论文浅尝 | 预训练单模态和多模态模型中的视觉常识

笔记整理:李磊,浙江大学硕士,研究方向为自然语言处理、多模态学习。
链接:https://arxiv.org/abs/2205.01850
动机
人类的语言理解通常发生于多模态环境中,这一现象引起了NLP领域对引入视觉信息的日益关注。xxx构建了一个人工标注的颜色常识知识数据集(CoDa),发现语言模型受到了报告偏差(reporting bias)的影响,引入多模态信息可以缓和这种影响。本文进一步研究单模态模型和多模态模型对于五种视觉概念常识(颜色、形状、材质、大小和视觉共现性)的捕获能力,并探讨了报告偏差对于这种能力的影响,具体地说,本文的贡献如下:
1.设计了一个全面的视觉常识分析数据集ViComTe,用于探究视觉常识知识。2.利用ViComTe来探究单模态、多模态和多模态蒸馏模型捕获视觉常识的经验分布的能力。3.分析了数据集中存在报告偏差对于模型的视觉常识捕获能力的影响。
模型结构
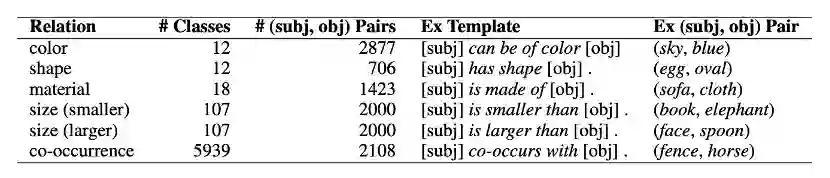
图 1 ViComTe数据集统计
为了探究模型捕获视觉常识的能力,作者基于Visual Genome构建了视觉常识数据集ViComTe。如图1所示,ViComTe包含了5个视觉常识关系:颜色(corlor)、形状(shape)、材质(material)、大小(size)和视觉共现性(co-occurrence),其中,大小关系分为size(smaller)和size(large)。每个视觉常识关系有多种具体的常识类别,如corlor中包含black, blue, read等多种颜色类别。常识数据以(sub, obj)元组的形式进行存储,每种视觉常识类别都包含了一种提示模板,用于构建输入,来从模型中探寻视觉常识知识。每个模板中都包含[subj]和[obj]两个特殊token,[subj]用具体的物体类别(如sky)进行替换,[obj]用[MASK] token进行替换。

图 2模型结构图
在构建ViComTe时,作者统计了物体在某种视觉常识知识上的概率分布情况,并使用构建的模板做探针预测,得到模型输出的概率分布,通过比较两种分布之间的相关性,得出模型对于视觉常识知识的捕获能力。
作者还基于Wikipedia纯文本数据构建了一个常识数据集,用于做对比实验。
实验
作者首先对构建的两个数据集ViComTe和Wikipedia与CoDa数据集进行了对比评估:
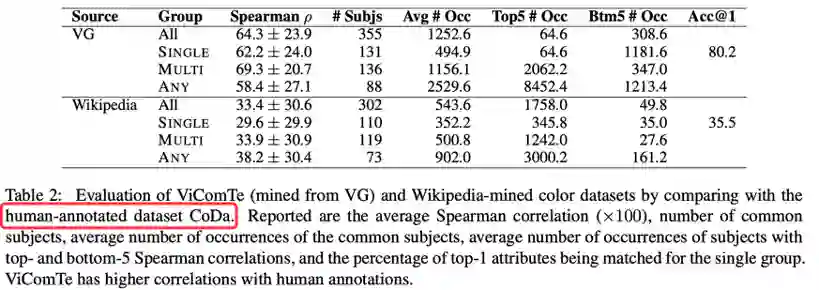
