram 的一致性。
所以,如果我们依然套用传统多分类问题的损失函数去训练模型,便会遇到一个尴尬的问题:我们的评价标准和训练目标并不一致。更细节一些,我们训练时,只考虑到了每个字位置上的正确信息,并没有考虑整体指标,所以如果我们在训练过程的某一步,解码出了『人们的一个生活方式是微信』,而标准答案是『微信是一个生活方式』,这个预测结果会被认为是错的,会迫使模型只学出一种正确答案。
>>>解决之道
基于此考虑,MRT 在损失函数中引入了一个跟评价指标相关的项,与传统损失函数的对比如下

这里新加入的项就是图中黄框所示,可以是BLEU、ROUGE、F1 值等。我们可以看到,传统的loss依然保留了(注意,这里的传统loss是概率分布,而不是通过概率分布得到的交叉熵),但是解码阶段,我们不再只考虑『最大可能序列』,而是把所有可能的序列都考虑进来,然后每个序列都会有一个额外的、跟评价指标相关的损失项。所以,即便传统loss 不合理,依然可以通过额外的项来『挽救』,更严谨的说法我们下面会探讨。
我们不妨从强化学习的角度来看待这个改进:我们在训练过程中某个时刻预测出来的某文本序列,可以看成是一种『状态』,而『状态空间』就是该训练时刻、所有可能的文本序列集合,『策略』就是文本序列对应的概率分布,也就是上式子中的传统loss项,所采取的『动作』就是从这个集合中挑选句子,而『反馈』就是这个句子对应的改造后的损失函数值。
解释完这个改进的出发点,我们不妨从数学角度严谨思考一下,这个改进为何有效?
这里我提供一个角度:排序不等式。高中数学讲过,顺序不等式>=乱序不等式>=倒序不等式,如下
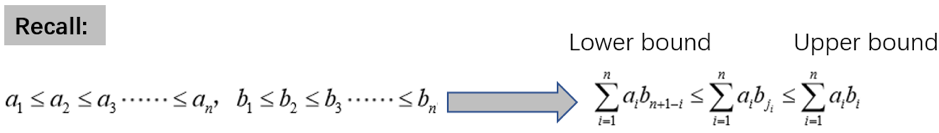
我们再回顾下改进后的损失函数

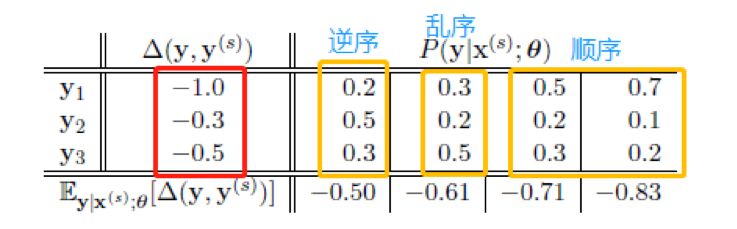
