万字综述!从21篇最新论文看多模态预训练模型研究进展

©作者 | 杨浩
单位 | 阿里达摩院
研究方向 | 自然语言处理

背景
多模态预训练模型能够通过大规模数据上的预训练学到不同模态之间的语义对应关系。在图像-文本中,我们期望模型能够学会将文本中的“狗”和图片中“狗”的样子联系起来。在视频-文本中,我们期望模型能够将文本中的物体/动作与视频中的物体/动作对应起来。为实现这个目标,需要巧妙地设计预训练模型来让模型挖掘不同模态之间的关联。

论文调研
自然语言处理(NLP)领域在 2018 年提出的 BERT 模型(双向 Transformer 结构,利用了 self-attention 来增加上下文的相关性)逐渐成为了语言任务中首选的预训练模型。但在视觉与语言交叉的领域还没有出现一个通用的预训练模型,提出视觉与语言统一建模。
method:
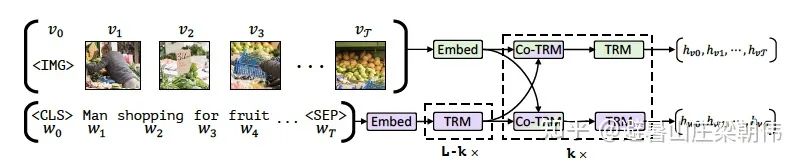
图片和文本分别经过两条不同的 stream 进入 co-attentional transformer 层中(普通的 Transformer 中,query、key、value 来自上一层 Transformer。而这里提出的全新的 co-transformer 则同时利用了上一层中视觉和语言的信息,视觉和语言两条 stream 分别使用了自己的 query 和来自另一边的 key 和 value 向量),图片采用 Faster R-CNN 模型从图像中提取多个目标区域的特征,由于图片特征不像文字特征一样含有位置信息,因此用 5 维数据给图片位置编码,它们分别是归一化之后左上角坐标,右下角坐标,以及面积。然后将其投影到匹配视觉特征的维度,并对其求和。
task:
Masked Language Modeling(MLM):15%(80%,10%,10%)
Masked Object Classifation(MOC):15%(90%,10%)---语言只能表达图片的高阶语义信息
-
Visual-linguistic Matching(VLM)

motivation:
文字和图片统一进行语义学习,提出单流的方法(更简单)
method:
不像 vilbert 一样图文和文字分别进入 transformer 进行学习,将文本和图片一起输入 transformer。因为单流,需要增加段编码。
a. 一部分文本被mask掉,根据剩余的文本和图像信息来预测被 mask 掉的信息。
b. 模型来预测提供的文本是否和图片匹配。作者发现这种在图片标注数据上的预训练对于 visualBert 学习文本和图像的表征非常重要。
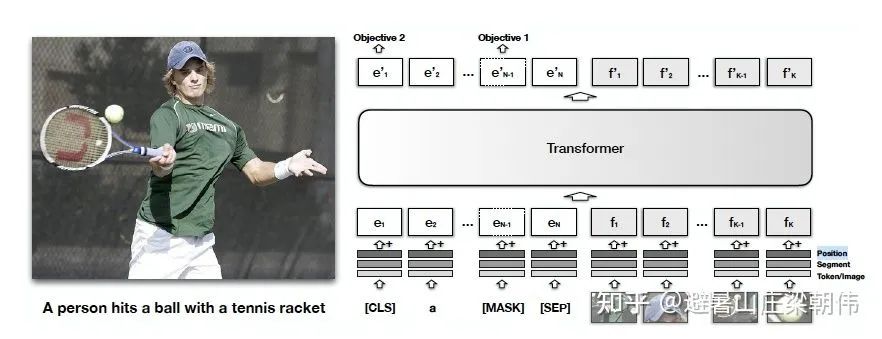
motivation:
和 visualbert 一样属于单流模型,增加到三个预训练任务
1)MaskedLanguage Modeling(MLM):将一部分的词语进行 mask,任务是根据上下文推断该单词。
2)Masked Object Classification(MOC):对图像的一部分内容进行 mask,任务是对图像进行分类,此处的分类使用的依然是目标检测技术,只是单纯的将目标检测中置信度最高的一项作为分类类别。
3)Visual-linguistic Matching(VLM):利用 [CLS] 的最终隐藏状态来预测语言句子是否与视觉内容语义匹配,并增加了一个 FC 层。
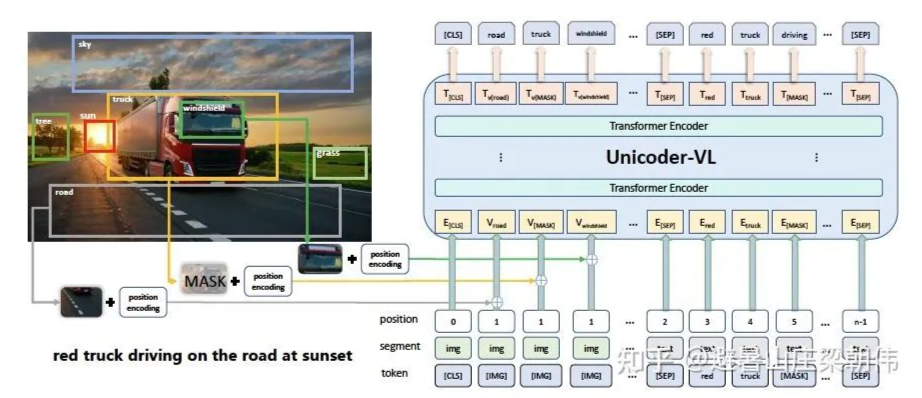
motivation:
和 vilbert 不同的是 cross-attention 在 cross 操作后加入一个全连接层,同时融合了图片和文字的信息。增加了一些预训练任务目标,比如 Masked Cross-Modality LM。增加图像问答任务到预训练任务中(引入 vqa 等数据集的训练集)。
method&task:
