论文浅尝 - ISWC2021 | 当知识图谱遇上零样本视觉问答
论文题目:Zero-shot Visual Question Answering using Knowledge Graph
本文作者:陈卓(浙江大学)、陈矫彦(牛津大学)、耿玉霞(浙江大学)、Jeff Z. Pan(爱丁堡大学)、苑宗港(华为)、陈华钧(浙江大学)
发表会议:ISWC 2021
论文链接:https://arxiv.org/pdf/2107.05348.pdf
代码链接:https://github.com/China-UK-ZSL/ZS-F-VQA
欢迎转载,转载请注明出处

引言
一、前言
我们生活在一个多模态的世界中。视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知。作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题。从15年首次被提出至今,其涉及的方法从最开始的联合编码,到双线性融合,注意力机制,组合模型,场景图,再到引入外部知识,进行知识推理,以及使用图网络,多模态预训练语言模型…近年来发展迅速。18年Qi Wu等首先提出引入外部知识的KB-VQA问题(FVQA[1]),贡献领域重要数据集(每个问题的回答必须依赖图片以外知识)的同时提出了一种基于知识子图生成并构建查询语句(SPARQL)的方法来解决该问题。以其为代表的后来一系列pipeline模式模型,流程繁琐部署困难的同时还面临着误差传递的风险。传统端到端方法,尽管某种程度上避免了误差传递,但大多将VQA作为分类任务,这使得其无法对超出候选答案以外(out-of-vocabulary, OOV)的结果进行预测,也即我们提到的零样本学习(Zero-shot Learning, ZSL)。
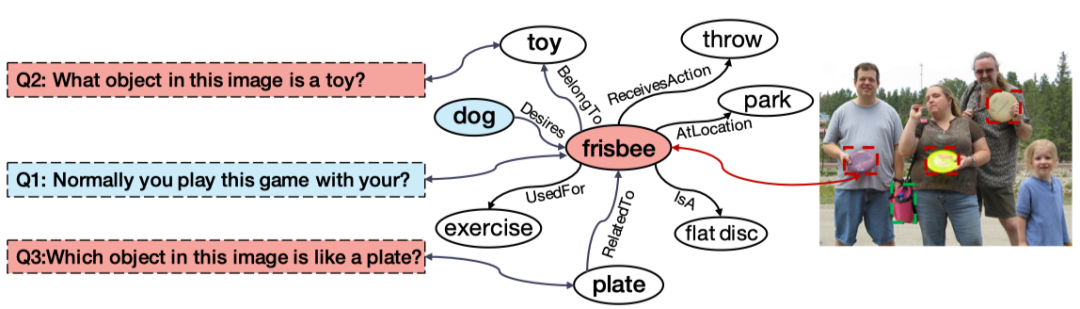