传统loss项和新加的项,正好可以看成 a 和 b 这俩数列的某两项ai 和 bj,假设我们这里的 Y 是所有序列 y 的集合,则 新加项的取值是跟模型无关的评价指标值,是固定的,而传统 loss 项的取值是变化的。所以为了使整个目标项的取值最大,就需要传统 loss 项,也就是 P(y|x) 的取值,跟评价指标一致。文中也给出了一个表格,佐证了这个观点,我从数列角度做了标注,如下
>>>技巧
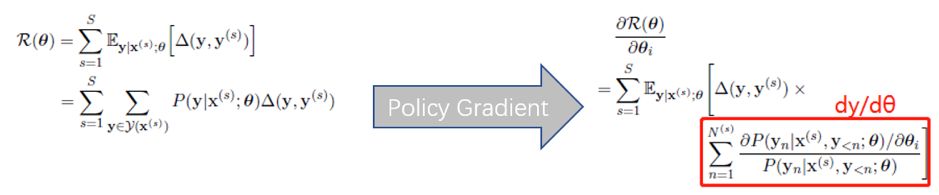
这个改进很有效,但我们依然没法忽略一个事实:所有文本序列的集合(即『状态空间』)实在太庞大! 我们不妨假设总共有 N 个词,要预测 T 步,则粗略估计 有 N^T 个可能的序列,所以在进行梯度下降时,如果我们还用传统方法,计算量将不可估量,因为涉及到对每个序列的求导,如下图红框所示(摘自本人课件)
为此,我们需要通过采样的方法,来抽取训练过程中每一次所产生的序列集合。论文提供的方法,是在 decoder 的每个时间步,按照词的概率分布,来抽取单词(而不是像传统做法,直接取概率最大的),一直抽到结束,形成一个完整序列,然后重复 k 次,得到 k 个序列,组成一个子集。本质上是修改了 beam search 的过程,如下

重新进行梯度下降,注意,此时的序列是原始序列集合的子集,所以对序列的原始概率要重新进行归一化,得到新的概率分布(摘自本人课件)
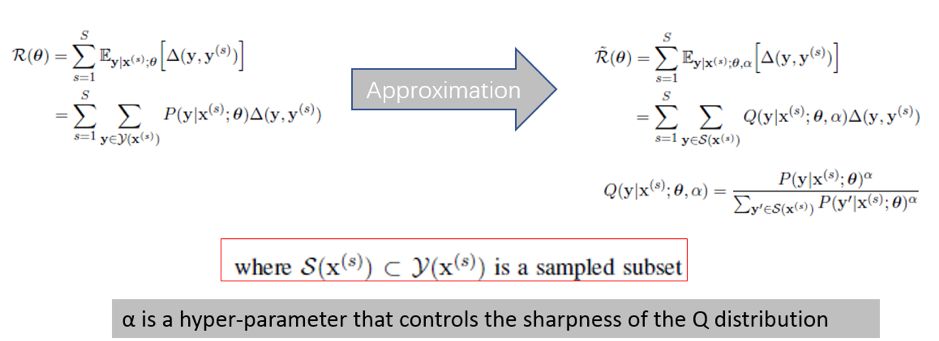
我们仔细看下这个Q 函数,这里有个小trick,引入了一个超参数α,来新的概率分布(即『策略』)的 sharpness,我个人猜测应该是为了将样本区分得更开,加快收敛。
论文:Deep_abs: A DEEPREINFORCED MODEL FOR ABSTRACTIVESUMMARIZATION (ICLR 2018)
理解了上一个模型,这篇论文里的精髓我们便很快能get到。虽然是不同于机器翻译的自动摘要问题,但依然是 seq2seq 框架,依然是逐字decoding。 首先看下整个系统(摘自论文)