掩蔽文本预测(Masked Cross-Modality LM)该任务的设置与 BERT 的 MLM 任务设置一致。作者认为除了从语言模态中的非模态词中预测被掩蔽词外,LXMERT 还可利用其跨模态模型架构,从视觉模态中预测被掩蔽词,从而解决歧义问题,所以将任务命名为 Masked Cross-Modality LM 以强调这种差异。
掩蔽图像类别预测(Detected-Label Classification)该任务要求模型根据图像线索以及对应文本线索预测出直接预测被遮蔽 ROI 的目标类别。
掩码图像特征回归(RoI-Feature Regression)不同于类别预测,该任务以 L2 损失回归预测目标 ROI 特征向量。
图片-文本对齐(Cross-Modality Matching)通过 50% 的概率替换图片对应的文本描述,使模型判断图片和文本描述是否是一致的。
图像问答(Image Question Answering)使用了有关图像问答的任务,训练数据是关于图像的文本问题。当图像和文本问题匹配时,要求模型预测这些图像有关的文本问题的答案。
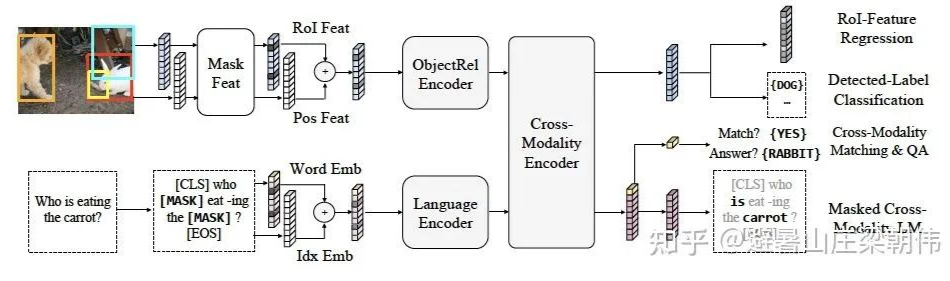
motivation:
(1) 之前论文(例如,ViLBERT(Lu et al.,2019)和 LXMERT(Tan & Bansal,2019))所使用的句子-图像关系预测任务对视觉语言表征的预训练毫无帮助。因此,这样的任务不包含在 VL-BERT 中。
method:
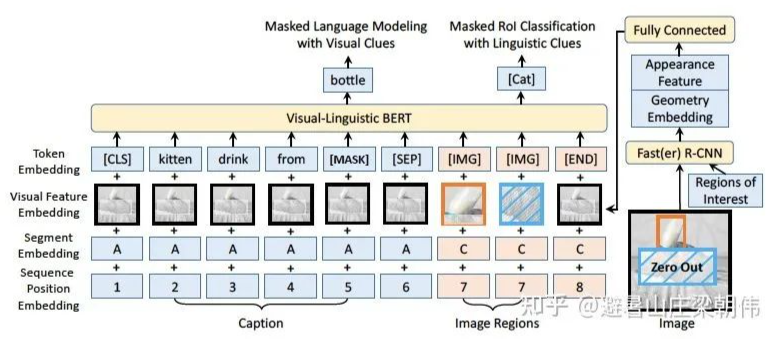
Token embedding 层:对于文本内容使用原始 BERT 的设定,但是添加了一个特殊符 [IMG] 作为图像的 token。
Visual feature embedding 层:这层是为了嵌入视觉信息新添加的层。该层由视觉外部特征以及视觉几何特征拼接而成,具体而言,对于非视觉部分的输入是整个图像的提取到的特征,对应于视觉部分的输入即为图像经过预训练之后的 Faster R-CNN 提取到的 ROI 区域图像的相应视觉特征。
Segment embedding 层:模型定义了 A、B、C 三种类型的标记,为了指示输入来自于不同的来源,A、B 指示来自于文本,分别指示输入的第一个句子和第二个句子,更进一步的,可以用于指示 QA 任务中的问题和答案;C 指示来自于图像。
Position embedding 层:与 BERT 类似,对于文本添加一个可学习的序列位置特征来表示输入文本的顺序和相对位置。对于图像,由于图像没有相对的位置概念,所以图像的 ROI 特征的位置特征都是相同的。
作者在视觉-语言数据集以及纯语言数据集上都进行了大规模的预训练,使用概念标题数据库(Conceptual Captions)数据集作为视觉-语言语料库,该数据集包含了大约 330 万张带有标题注释的图片,图片来自于互联网。但是这个数据集存在一个问题就是图像对应的标题是简短的句子,这些句子很短并且很简单,为了避免模型只关注于简单子句,还使用了 BooksCorpus 和英语维基百科数据集进行纯文本的训练。
task:
掩蔽文本预测(Masked Language Model with visual Clues)此任务与 BERT 中使用的 Masked Language Modeling(MLM)任务非常相似。关键区别在于,在 VL-BERT 中包含了视觉线索,以捕获视觉和语言内容之间的依存关系。
掩蔽图像类别预测(Masked RoI Classification with Linguistic Clues)类似于掩蔽文本预测,每个 RoI 图像以 15% 的概率被随机掩蔽,训练的任务是根据其他线索预测被掩藏的 RoI 的类别标签。值得一提的是为了避免由于其他元素的视觉特征的嵌入导致视觉线索的泄漏,在使用 Faster R-CNN 之前,需要先将被 Mask 的目标区域的像素置零。
a)有文本的预训练任务比没有文本的预训练任务效果更好;
b)Vison+Language 组合的预训练效果要好于单独的 Vision/Language;
c)最好的预训练组合是:MLM+ITM+MRC-kl+MRFP;
