论文浅尝 | KM-BART:用于视觉常识生成的知识增强多模态BART
笔记整理:陈子强,天津大学硕士

动机
视觉语言模型早期集中在纯理解任务(例如,VQA视觉问答),尽管在理解任务上取得了先进的性能,却很少关注多模态生成任务。当前的预训练任务例如,掩码语言模型(MLM)和掩码区域模型(MRM)使得模型能够在视觉和语言特征之间建立对齐,这种特征对齐无法提高模型的多模态常识推理能力。
亮点
KM-BART的亮点主要包括:
1.作者扩展了BART模型来处理图像和文本的多模态数据,并通过引入任务相关标记来实现多模态推理。;2.为了提高视觉常识生成(VCG)模型的性能,作者通过设计一个新的预训练任务,将外部知识图中的常识知识隐式地融入到KM-BART中,我们称之为基于知识的常识生成(KCG)。3.除了KCG,作者还为KMBART加入了标准的预训练任务,包括掩码语言建模(MLM)、掩码区域建模(MRM)以及归因预测(AP)和关系预测(RP)。实验结果表明,所有的预训练任务都是有效的,结合这些预训练任务, KMBART能够在VCG任务上达到最先进的性能。
模型及预训练任务
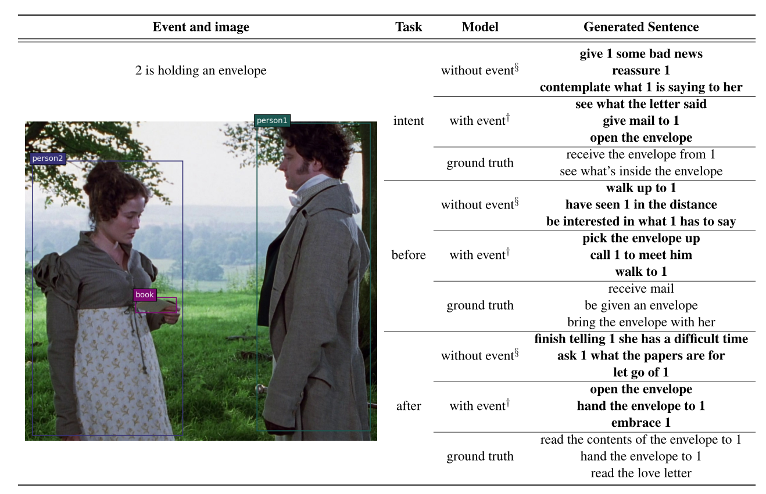
视觉常识生成(VCG)是给定图片和文本(event),生成图片中人物之前会发生什么(before),任务当前的意图(intent),以及之后会发生什么(after)。下图是一个例子:
KM-BART是一种基于Transformer的序列到序列自编码器。作者通过修改原始的BART使模型适用于图像和文本的跨模态输入。通过添加了一些特殊的token使得模型适用于不同的预训练和评估任务。
KM-BART由三部分构成:
•Visual Feature Extractor:通过Masked R-CNN提取图像不同区域特征和每个区域的标签p(v_i )•Cross-Modal Encoder:引入特殊token表示当前任务的类型。对于基于知识的常识生成任务,使用<before>,<after>或者<intent>作为起始标志。对于属性和关系预测任务使用。对于掩码语言任务和掩码区域任务使用<caption>。用<img>和</img>表示图像输入的开始和结束,<event>和</event>表示事件的开始和结束,<mlm>和</mlm>表示文本的开始和结束。•Decoder:自回归的解码器,不将视觉表示当做输入,使用的表示来替换视觉表示。对于掩码语言任务和掩码区域任务使用<cls>代替被掩码的区域或者单词。