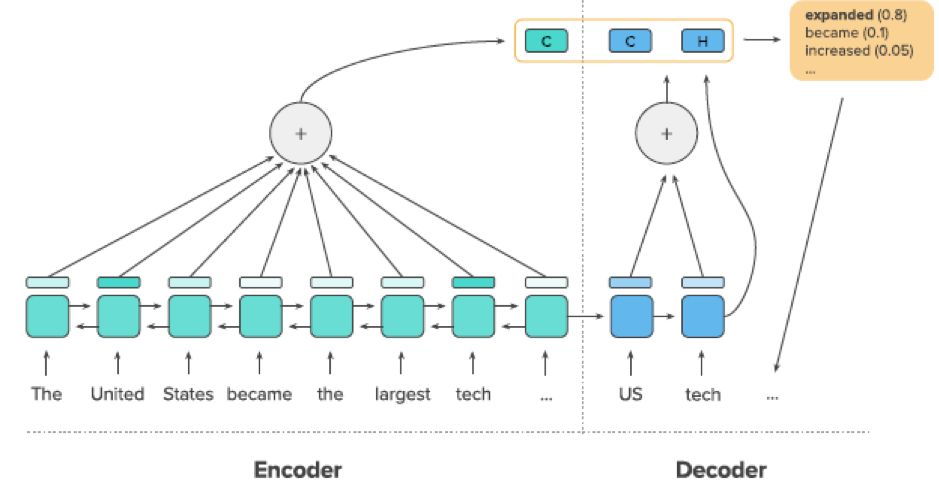
套用的是目前生成式摘要领域的state-of-art 方法: copynet——即在解码过程中,除了考虑待预测词表上的概率分布,还额外考虑输入序列的注意力权重形成的概率分布,使得预测的时候能从输入中『copy』候选词,更细节的部分就不展开了。
该论文的精髓,跟 MRT 类似,即通过强化学习的方法改造损失函数,加入跟评价指标相关的项,如下所示(摘自本人课件)
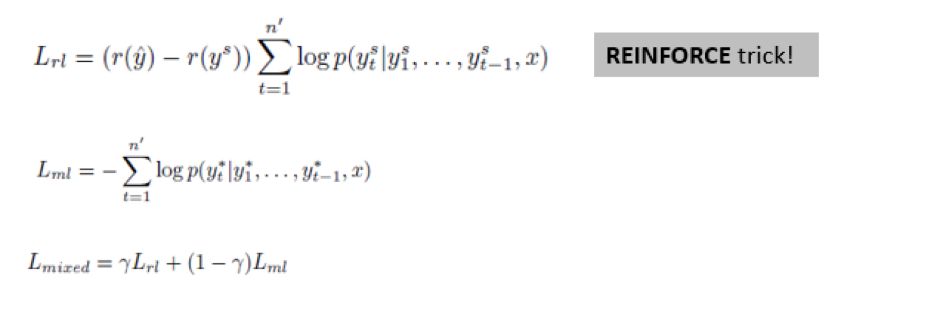
这里的 Lrl 便是跟强化学习相关的项, Lrl 左边的差值可以理解为是跟评价指标相关的项, Lrl 右边的求和项就是对应序列的概率,而 Lml 就是交叉熵,简直跟 MRT 一模一样!!唯一的区别,是 MRT 只考虑了 Lrl,而 Deep_abs 把 Lml 也考虑进来,变成多目标优化问题。
论文:Refresh: Ranking Sentences for Extractive Summarizationwith Reinforcement Learning (NACCL2018)
这篇论文也是自动摘要,跟前两篇论文生成『字词』序列变成一段文本不同,这篇论文是做抽取式摘要,所以是抽取『句子』序列变成一段文本。
整个框架如下(摘自论文)
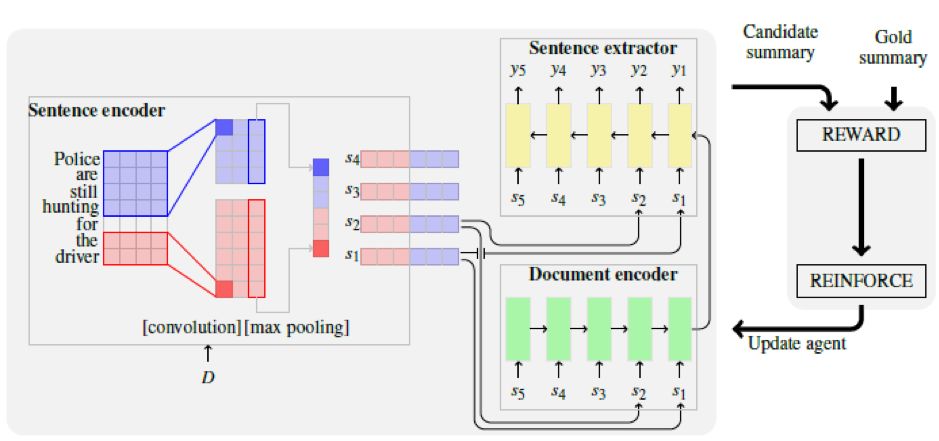
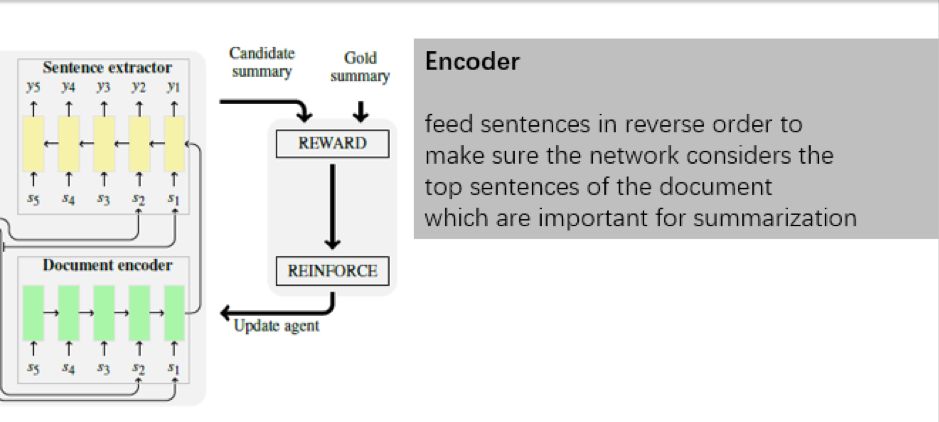
首先我们看编码过程,注意这里预先用 CNN 对每个句子进行编码,将其表示成embedding,再逐步输入 rnn 形式的 encoder 。有个小的注意点,即倒序输入句子,第一句话在最后一步输入,论文的解释是使得encoder 出来的向量更偏向第一句话,因为做摘要嘛,一般前几句话最重要,如下所示(摘自本人课件)