d)将上面提到的四个数据一起训练效果最好,这也证明数据越多效果越好。
e)扩大的数据集
method&task:
a)MLM(conditioned on image,遮字模型)
b)MRM(Mask Region Model,预测图像,回归或分类,有三种变体)--MRC(Mask Region Cls),MRFR(Mask Regin Feature Regress),MRC-KL(MRC + KL divergency)
c)ITM(Image Text Match,图文是否一致)
d)WRA(Word Region Alignment,字和图像的对齐任务)
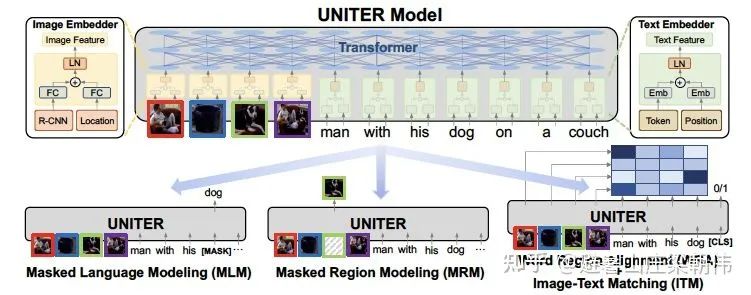
主要扩展数据,1 千万网上爬取处理好的图文 pair 数据,之前 UNITER 组合了四个数据集(Conceptual Captions,SBU Captions,Visual Genome, MSCOCO),形成了一个 960 万的训练语料库,并在多个图像-文本跨模态任务上实现了最佳结果。LXMERT 将一些 VQA 训练数据增添到预训练中,并且在 VQA 任务上也获得了最佳结果。
证明数据越大越好
method&task:
在模型预训练过程中,设计了四个任务来对语言信息和视觉内容以及它们之间的交互进行建模。四个任务分别为:掩码语言建模(Masked Language Modeling)、掩码对象分类(Masked Object Classification)、掩码区域特征回归(Masked Region Feature Regression)、图文匹配(Image-Text Matching)。
掩码语言建模简称 MLM,在这个任务中的训练过程与 BERT 类似。并引入了负对数似然率来进行预测,另外预测还基于文本标记和视觉特征之间的交叉注意。
掩码对象分类简称 MOC,是掩码语言建模的扩展。与语言模型类似,其对视觉对象标记进行了掩码建模。并以 15% 的概率对物体对象进行掩码,在标记清零和保留的概率选择上分别为 90% 和 10%。另外,在此任务中,还增加了一个完全的连通层,采用了交叉熵最小化的优化目标,结合语言特征的上下文,引入负对数似然率来进行预测正确的标签。
掩码区域特征回归简称 MRFR,与掩码对象分类类似,其也对视觉内容建模,但它在对象特征预测方面做得更精确。顾名思义,该任务目的在于对每个掩码对象的嵌入特征进行回归。在输出特征向量上添加一个完全连通的图层,并将其投影到与汇集的输入 RoI 对象特征相同的维度,然后应用 L2 损失函数来进行回归。
值得注意的是,上述三个任务都使用条件掩码,这意味着当输入图像和文本相关时,只计算所有掩码损失。
在图文匹配任务中,其主要目标是学习图文对齐(image-text alignment)。具体而言对于每个训练样本对每个图像随机抽取负句(negative sentences),对每个句子随机抽取负图像(negative images),生成负训练数据。在这个任务中,其用二元分类损失进行优化。
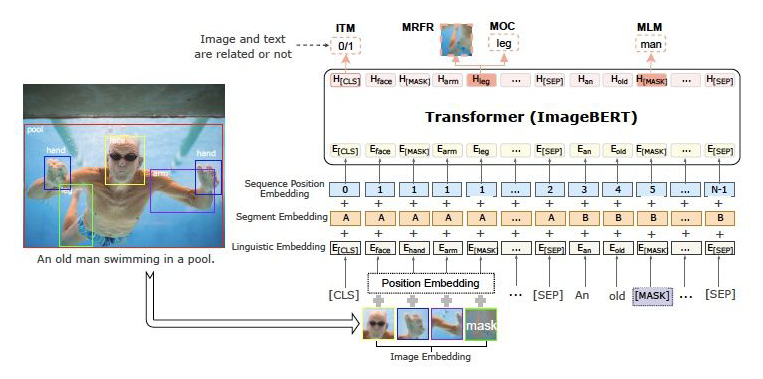
motivation:
多模态任务的一大难点是:不同模态之间存在语义鸿沟(semantic gap),在之前的工作中,例如 VQA,Image Captioning 中,使用在图片分类任务中预训练的 CNN 来获取图片特征。后来,随着 attention 机制的提出,大多数视觉-语言方法使用了利用目标检测模型获取到的 region-based 视觉特征。
method&task:
a)句子编码:采用跟 bert 一样的编码方式。
b)图片编码:对图片进行卷积,池化,最后得到一个特征矩阵(元素为特征向量),对其进行采样后,每个元素与一个 semantic embedding 相加,相当于一种偏置。最后展平,得到最终的像素特征编码。
c)多模态编码:将两种表示拼接在一起,过 TRM,得到最终的表示。
d)任务:MLM 任务和图片-文本匹配任务

motivation:
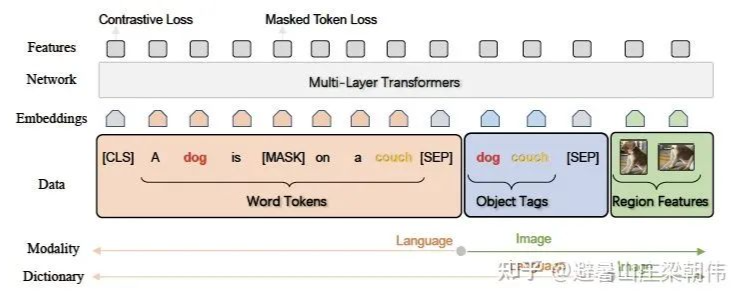
提出了一种新的学习方法 Oscar,它用图像中检测到的对象标签作为锚点,在一个共享的语义空间中对齐图像和语言模态。在一个有 650 万个图像-文本对的公共语料库上对 Oscar 模型进行了预训练,验证了 Oscar 的有效性。
将词符、对象标签、区域特征作为输入,增加 mask token loss 和 contrastive loss。
motivation:
提出跨度更大的 mask 和高阶交互特征后保持模态独立性方法
method&task:
masked segment modeling(MSM)
masked region modeling(MRM)
Image-Text Matching with Hard Negatives 构建了强负例(根据 tf-idf)
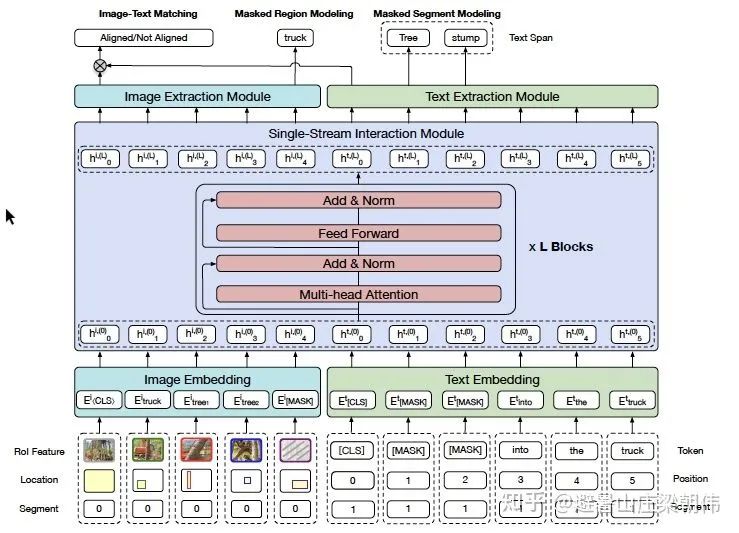
motivation:
预训练和微调在本质上是紧密联系的。模型的训练需要掌握本质的推理技巧,从而促使模态融合,进行跨模态的联合理解。
通过在 pre-training stage,执行对抗训练, 改善的泛化能力对微调阶段也是有益的;
在微调阶段,任务相关的微调信号变得可用,对抗微调可以用于进一步的改善性能。
由于 pre-training 和 finetuning 共享同一个数学表达式,同样的对抗算法可以在两个阶段都采用。
method&task:
freelb(对抗训练)+多模态预训练目标

12. ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph AAAI 2021
motivation:
当人们看一张图的时候,首先会关注图中的物体(Objects)以及特点属性(Attributes)和期间的关系(Relationships)。如:“车”、 “人”、“猫”、“房屋” 等物体构成了图片场景中的基本元素;而物体的属性,如:“猫是白的”,“汽车是棕色的” 则对物体做了更精细的刻画;物体间的位置和语义关系,如:“猫在车上”,“车在房屋前” 等,建立了场景中的物体的关联。因此,物体、属性和关系共同构成了描述视觉场景的细粒度语义(Detailed Semantics)。
图片信息代表着视觉上最基础,最直观的信息。而更深层的语义信息,比如图像的内涵,历史背景,人物动作,因果关系推理等。
基于此观察,将包含场景先验知识的场景图(Scene Graph)融入到多模态预训练过程中,建模了视觉-语言模态之间的细粒度语义关联,学习到包含细粒度语义对齐信息的联合表示。
method:
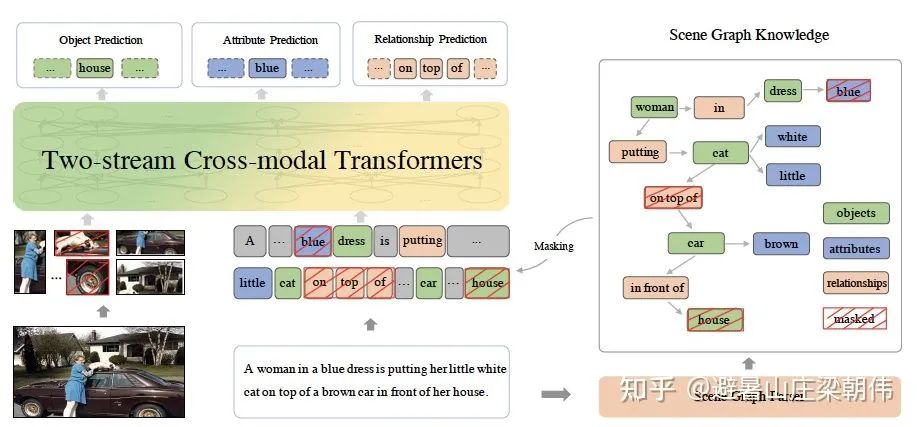
提出了三个多模态预训练的场景图预测(Scene Graph Prediction)任务:物体预测(Object Prediction)、属性预测(Attribute Prediction)、关系预测(Relationship Prediction)。
物体预测:随机选取图中的一部分物体,如下图中的“house”,对其在句子中对应的词进行掩码,模型根据文本上下文和图片对被掩码的部分进行预测;
属性预测:对于场景图中的属性 - 物体对,如下图中的“<dress, blue>”,随机选取一部分词对其中的属性进行掩码,根据物体和上下文和图片对其进行预测;
关系预测:随机选取一部分 “物体 - 关系 - 物体” 三元组,如下图的“<cat, on top of, car >”,然后对其中的关系进行掩码,模型根据对应的物体和上下文和图片对其进行预测。
task:
除了场景图预测,增加掩码语言模型(Masked Language Modelling)、掩码图像区域预测(Masked Region Prediction)、图文对齐(Image-Text Matching)等任务
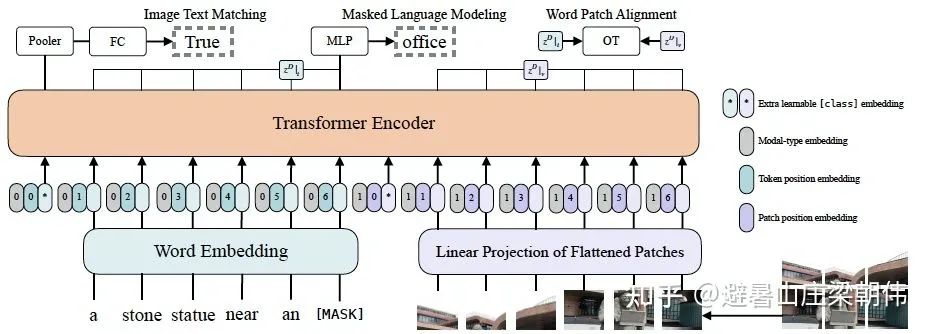
motivation:
基于 patch projection 的多模态方法,提升了速度,但是整体上性能还是略低于 region feature 的方法