人天生就具有强大的领域迁移能力,且这种能力往往不需要很多的样本,甚至仅需一些规则描述,根据过往的经验与知识就可以迅速适应一个新的领域,并对新概念进行认知。基于此假设,我们设计零样本下的外部知识VQA:测试集答案与训练集的答案没有重叠。即,在原有F-VQA数据集基础上,提供以Seen / Unseen答案类别为划分依据的ZS-F-VQA数据集,并提出了一种适用于零样本视觉问答(ZS-VQA)的基于知识图谱的掩码机制。区别于传统VQA基于分类器的模型设定,我们采取基于空间映射的方法,建立多个特征空间并进行知识分解,同时提出了一种灵活的可作用于任何模型的k mask设定,缓解少样本情况下对于Seen类数据的领域漂移。我们的方法提供了一种多模态数据和KG交互的新思路,实验证明在多个模型上可取得稳定的提升,更好地结合外部知识同时缓解误差传播对于模型性能的影响。
二、数据集
由于长尾效应的存在,大多VQA数据存在答案不全/不均衡的特点(e.g. person、dog 等高频答案的出现概率可能是towel、rail等低频答案的数十乃至上百倍),这导致部分概念因为出现次数少而无法被很好地学习,甚至根本就没有被学习(尽管真实场景下,其依然存在被问到的可能)。
我们考虑极端的情况——零样本。即将原始数据根据答案类型,划分为训练/测试集的两个分布。具体来说,我们首先将F-VQA数据集的训练/测试集进行融合,然后统计出现概率TOP500的答案类型(answer class),按照Seen answer和Unseen answer随机划分为250 / 250的比例。此过程重复五次得到5个不同的子集以消除随机划分带来的误差影响。ZS-F-VQA划分统计结果与F-VQA对比如下:
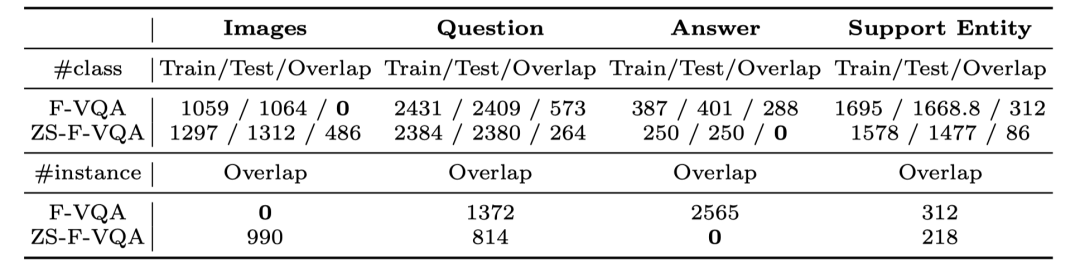
注意到,原始F-VQA是根据图片进行数据划分的,因此在image上的重叠(overlap)是0,而ZS-F-VQA在answer上重叠为0。
三、方法
方法包含两部分。
第一部分,我们提出三个特征空间以处理不同分布的信息:实体空间(Object Space)、语义空间(Semantic Space)、知识空间(Knowledge Space)的概念。其中:
-
实体空间主要处理图像/文本中存在的重点实体与知识库中存在实例的对齐; -
语义空间关注视觉/语言的交互模态中蕴含的语义信息,其目的是让知识库中对应关系的表示在独立空间中进行特征逼近。 -