模型整体框架如下:
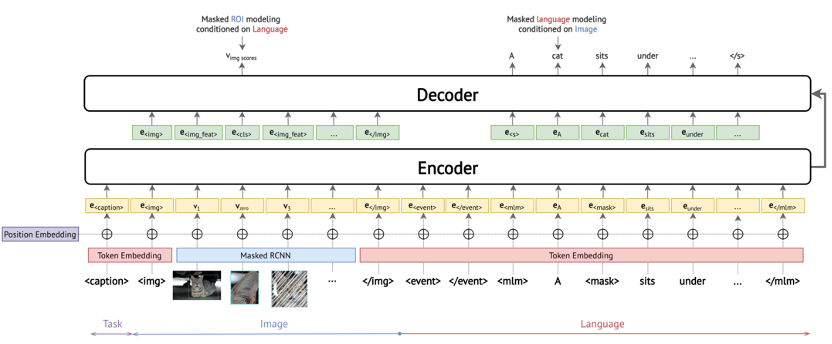
KM-BART有五个预训练任务:
•基于知识的常识生成(Knowledge-Based Commonsense Generation)
作者从COMET中引入外部知识。COMET是在外部常识知识图谱上预训练的大型语言模型。给定一个自然语言短语和一个关系作为输入,COMET生成自然语言短语作为常识描述。将COMET中xIntent和xWant的预测结果视为intent,将COMET中的xNeed的预测结果视为before,将COMET的预测结果视为after。作者通过这种方式,并对数据进行筛选,从而扩充了预训练数据集。
对于扩充的数据集,为了筛选到合理的数据,作者对数据进行了过滤。首先将BART模型在VCG数据集上进行微调,此时模KM-BART已经取得了不错的效果。这时将COMET生成的数据,输入网络计算交叉熵,取小于阈值(文中3.5)的数据进行保留。
在扩充后的数据集上进行常识生成,损失函数如下:
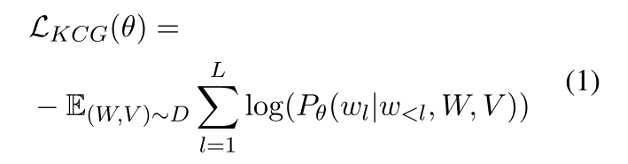
W和V表示输入的图像和文本,L表示句子长度。
•属性预测(Attribute Prediction)&关系预测(Relation Prediction)
由于预训练的Visual Genome数据集存在230万个关系和280万个属性,为了充分利用这个数据集,作者构建了属性预测和关系预测两个预训练任务。可以使得模型学到图像中不同区域之间的内在属性。
在属性预测任务中,将图像特征的解码器输出向量输入到MLP分类器中,计算交叉熵损失。在关系预测任务中,将图像特征两两拼接,输入到MLP分类器中计算交叉熵损失。
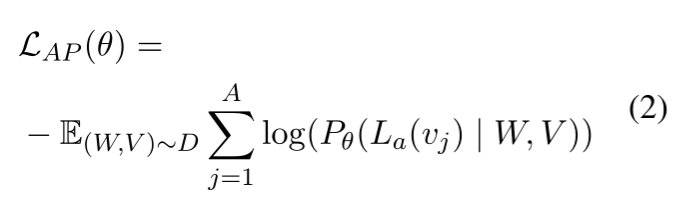
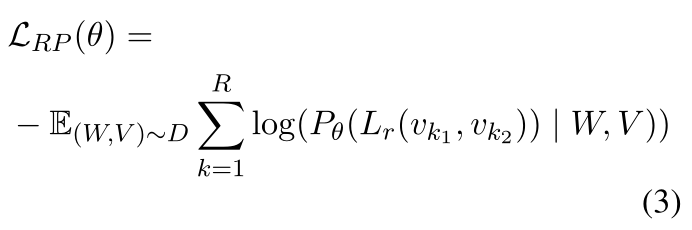
•掩码语言建模(Masked Language Modeling)