method:
文本特征输入部分,将文本看成一个词序列,通过 word embedding matrix 转化成 word embedding,然后和 position embedding 进行相加,最后和 modal-type embedding 进行 concate。
图像特征输入部分,将图像切块看成一个图像块序列,通过 linear projection 转化成 visual embedding,然后和 postion embedding进行相加,最后和 modal-type embedding 进行 concate。
其中word embedding和visual embedding通过可学习的 modal-type embedding 标志位来区分,其中 0 标志位表示 word embedding 部分,1 标志位表示 visual embedding 部分。
word embedding 和 visual embedding 分别都嵌入了一个额外的可学习 [class] embedding,方便和下游任务对接。
task:
ViLT 预训练的优化目标有两个:一个是 image text matching(ITM),另一个是 masked language modeling(MLM)。
ImageText Matching:随机以 0.5 的概率将文本对应的图片替换成不同的图片,然后对文本标志位对应输出使用一个线性的 ITM head 将输出 feature 映射成一个二值 logits,用来判断图像文本是否匹配。另外 ViLT 还设计了一个 word patch alignment(WPA)来计算 teextual subset 和 visual subset 的对齐分数。
Masked Language Modeling:MLM 的目标是通过文本的上下文信息去预测 masked 的文本 tokens。随机以 0.15 的概率 mask 掉 tokens,然后文本输出接两层 MLP,然后文本输出接两层 MLP 预测 mask 掉的 tokens。。
Whole Word Masking:另外 ViLT 还使用了 whole word masking 技巧。whole word masking 是将连续的子词 tokens 进行 mask 的技巧,避免了只通过单词上下文进行预测。比如将“giraffe”词 tokenized 成 3 个部分 ["gi", "##raf", "##fe"],可以 mask 成 ["gi", "[MASK]", "##fe"],模型会通过 mask 的上下文信息 [“gi”,“##fe”] 来预测 mask 的“##raf”,就会导致不利用图像信息。
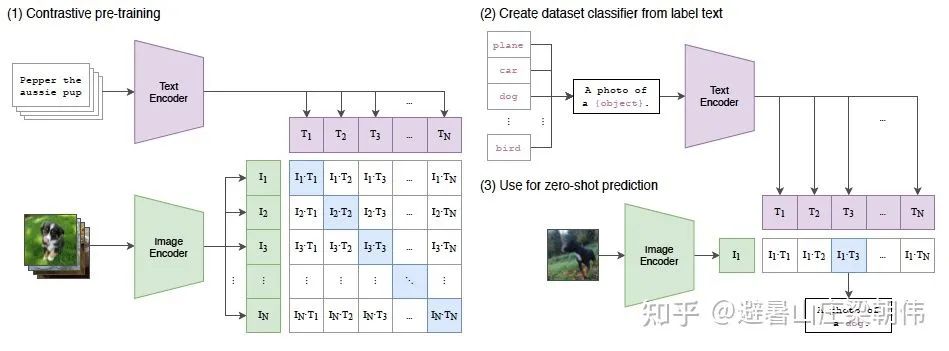
motivation:
将分类模型转换成图文匹配任务,用文本来弱监督图片分类。PET 在视觉分类上的应用,用 4 亿对来自网络的图文数据集,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图上的 concepts 对应的文本描述,就可以进行 zero-shot transfer。用 linear prob 进行评估,在 27 个数据集的平均分数甩了其他模型好几条街。同时有 20 个都比 ImageNet 训练出来的开源 SOTA 表现好,并且在 256 个 GPU 上训练两周就好了。
method&task:
1. CLIP 将一批文本通过 Text Encoder 编码成一批 word embedding,将一批图片(与文本一一对应)通过 Image Encoder 编码成一批 feature embedding,然后将对应的 word embedding 和 feature embedding 先归一化然后进行点积得到相似度矩阵,点积数值越大,代表 word embedding 和 feature embedding 的向量越相似,这里的监督信号就是矩阵对角线为 1,其余位置为 0。其中 Text Encoder 使用的是 Transformer,而 Image Encoder 使用 ResNet50 和 ViT 两种架构其中一个,Image Encoder 和 Text Encoder 都是从头训练。