知识空间让 (问题,图像)组成的pair与答案直接对齐,建模的是间接知识,旨在挖掘多模态融合向量中存在的(潜层)知识。
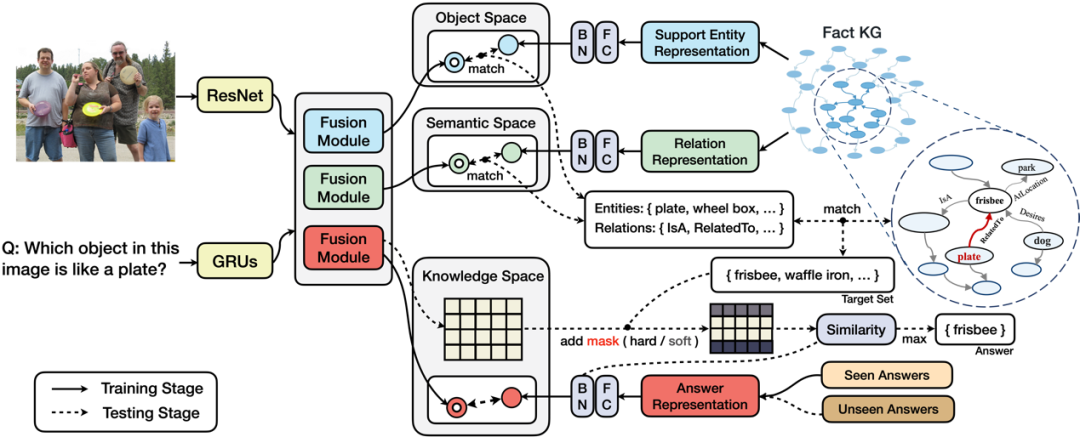
第二部分是基于知识的答案掩码。
掩码技术技术广泛应用于预训练语言模型(PLM),其在训练阶段遮掩输入的片段,以自监督的方式学习语法语义。与这种方式不同,我们在输出阶段进行答案遮掩:给定输入图像/文本信息得到融合向量后,基于第一部分独立映射的特征空间和给定的超参数Ke / Kr,根据空间距离相似度在实体/语义空间中得到关于实体/关系的映射集,结合知识库三元组信息匹配得到答案候选集。答案候选集作为掩码的依据,在知识空间搜索得到的模糊答案的基础上进行掩码处理,最后进行答案排序。
此处的掩码类型的分为两种:硬掩码(hard mask)和软掩码(soft mask),主要作用于答案的判定分数(score),区别在于遮掩分数的多少。其作用场景分别为零样本场景和普通场景。零样本背景下领域偏移问题严重,硬掩码约束某种意义上对于答案命中效果的提升远大于丢失正确答案所带来的误差。而普通场景下过高的约束则容易导致较多的信息丢失,收益小于损失。
具体实验和讨论见原文。
四、实验
标准F-VQA上的实验效果:
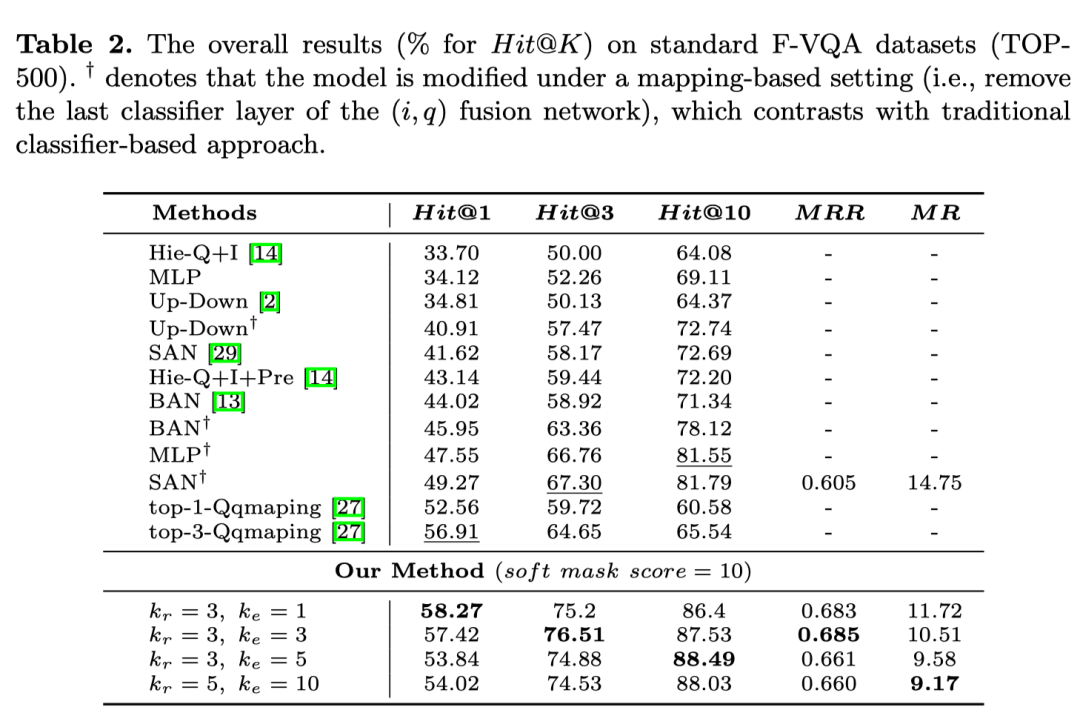
可以看到,取不同的超参k值,相比于其他baseline方法,最多可以取得( 6 ∼ 9% )的稳定提升。而在零样本设定中,ZS-F-VQA数据集下的实验结果如图所示:
模型所取得的提升是十分显著( 30 ∼ 40% )的。
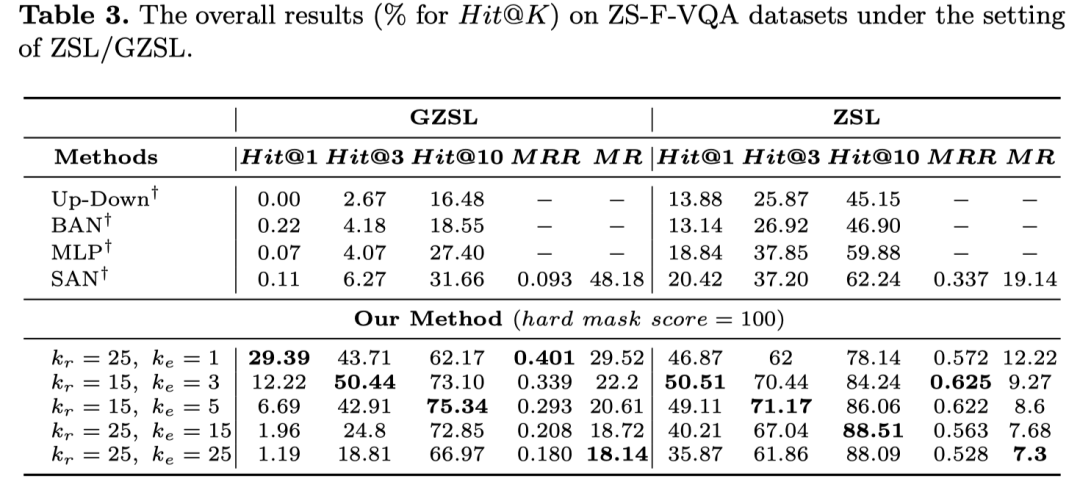
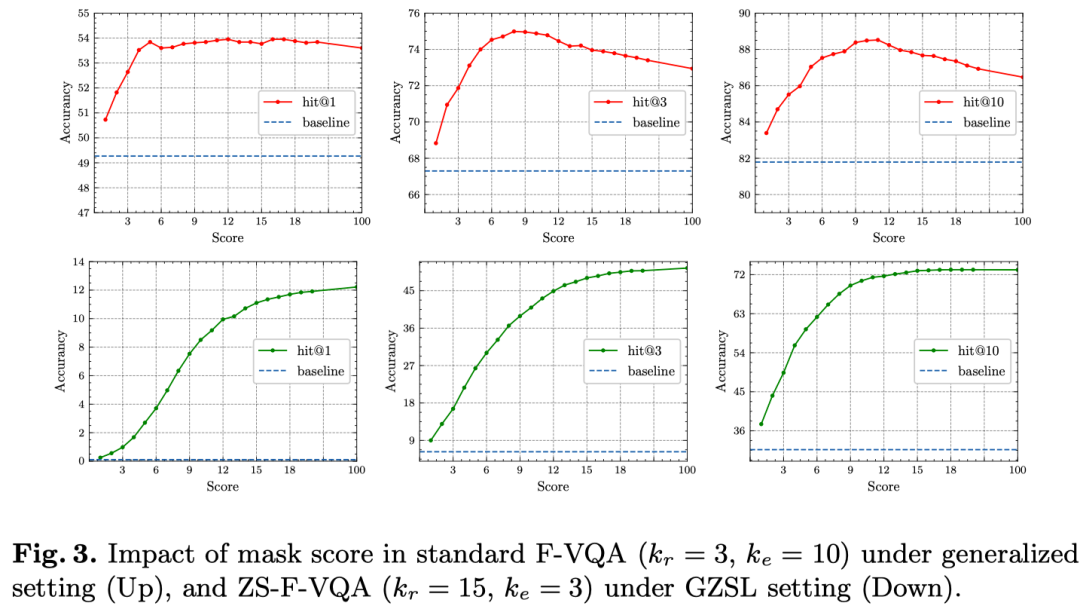
同时,ZS-F-VQA数据下hard mask 取得最佳效果,F-VQA数据下soft mask在不同的掩码分值取值(soft mask)下取得最佳效果,证明hard mask和soft mask的设定是有必要的。
最后,我们也对模型在两个数据集上的结果进行了可解释性分析。

五、总结