与BERT中类似,以15%的概率随机掩码一些文本单词。在被掩码的单词中80%概率用代替,10%的概率随机替换,10%的概率不变。希望让模型预测出这些被掩码的单词。损失函数如下:
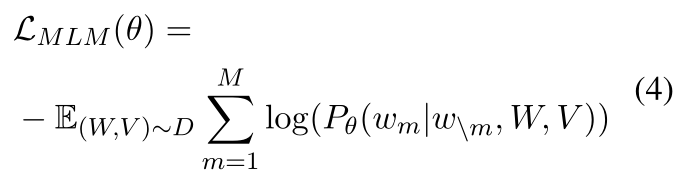
•掩码区域建模(Masked Region Modeling)
以15%的概率掩码图像区域,即用0向量填充图像。模型需要预测被掩码的区域所属的类别分别。损失函数是最小化输出分布和在视觉特征提取中得到的区域标签概率分布之间的KL散度,公式如下:
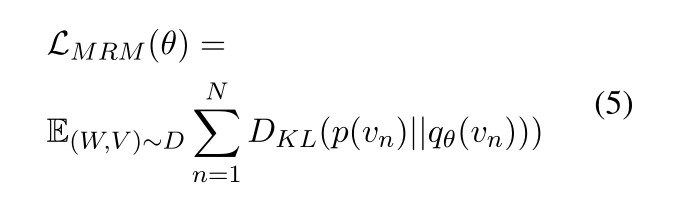
实验
文章将模型架构固定为6层编码器和6层解码器。消融实验的设置如下:(1)不进行预训练(2)只进行KCG预训练任务,同时比较数据过滤前后的模型性能(3)只进行AP和RP任务(4)只进行MLM和MRM任务(5)所有的预训练任务都加上。消融实验结果如下:
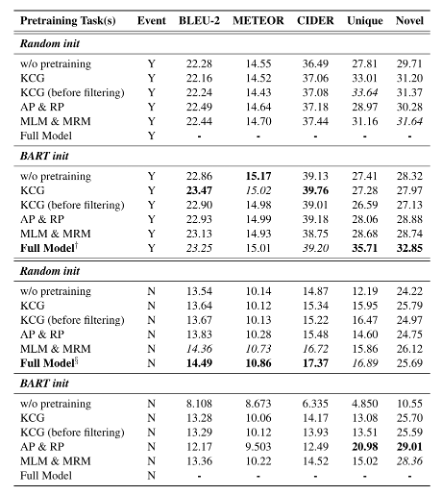
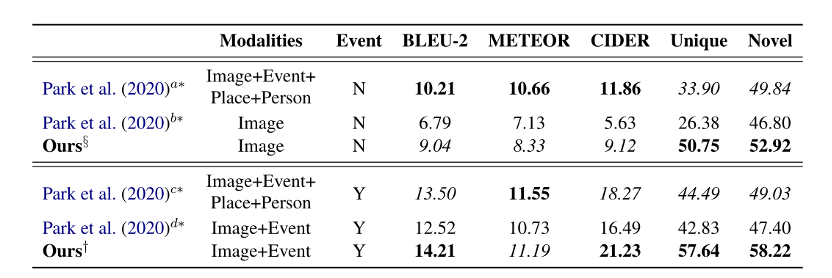
VCG数据集包括了117.4万个训练样本和14.6个测试样本。评价指标为BLEU-2,METEOR,CIDER。此外也计算量了,Unique和Novel指标。Unique即生成的推理句子占比,Novel即训练数据中不存在的句子占比。对比实验如下:
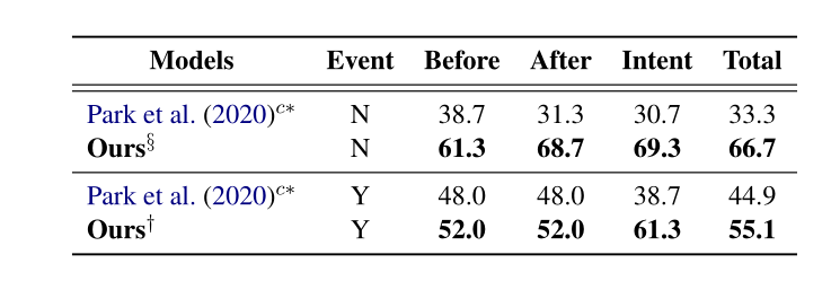
作者同时进行了人工评估,即抽取若干生成的常识,人工选取合理的结果。最后统计baseline和KM-BART的占比。实验结果如下:
总结
文章提出了知识增强的多模态BART (KM-BART ),这是一个基于Transformer的模型,能够从图像和文本的跨模态输入中推理和生成常识描述。同时提出了基于知识的常识生成的预训练任务,该任务通过利用在外部常识知识图上预训练的大型语言模型来提高KM-BART的推理能力。作者使用自我训练来过滤自动生成的常识性描述。在VCG任务上的实验结果表明,KM-BART在预训练任务上达到了最佳性能。进一步的人工评估表明,KM-BART可以产生高质量的常识推理。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