2. 然后将预训练好的 CLIP 迁移到下游任务,先将下游任务的标签构建为一批带标签的文本(例如 A photo of a {plane}),然后经过 Text Encoder 编码成一批相应的 word embedding。
3. 最后将没有见过的图片进行 zero-shot 预测,通过 Image Encoder 将一张小狗的图片编码成一个 feature embedding,然后跟(2)编码的一批 word embedding 先归一化然后进行点积,最后得到的 logits 中数值最大的位置对应的标签即为最终预测结果。
从 CLIP 的流程中可以看出,CLIP 和 PET 的 prompt 使用方式非常相似,A photo of a 就是一个人为设计的 prompt。
后续的 CoOp 感觉就是对应 p-tuning,完成 PET->P-tuning 的发展
motivation:
已有的预训练模型主要是单独地针对单模态或者多模态任务,但是无法很好地同时适应两类任务。同时,对于多模态任务,目前的预训练模型只能在非常有限的多模态数据(图像-文本对)上进行训练。本文提出了一个统一模态预训练框架 UNIMO,能够有效地同时进行单模态和多模态的内容理解和生成任务。
method:
论文融入单模的文本、图片和图文 pair,采用双流的模型,提出跨模态对比学习。文本侧通过回译、tf-idf 检索出正样本,通过场景图解析和改写生成强负例。视觉侧通过目标检测和 tf-idf 检测出正样本。对于 CMCL,每一个图像-文本对正样本会和几个通过句子改写的难分负样本、以及几个通过检索的图片正样本和文本正样本拼接起来;其他图像-文本对的所有样本也会视为负样本。
task:
视觉学习:和 BERT 中的 masked 语言模型类似,也对每一张图片进行图像区域的采样,并将图像区域特征以 15% 的概率进行掩码处理。被掩盖的图像区域特征采用零值代替。由于一张图片的某个区域可能和其他区域有高度重叠,所以设置了一个重叠度的阈值(本文设置为 0.3),高于该阈值的所有区域都会被掩盖,以防止信息泄露。由于视觉特征向量往往是高维且连续的,因此同时采用特征回归和目标类别分类两个指标来更好地学习视觉表征。
语言学习:
UNIMO 很大的优势是能同时使用单模数据和多模数据进行预训练,从而利用大规模数据学习更强大的统一模态语义表示。为了验证单模数据的有效性,论文还进行了分离实验。实验结果表明,当不使用文本单模数据进行预训练的时候,UNIMO 在多模任务上效果有所下降。而当不使用多模图文对数据和图像数据的时候,UNIMO 在文本理解和生成任务上同样会下降。这充分说明了单模数据在统一模态 学习中的有效性,也说明了 UNIMO 模型可以有效利用不同模态数据进行跨模态联合学习。
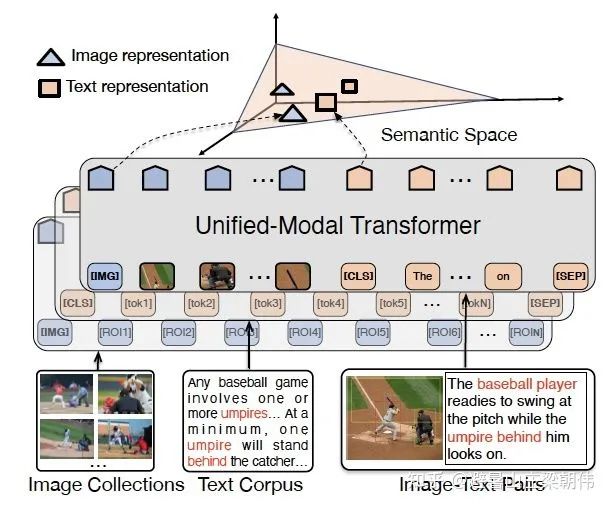
motivation:
传统的文本到图像生成方法是侧重于找到更好的建模假设,方便在固定数据集上进行训练。但这些假设可能涉及到复杂结构、auxiliary losses(辅助损失)或者在训练过程中提供的目标部分标签或分割掩码等侧面信息。
method&task:
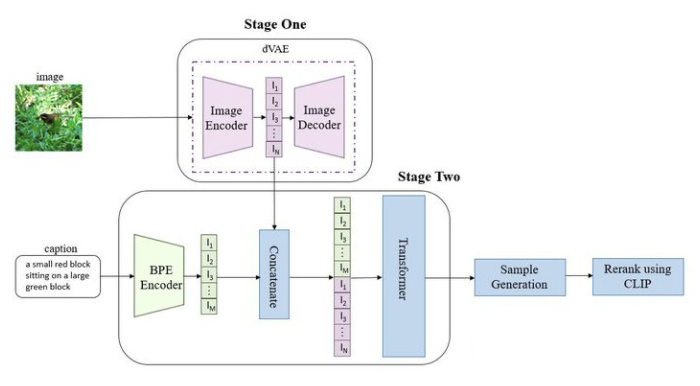
1. 第一个阶段,先训练一个 dVAE 把每张 256x256 的 RGB 图片压缩成 32x32 的图片 token,每个位置有 8192 种可能的取值(也就是说 dVAE 的 encod er 输出是维度为 32x32x8192 的 logits,然后通过 logits 索引 codebook 的特征进行组合,codebook 的 embedding 是可学习的)。
