论文浅尝 | IRW:基于知识图谱和关系推理的视觉叙事框架

笔记整理:孙悦,天津大学
链接:https://www.aaai.org/AAAI21Papers/AAAI-3382.XuC.pdf
动机
视觉叙事是生成一个短篇故事来描述有序图像流的任务。与视觉字幕不同,故事不仅包含事实描述,还包含未出现在图像中的想象概念。在本文中,我们提出了一种新颖的想象-推理-编写生成框架 (IRW),用于视觉叙事,其灵感来自人类编写故事时的逻辑。首先,利用多模态想象模块明确学习富有想象力的故事情节,提高生成故事的连贯性和合理性。其次,我们采用关系推理模块,通过基于故事情节的关系推理方法充分利用外部知识(常识知识库)和任务特定知识(场景图和事件图)。通过这种方式,我们可以有效地捕捉图像中对象之间信息量最大的常识和视觉关系,增强生成故事的多样性和信息量。最后,我们整合视觉信息和语义(概念)信息来生成故事。在基准数据集(即 VIST)上进行的大量实验表明,所提出的 IRW 框架在多个评估指标上大大优于最先进的方法。
亮点
IRW的亮点主要包括:
1.为视觉叙事提出了一种新颖的想象-推理-编写生成框架2.提出了一种检索增强的方法来从训练语料库构建事件图。事件图从相似图像的故事中学习高级事件,可以为故事生成提供辅助知识。3.在基准数据集上的实验表明,在多个评估指标中,IRW 的性能明显优于比较方法
概念及模型
IRW内部有两个主要模块:encoder和decoder。Encoder采用CNN和Bi-GRU模型来编码图像特征以及学习图像流的上下文信息。Decoder由三部分组成,分别是想象模块、推理模块以及写作模块,最后输出一个连贯的、信息丰富的并且具有想象力的故事。
decoder具体由三部分构成:
•Multimodal Imagining Module:生成一个富有想象力的故事情节•Relational reasoning module:充分利用外部常识 KG 和任务特定知识(场景图和事件图),并学习讲故事的互补语义特征•Story generation module:设计了具有引导单元的故事生成模块。
模型整体框架如下:

•图像编码器
首先使用预训练的resnet-152编码器,对输入的M个图像进行编码,然后使用Bi-GRU对M个图像编码再次编码得到输出,表达式如下。

•多模态想象模块
如果只基于图像特征选出图像中主要的内容,不同图像之间很难具有连贯性。所以在该模块中,通过将每个图像内容与之前生成的句子进行融合共同推断当前图像的主要内容。如下所示:
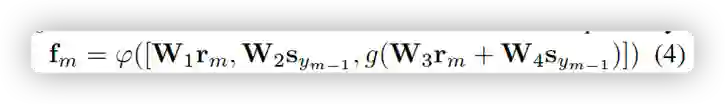
我们使用 GRU 通过为图像流中的每个图像生成一个想象的概念来生成一个 story line。以多模态融合向量 fm 作为输入,GRU 在时间步 m 的隐藏状态计算如下:

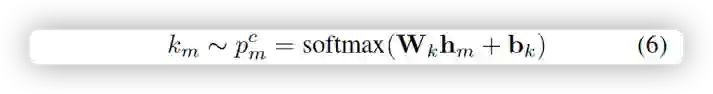
•关系推理模块
该模块会在story line上充分利用常识知识图谱和任务特定的知识。我们利用常识知识图(KG)来获得与想象概念相对应的支持知识。在上一步得到每个图片的关键概念后,可以在知识图谱中进行实体提及检测,找到top-L个候选的关系,然后就可以建立一个子图
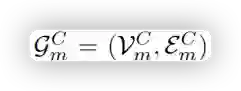
•场景图
生成旨在将图像自动映射为结构化的图表示,这需要检测图像中的显着对象及其关系。首次使用faster-rcnn作为目标检测器,然后计算动态树结构,将目标编码为用于预测每个对象对之间关系的视觉上下文。

•事件图
我们开发了一种检索增强方法,通过详尽地计算查询图像和训练图像之间的余弦相似度,从训练集中为图像流中的每个图像检索前 R 个视觉相似的图像。然后,将检索到的相似图像的描述语句连接起来形成一个引导故事,并利用它来构建事件图。具体来说,我们应用斯坦福开放 IE 方法为每个句子提取一个事件。每个事件都可以表示为一个关系三元组 (e1, r, e2),其中 e1 是主体实体,e2 是客体实体,r 是 e1 和 e2 之间的关系。在获得图像 Im 的所有事件后,我们提取在事件集 D 中具有代表性的共识事件。特别是,我们首先计算 D 中每个事件 di 和另一个事件 d 之间的语义相似度:
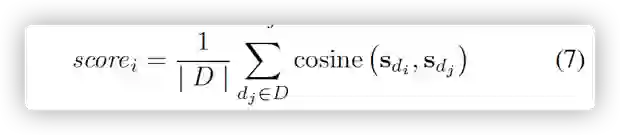
•图上的关系推理:
以上的三种图的推理方式都是一样的,以事件图上的推理为例。给定一个(vEm,i, eEm,ij , vEm,j )三元组,首先转换成对应的编码形式(vEm,i, eEm,ij , vEm,j ),应用GCN网络去整合邻居节点的信息,流程如下所示:
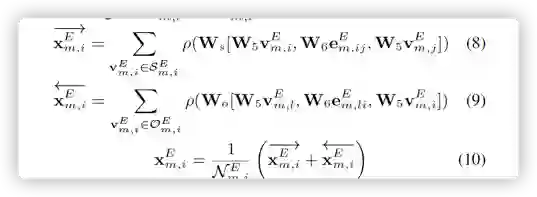
使用之前产生的文本以及图像的关键内容生成注意力机制有选择的选事件图谱中的节点从而生成整体事件图向量。