解码过程则比较自然,从大的框架看,输入是 CNN 编码后的所有句子,输出这句话是摘要的概率。具体到实现上,又是 rnn 形式,初始输入是encoder出来的向量,第 i步的输入对应第 i 个句子的 embedding,如下所示(摘自本人课件)
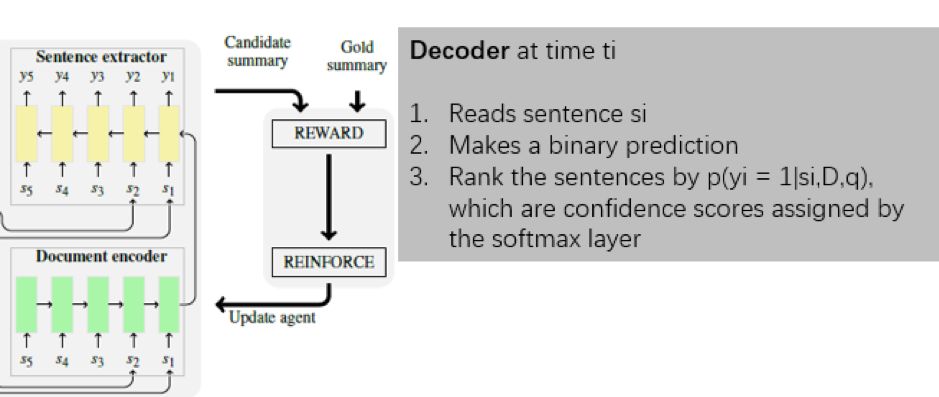
训练的时候,标签是通过人工写的摘要去给每个句子打分,划分一个阈值,形成0-1标签,从而变成一个二分类问题;预测的时候,将这几个句子的概率排个序,筛选 top k个句子,再按句子再输入文本中的顺序排列,然后作为抽取式摘要。
既然是二分类问题,我们便可以套用极大似然估计,如下所示
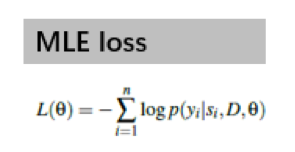
>>>痛点和解决之道
注意到,跟 MRT 面临的相似问题又出现了——训练的时候,我们的 0-1 标签并不是直接产生的,而是用人工写的摘要对句子打分然后离散化得到的,而这个打分,其实也可以作为摘要好坏的评价指标。所以『训练目标』和『评价指标』之间的偏差就产生了,索性,我们已经有了强化学习武器了。
在强化学习的指导下,我们将损失函数改造如下

这里的 r 做了一些设计,用的是rouge 系列指标的平均值,论文的解释是这样能使得生成的文本兼顾信息量和流畅度。
注意一下,本节开头提到,本论文是将句子看成序列的子单元,而不是将词看成序列的子单元,所以从强化学习的角度看,这里的『状态集合』是所有可能的句子抽取情形,从而对应的『策略』就是所有抽取情形下的概率分布。
>>>技巧
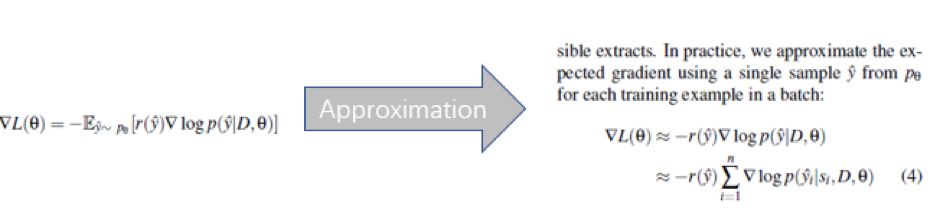
跟 MRT 一样,这里同样会面临状态空间太大的问题,比如当输入文本有 N 句话时,对应的抽取可能性有 2^N 种,虽然不及前面提到的N^T 来的大,但也是个不小的量级,同样需要抽样,只不过跟 MRT 里的抽样略有不同,这里是根据每种抽样的概率排序,然后抽取K 个最大可能的情形,作为新的状态子空间。抽样完毕后,便可以改造梯度下降(摘自本人课件)