现有的模型默认训练集与测试集具有独立同分布的特质,但现实往往不尽如人意,也就是说同分布的假设大概率要打破。正如三位图灵奖大佬最近发表的文章Deep Learning for AI [2]中所强调的核心概念——高层次认知。将现在已经学习的知识或技能重新组合,重构成为新的知识体系,随之也重新构建出了一个新的假想世界(如在月球上开车),这种能力是人类天生就被赋予了的,在因果论中,被称作“反事实”能力。现有的统计学习系统仅仅停留在因果关系之梯的第一层,即观察,观察特征与标签之间的关联,而无法做到更高层次的事情。
这也是我们研究的出发点:零样本领域如何合理利用已有知识?我们普遍认为见过的就是事实,而未见过的就是事实以外的错误(反事实),这显然过于绝对。零样本某种意义上,就可看成是反事实的一种特例。
在未来,这其中显然还有更多可以挖掘的可能。
欢迎大家关注我们近期的在零样本学习领域的其他工作 [3-5]!
[1] Wang, P., Wu, Q., Shen, C., et al.: FVQA: fact-based visual question answering. TPAMI (2018)
[2] https://cacm.acm.org/magazines/2021/7/253464-deep-learning-for-ai/fulltext
[3] Geng Y, Chen J, Chen Z, et al. OntoZSL: Ontology-enhanced Zero-shot Learning. WWW 2021
[4] Chen J, Geng Y, Chen Z, et al. Knowledge-aware Zero-Shot Learning: Survey and Perspective[J]. IJCAI. 2021
[5] Geng Y, Chen J, Chen Z, et al. K-ZSL: Resources for Knowledge-driven Zero-shot Learning[J]. arXiv, 2021.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