2. 第二阶段,用 BPE Encoder对文本进行编码,得到最多 256 个文本 token,token 数不满 256 的话 padding 到 256,然后将 256 个文本 token 与 1024 个图像 token 进行拼接,得到长度为 1280 的数据,最后将拼接的数据输入 Transformer 中进行自回归训练。
3. 推理阶段,给定一张候选图片和一条文本,通过 transformer 可以得到融合后的 token,然后用 dVAE 的 decoder 生成图片,最后通过预训练好的 CLIP 计算出文本和生成图片的匹配分数,采样越多数量的图片,就可以通过 CLIP 得到不同采样图片的分数排序。
从以上流程可知,dVAE、Transformer 和 CLIP 三个模型都是不同阶段独立训练的。
DALL·E 中的 Transformer 结构由 64 层 attention 层组成,每层的注意力头数为62,每个注意力头的维度为 64,因此,每个 token 的向量表示维度为 3968。attention 层使用了行注意力 mask、列注意力 mask 和卷积注意力 mask 三种稀疏注意力。文本不满 256 个 token 时,使用 pad embed 填充,文本 token 需要加上 pos embed,图片 token 需要加上行列的 embed,这些 embed 都是可学习的。
如今,AI 在一些细分领域逐渐向人类发起挑战,如围棋(AlphaZero)、蛋白质结构预测(AlphaFold)等等,DALL·E 则是对绘画、设计领域向人类发起挑战。

总结与展望

大模训练方法
motivation:
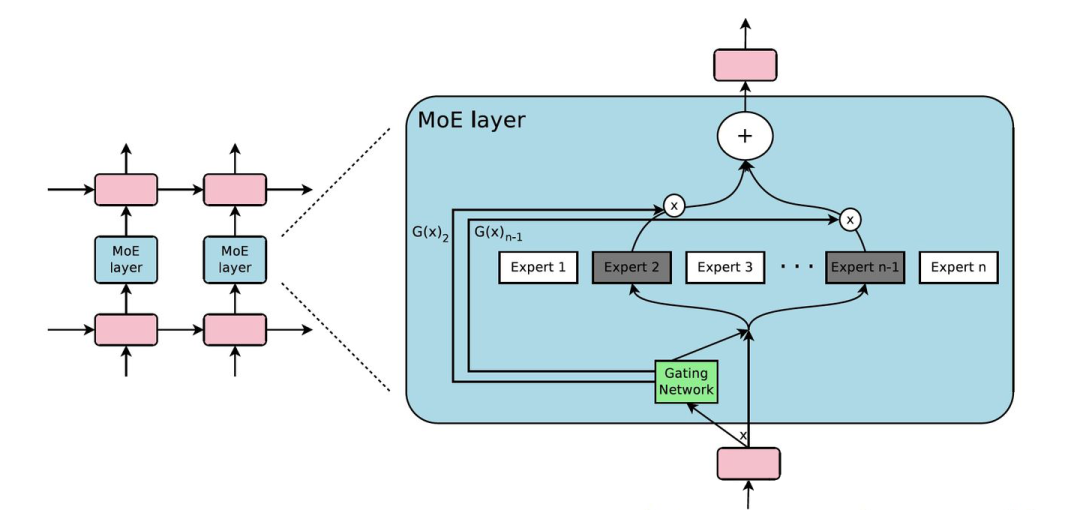
现在的模型越来越大,训练样本越来越多,每个样本都需要经过模型的全部计算,这就导致了训练成本的平方级增长。为了解决这个问题,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。那么如何决定一个样本去经过哪些小模型呢?这就引入了一个稀疏门机制,即样本输入给这个门,得到要激活的小模型索引,这个门需要确保稀疏性,从而保证计算能力的优化。
method:
首先 MoE 是一个层,而不是一整个模型。其次,正如我们刚才所说,这个模型结构包含一个门网络来决定激活哪个 expert,同时包含 n 个 expert 网络,这 n 个 expert 网络一般是同结构的。
保证稀疏性和均衡性,对这个 softmax 做了处理,第一个变动就是 KeepTopK,这是个离散函数,将 top-k 之外的值强制设为负无穷大,从而 softmax 后的值为 0。第二个变动是加了 noise,这个的目的是为了做均衡,这里引入了一个 Wnoise 的参数,后面还会在损失函数层面进行改动。
如果不做改进,那么这么多的 expert,只有几个 expert 会被集中使用。为了改进这一问题,采用软性约束方法。我们定义对于一个批次训练样本的专家重要度(the importance of an expert),即该专家在一个批次上的门控输出值的和。并且定义损失项加入到模型的总损失上。该损失项等于所有专家重要度的方差的平方,再加上一个手工调节的比例因子。这个损失项会鼓励所有专家有相同的重要度。
motivation:
利用模型并行方法解决大模型训练的问题,侧重张量 Tensor 并行提升训练速度。实现了简单而高效的模型并行方法,成功突破了传统单个 GPU 训练的限制。
method:

motivation:
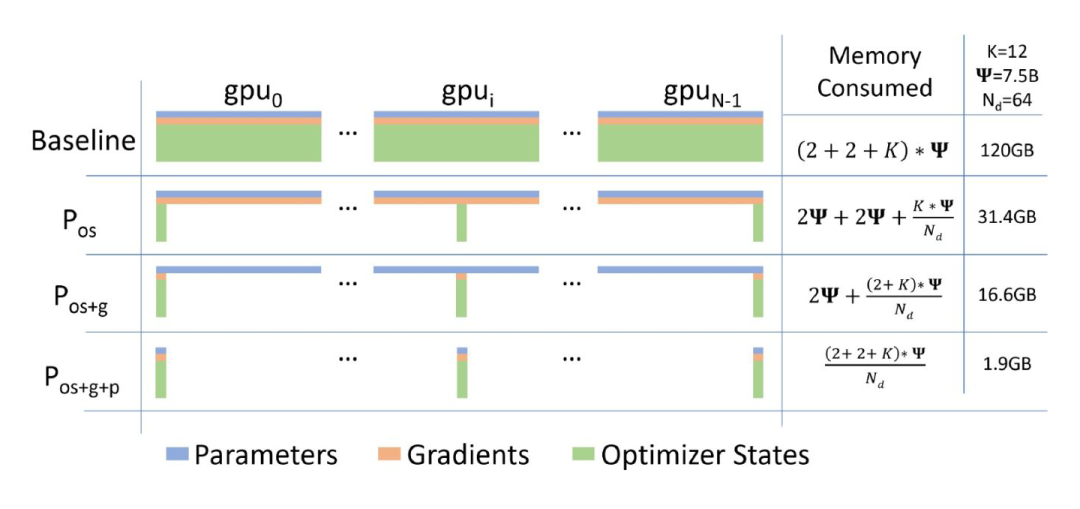
解决每个 gpu 都存整个模型的参数,导致显存超出的问题,减少显存,增加计算开销。当前分布式训练主要的三种并行模式:数据并行、模型并行和流水线并行。在三种并行方式中,数据并行因其易用性,得到了最为广泛的应用。然而,数据并行会产生大量冗余 Model States 的空间占用。
1. Optimizer States:Optimizer States 是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的 Momentum 以及使用混合精度训练时的 Float32 Master Parameters。