论文:R3: Reinforced Ranker-Reader for Open-Domain Question Answering (AAAI 2017)
这篇论文在本人之前的阅读理解综述文章里有提到,但当时并未过多关注强化学习部分,这里我们重新审视一下这个算法,关于机器阅读理解的基础理论不再赘述。
整个算法的框架如下:
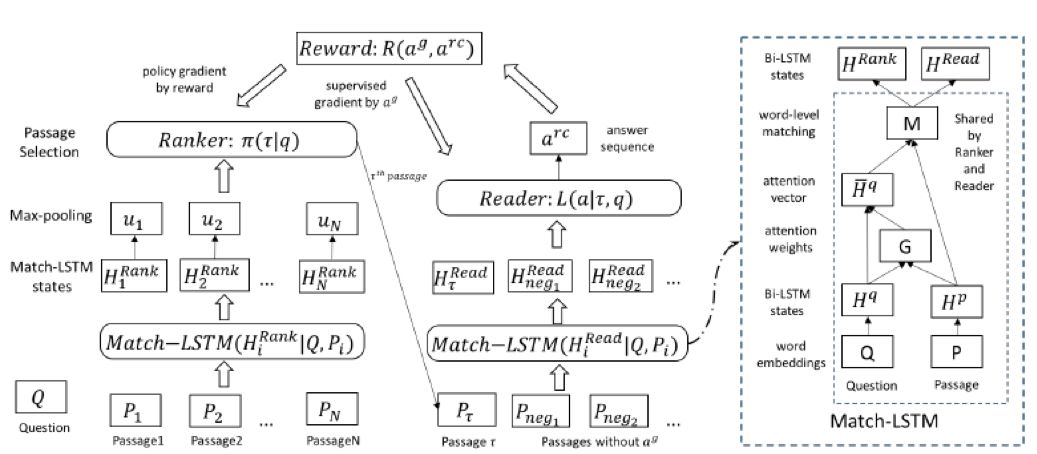
整个算法分成两部分,篇章选取和答案生成。encoder、decoder、match-lstm 的细节不再赘述,我们重点看下这里涉及到的『策略』、『动作』和『反馈』,如下(摘自本人课件)
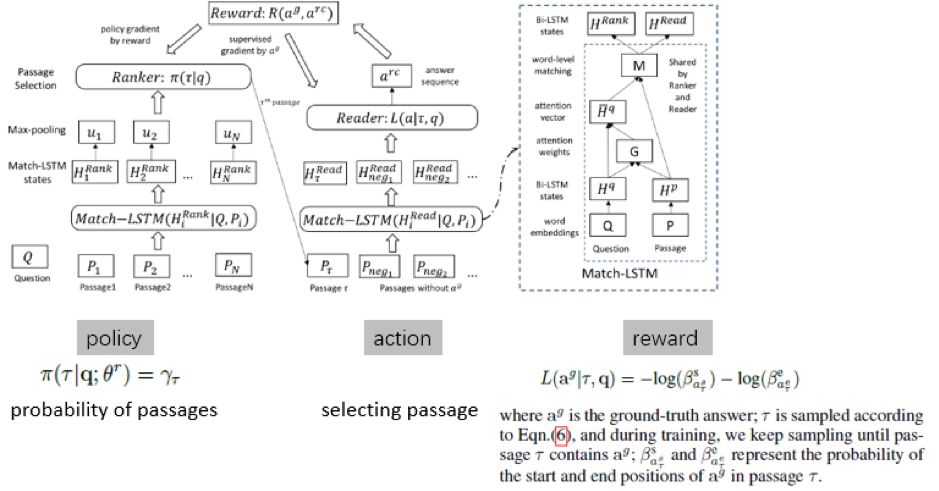
『策略』就是 Ranker 出来的篇章的概率分布,采取的动作则是挑选文章,反馈是预测出的答案片段起始位置的打分
>>>痛点和解决之道
这里的痛点是:挑选文章这个动作本身是无法求导的,所以必须通过构造一个可导的反馈函数,来间接实现挑选动作。
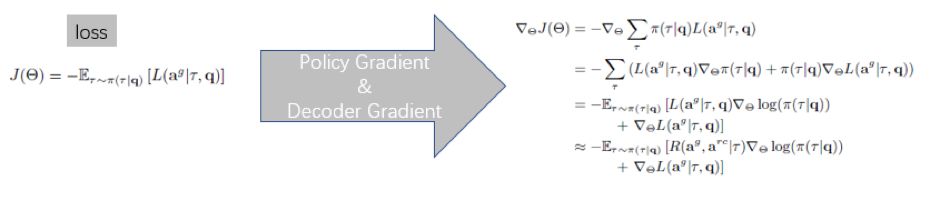
所以跟前几节提到的几种算法稍有区别,这里的反馈reward 不再是一个静态的、不包含参数的评价指标,而是一个动态可变的函数,所以求导过程同样要涉及对 reward 的求导,此时梯度下降包含了两项,一项是对策略函数的求导(跟前几节的算法一样),还多了一项是对反馈函数的求导,如下(摘自本人课件)
再一次,我们依然会面临状态空间巨大的问题,所以依然要采样。这里采用的方式是对包含答案的篇章(即所谓的 positive passage)进行随机采样,如下

论文:Fast_abs: Fast Abstractive Summarization with Reinforce-Selected SentenceRewriting (ACL2018)