由于CoDa数据集是通过人工标注的手段进行构建的,所以包含的报告偏差较差,通过与CoDa进行对比可得出数据集中存在的报告偏差。如图所示,相比与Wikipedia,ViComTe与CoDa的斯皮尔曼相关性更高,得出ViComTe中报告偏差比Wikipedia数据集要少。作者还将数据集分成了三个子集:SINGLE包含了最常见类别的概率大于80%的物体;MULTI包含了TOP4类别概率和大于90%的物体;ANY包含除SINGLE和MULTI外的其他物体。可以看到,SINGLE的相关性要比MULTI和ANY低,表示SINGLE中报告偏差较为严重。
作者分别测试了单流模型(BERT,ALBERT,RoBERTa)和双流模型(VisualBERT,Oscar,CLIP,vokenization-based model),以及蒸馏Oscar和CaptionBERT。测试时有两种评估方法:
•zero-shot probe:训练任务中有MLM目标的模型,直接输入构造的prompt模板。•representation probe: CLIP这种没有MLM目标的模型,添加一个逻辑回归层,Oscar添加一个单词预测头。
此外作者还使用了soft prompt,针对size关系设计了不同的评估方法。
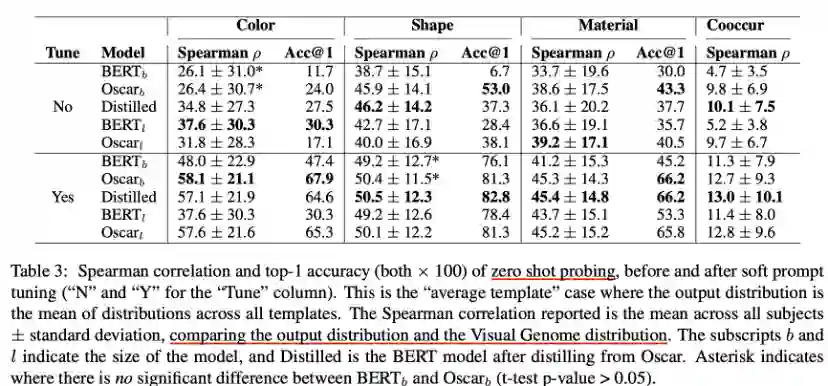
在ViComTe上zero shot probing的结果如上图所示,可以得出以下几个结论:
•单模态模型BERT效果要差于多模态模型Oscar,反映出多模态模型能更好重建视觉属性分布。•模型的参数量增加,效果并不是一致变好,而蒸馏BERT要比纯BERT更好,反映出对于视觉常识掌握来说,数据比参数更重要。•微调soft prompt要比不调效果好。
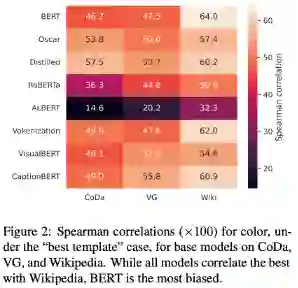
上图是各个模型在三个数据集上的结果分布情况:
•整体上所有模型都与Wikipedia数据集相关程度更好,而Wikipedia数据集受到报告偏差的影响是最大的,说明所有模型都收到了报告偏差的影响。•BERT数据集之间的相关性差距最大,多模态模型差距最小,说明多模态模型受到的影响程度较小。
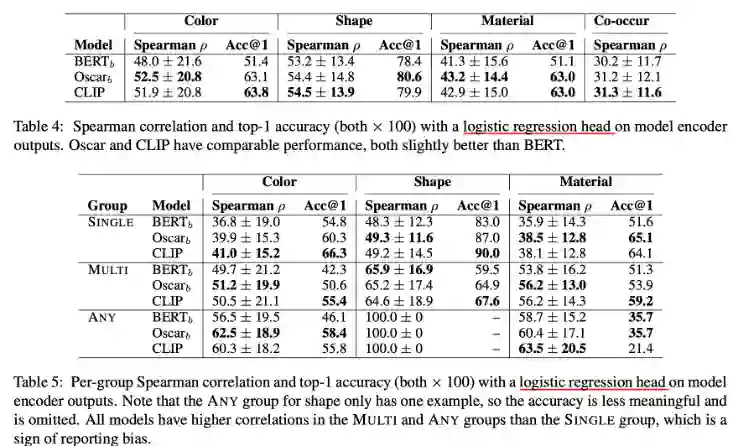
作者使用representation probe方法进一步测试了单模态模型和多模态模型,与之前的结果类似,BERT结果弱于多模态结果,而且细分结果发现SINGLE类别效果要与其他两个类别效果差,说明模型受到了报告偏差的影响。
总结
本文主要探讨了单模态模型和多模态模型对于视觉常识知识的捕获能力,并进一步研究了数据集中存在的报告偏差对于这种能力的影响。通过在两个数据集上进行实验,发现多模态模型和单模态模型对于视觉常识知识的掌握程度都不够,多模态模型表现优于单模态模型,表明视觉信息的引入有助于提高模型对于视觉常识知识的理解。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