然后把得到的向量与事件图的图像进行融合,在常识知识图谱上再进行推理。如下所示。
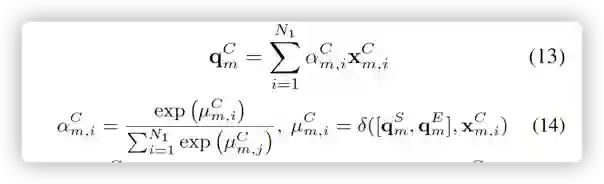
最后把三个图上推理的结果进行融合。
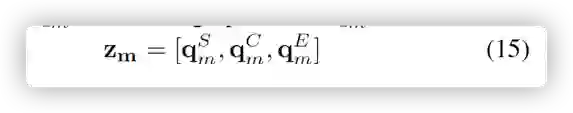
•生成故事模块 首先使用之前的隐藏层和关系推理对知识图进行注意力提取,如下图所示
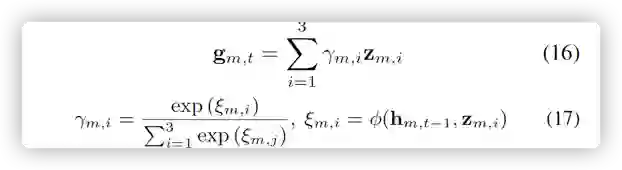
然后与图像的关键内容融合产生语义线索向量。
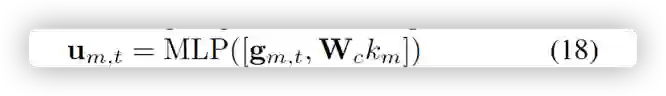
然后,为了基于先前生成的单词自动整合视觉线索向量 rm 和语义线索向量 um,t ,我们提出了一个引导单元(gate),通过深度整合视觉线索向量 rm 和语义向量 um 来生成故事。
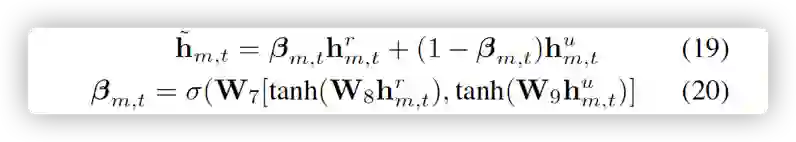
最后生成每个单词的概率

实验
作者使用了一个数据集VIST进行实验
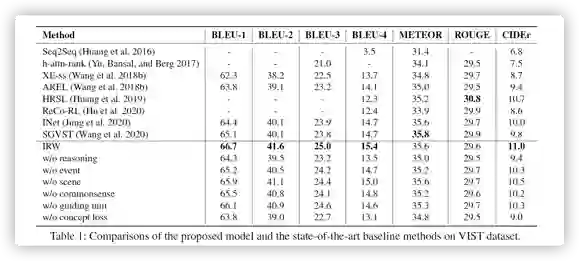
我们观察到 IRW 模型在大多数自动评估措施上的性能明显优于最先进的方法。具体来说,我们的 IRW 模型在 BLEU-4 和 CIDEr 上相对于现有最佳分数分别提高了 4.8% 和 3.7%。此外,我们的模型也大大优于 AREL、HRSL 和 ReCo-RL 方法,这些方法都采用强化学习范式来优化模型。通过部署强化学习可以进一步提高 IRW 的性能。
总结
在本文中,我们提出了一种新颖的想象-推理-编写生成框架 (IRW),用于视觉叙事,其灵感来自人类编写故事时的逻辑。我们利用想象模块来学习富有想象力的故事情节,这可以提高生成故事的连贯性和合理性。然后,我们提出了一个推理模块,通过关系推理方法充分利用外部常识知识和任务特定知识(场景图和事件图)。通过这种方式,可以大大增强所生成故事的多样性和信息量。最后,我们设计了一个引导单元来整合视觉和语义知识以生成类人故事。对基准数据集的大量实验表明,与强基线相比,IRW 取得了有竞争力的结果。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