这篇论文对摘要的处理跟前面提到的两篇做摘要的论文稍有不同,但也是很经典的做法:先从文本中抽取片段,再通过片段生成摘要。其实此类框架很多,但这篇论文尝试将这两个分开的步骤通过强化学习的方式统一到了一起,倒是跟上一节的 R3 有几分相像。抽取部分和生成部分用的都是 state-of-art 的方法:前者是基于pointer-net,后者是 pointer-generator,在这里就不展开讲了。
鉴于本文已写的很长了,能坚持看到这里的读者不容易,所以我们就简单放张图(摘自本人课件),不做太多的介绍
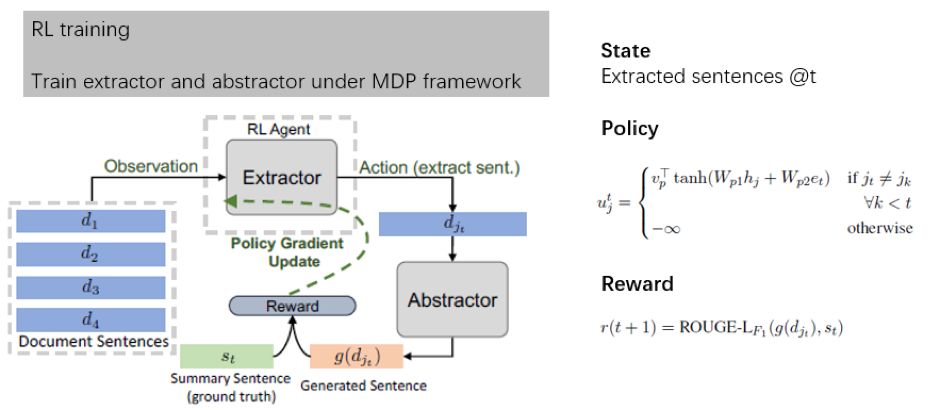
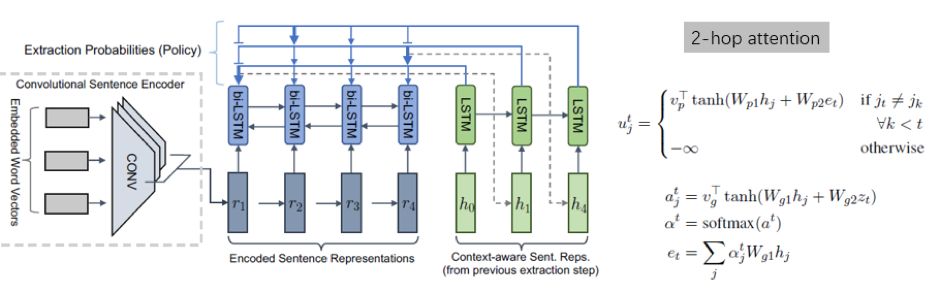
抽取部分用到一个 2-hop attention,蛮有意思的,有兴趣的可以关注下,这里也简单贴个图(摘自本人课件)
通过这五篇文本生成相关论文的总结,我们发现一些共性的特征:即通过强化学习的方法,改造损失函数,从而改进序列生成的过程。但目前文本生成领域所涉及到的强化学习方法都比较简单,基本都是基于策略梯度方法的 REINFORCE 或actor-critic 算法。这些方法都需要一些trick来确保训练过程的稳定性,例如把reward减去一个baseline reward、使用mixing loss和scheduling等等方法来调算法。

微信ID:WeChatAI

登录查看更多
相关内容

Arxiv
8+阅读 · 2020年4月13日
Arxiv
4+阅读 · 2018年11月13日
Arxiv
5+阅读 · 2018年8月6日




相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日
Arxiv
4+阅读 · 2018年11月13日
Arxiv
5+阅读 · 2018年8月6日