ZeRO 有三个不同级别,分别对应对 Model States 不同程度的分割 (Paritition):- ZeRO-1:分割 Optimizer States;- ZeRO-2:分割 Optimizer States 与 Gradients;- ZeRO-3:分割 Optimizer States、Gradients 与 Parameters
最后我们总结 zero 优化后的训练步骤流程,我们以 Pos+g+p 这个模式为例:
初始状态:
假设有 Nd 个 gpu,则每个 gpu(gpu_n)保存总参数的 1/Nd;并且保存这些参数对应的梯度、优化器状态(P_n,G_n,O_n);参数可以按层划分;每个 gpu_n 同时还负责分配到自己身上的数据 data_n(数据并行);
a. 正向计算第一层时,gpu_n 将自己负责的参数(P_n)广播给其它所有的 gpu;后面的模型层以此类推;最后每个 gpu_n 获得自己对应数据 data_n 的 loss_n;
b. 进行反向计算,此时需要 gpu_n 将自己负责的参数(P_n)广播给其它所有的 gpu,最后计算得到对应于数据 data_n 的梯度;
c. 将第二步的梯度聚合到对应的 gpu_n 上,每个 gpu 负责更新自己的 P_n,G_n,O_n;
进行下一次迭代
从这个训练流程,可以看出,传递参数过程中它使用了广播的方式,而梯度聚合过程则使用了类似 Allreduce中 reduce-scatter 的模式,但不再需要进行 all-gather,因为每个 gpu 只需要更新自己负责的部分参数。
motivation:
第一个把 MoE 结构引入 Transformer 结构的工作,GShard 将 Transformer 中的 Feedforward Network(FFN)层替换成了 MoE 层,并且将 MoE 层和数据并行巧妙地结合起来。在数据并行训练时,模型在训练集群中已经被复制了若干份。GShard 通过将每路数据并行的 FFN 看成 MoE中的一个专家来实现 MoE 层,这样的设计通过在多路数据并行中引入 All-to-All 通信来实现 MoE 的功能。
method:
其实就是把原来的 FFN(两层全连接)替换成了 MoE 结构
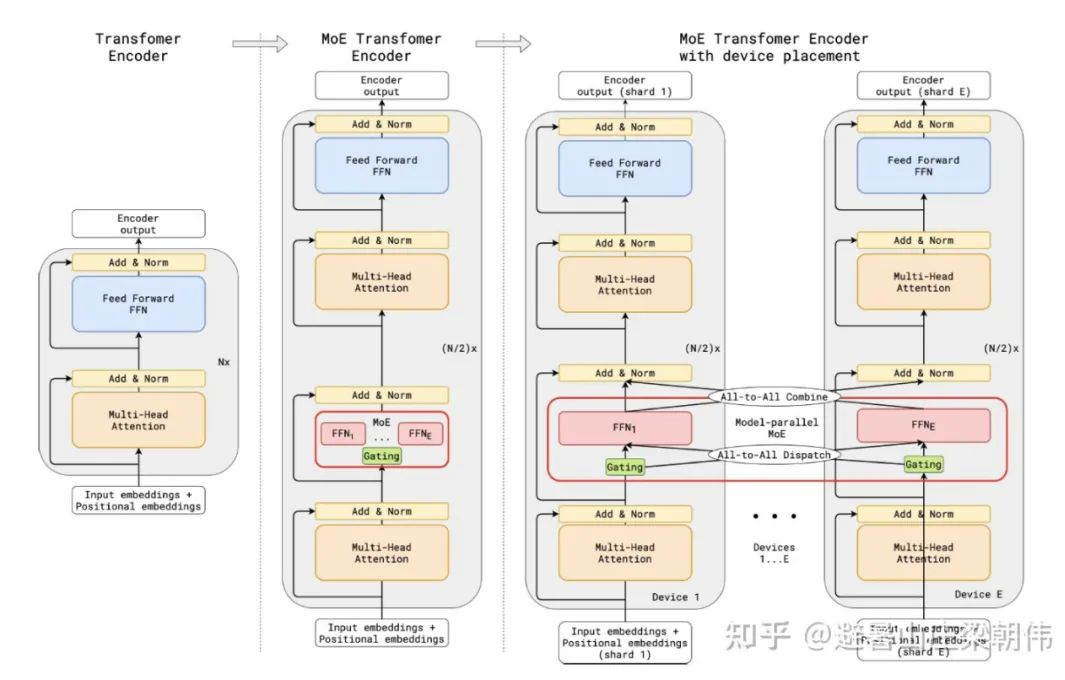
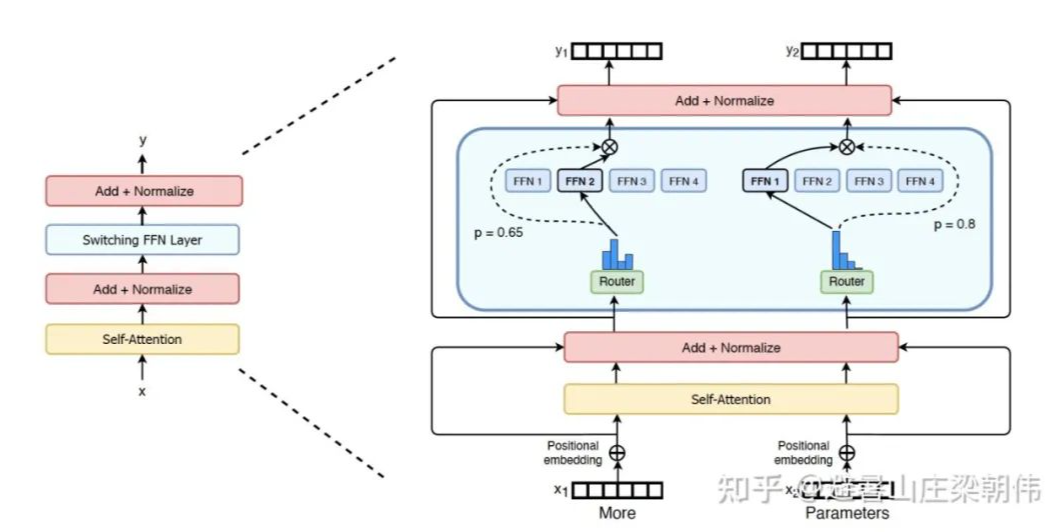
motivation:
将语言模型的参数量扩展至 1.6 万亿,简化了 MoE 路由算法,只将 token 表征发送给单个专家。研究表明,这种简化策略保持了模型质量,降低了路由计算,并且性能更好。将这种 k=1 的策略称为 Switch 层。如果将太多 token 发送给一个专家(下文称为「丢弃的 token」),则会跳过计算,token 表征通过残差连接直接传递到下层。但增加专家容量也不是没有缺点,数值太高将导致计算和内存浪费,最后应用到 t5 模型上。
method:
简化稀疏路由:只将 token 表征发送给单个专家
高效稀疏路由:太多 token 发送给一个专家,则会跳过计算,token 表征通过残差连接直接传递到下层
提升训练和微调的技巧:正则化大型稀疏模型,对大型稀疏模型使用可选择行精度
预训练可扩展性:专家的数量是扩展模型最有效的维度
基于步数的可扩展性:在保持每个 token 的 FLOPS 不变时,拥有更多的参数(专家)可以提高训练速度。
基于时间的可扩展性:在训练时间和计算成本都固定的情况下,Switch Transformer 的速度优势非常明显。
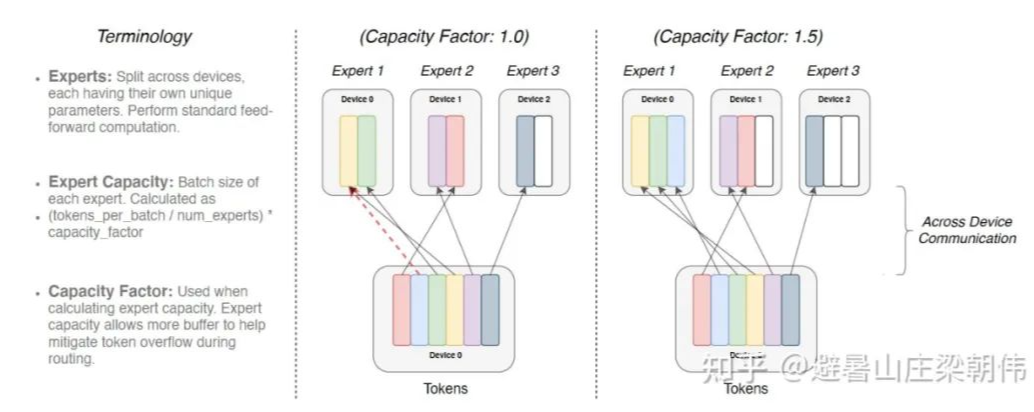
附录:
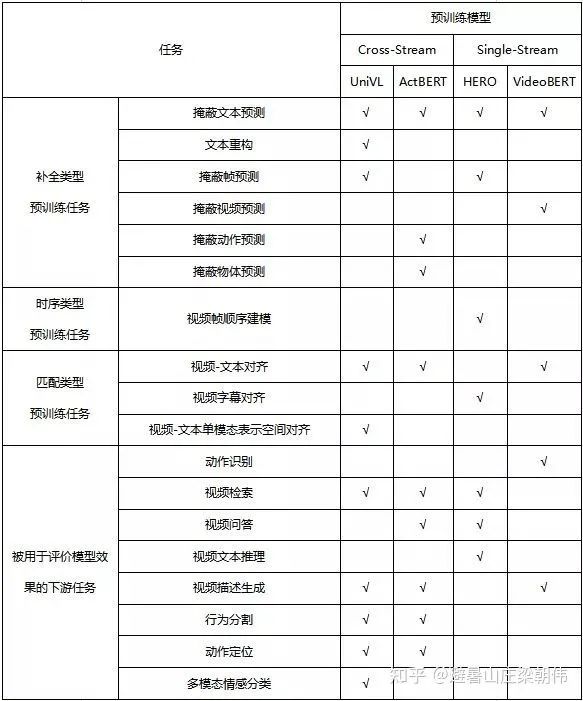
多模态模型task对比
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



