从Bounding Boxes中能够学习什么?


Where does it come from?
The Third Research Institute of the Ministry of Public Security



基于视频结构化描述的视频语义分析系统
可描述车辆颜色、车型、品牌等,车型类别>1200类
个性化检索、以图搜图等
参与重大案件侦破数十起:桂林爆炸案、苏州抓捕案、亚信反恐…


那我们从Bounding Boxes中可以得到什么呢?
1. 目标
2. 负类别
3. Bounding Boxes 投票
之前推送也介绍过检测的Pipeline:
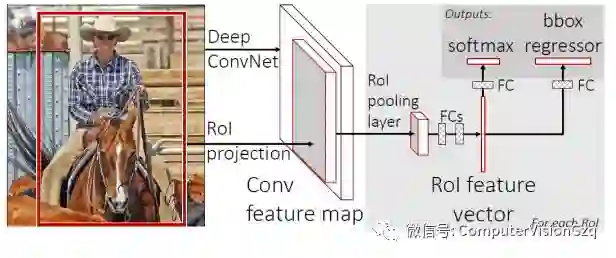
*Fast R-CNN, Ross Girshick, IEEE International Conference on Computer Vision (ICCV), 2015
1. 目标
动机:
正样本必须是目标;
将目标输入到End-to-End的网络PipeLine。
相关工作:
BBox的选择;
DeepBox;
Region proposal networks(RPN)。
过程设置如下:
IoU>0.5的区域,标签设置为1,其余都为0;
只使用End-to-End的网络的训练阶段。
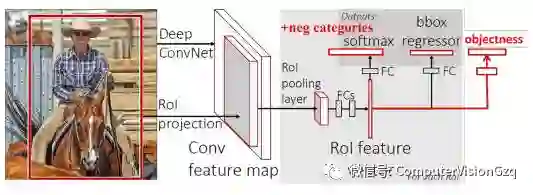
2. 负类别
他人方法:设置所有IoU<0.5的区域为不合理区域。

现在的做法:
设置IoU>0.5的为正样本,0.2<IoU<0.5的为负样本,其余的都是背景。

相似的工作如下:

3. Bounding Boxes 投票
在标准的NMS之后,在局部区域中,保持区域bbox有最高的得分;设置区域为R,IoU>0.5,用R∪boxb的方式来进行投票:
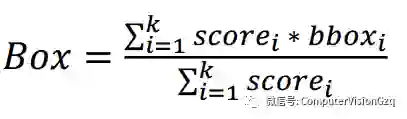

检测结果:

*该实验是在CLS数据集上进行的测试
目标定位
最简单的PipeLine:

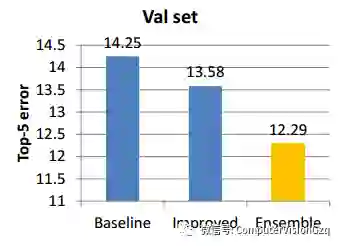
通过上述的方法(目标、负类别和Bounding Boxes 投票),进行简单实验:
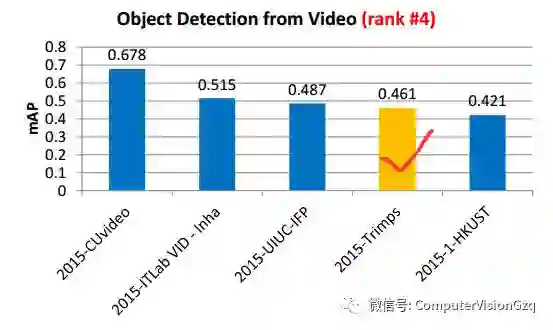
视频中的目标检测

结果:
关注我们的微信公众平台“计算机视觉战队”:
ID:ComputerVisionGzq
在平台中回复“深度学习”、“C++”、“Python”都会有相应的学习资料提供给大家去学习,去实践,希望大家多多支持!
后期我们会继续完善学习资料,并为大家提供GitHub的资源!




