

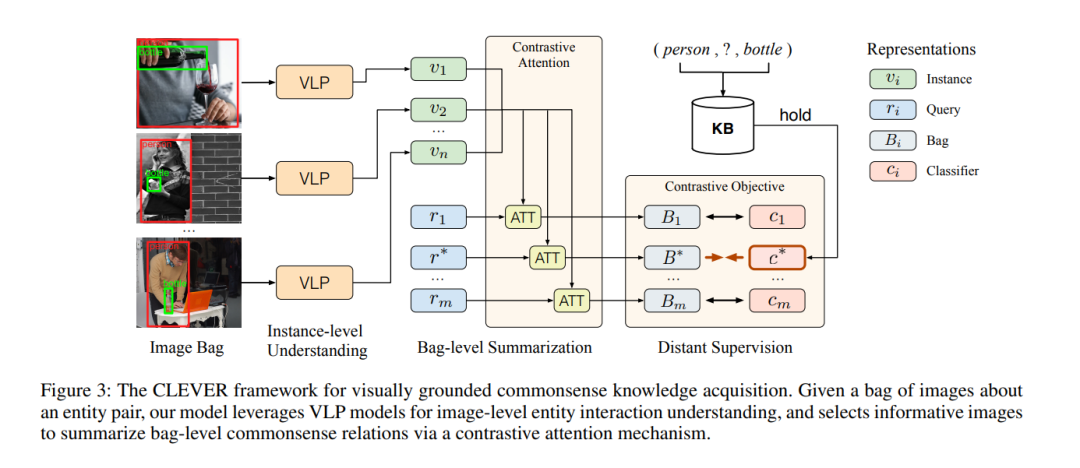
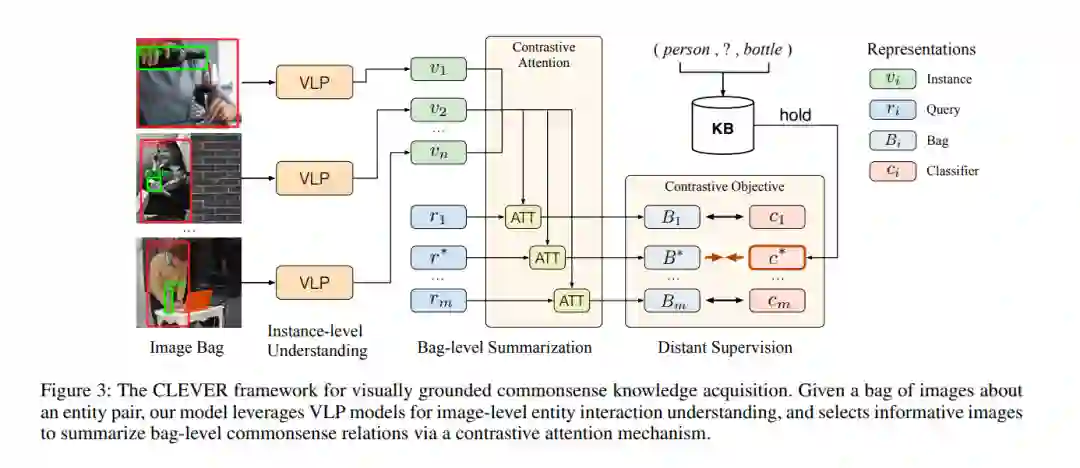
大规模的常识知识库为广泛的AI应用提供了能力,其中常识知识的自动提取(CKE)是一个基本和具有挑战性的问题。文本中的CKE因其固有的稀疏性和文本中常识的报道偏差而闻名。另一方面,视觉感知包含了丰富的关于现实世界实体的常识知识,如(人、能拿的东西、瓶子),这可以作为获得基础常识知识的有前途的来源。在这项工作中,我们提出CLEVER,它将CKE描述为一个远端监督的多实例学习问题,其中模型学习从一组关于实体对的图像中总结常识关系,而不需要对图像实例进行任何人为注释。为了解决这一问题,CLEVER利用视觉语言预训练模型来深入理解袋子中的每个图像,并从袋子中选择信息实例,通过一种新颖的对比注意力机制来总结常识性的实体关系。综合实验结果表明,CLEVER方法能够较好地提取常识性知识,比基于语言模型的预训练方法提高了3.9个AUC点和6.4个mAUC点。预测的常识得分与人的判断具有较强的相关性,斯皮尔曼系数为0.78。此外,提取出来的常识也可以根植于具有合理解释性的图像中。数据和代码可以在https://github.com/thunlp/CLEVER上获取。
https://www.zhuanzhi.ai/paper/24c2b507f246485d8b6f213169db5438
成为VIP会员查看完整内容

相关内容
Arxiv
16+阅读 · 2019年12月16日
Arxiv
15+阅读 · 2018年5月24日
相关VIP内容
相关资讯