论文浅尝 | 弱监督下极简的视觉语言预训练模型

笔记整理:黄雨峰,浙江大学硕士,研究方向为知识图谱表示学习、多模态。
论文引用:Wang Z, Yu J, Yu A W, et al. Simvlm: Simple visual language model pretraining with weak supervision[J]. arXiv preprint arXiv:2108.10904, 2021.
1. Motivation
现阶段,很多模型[如LXMERT等]将图像区域特征回归的对象检测或标记作为预训练目标的一部分。需要用到fast RCNN等检测模型,训练集也需要大量标注,因此成本很高,模型的可扩展性也会降低。有研究提出利用多种跨模态损失函数作为训练目标的一部分,如图像-文本匹配等。这些函数经常与图像标注生成、MLM等其它目标形成复合预训练损失,导致不同损失和数据集之间难以平衡。
视觉语言预训练,学习两种模态的联合表示,然后在视觉语言基准数据集上微调。为了捕获图像和文本之间的对齐,以前的方法利用了多个类型的模态的标记数据集,使VLP的预训练复杂,对于模型的性能有一定的瓶颈。这种基于预训练-微调的方法通常缺乏zero-shot的泛化学习能力。而自回归语言模型(GPT-3)展现了强大的性能,并且没有进行微调,表明文本引导的zero-shot泛化是一个很有前途的方案。
作者希望的VLP模型具有如下优点:可以无缝地插入到预训练-微调范式中,并在标准VL基准数据集上实现比较好的性能;不像以前的方法那样需要一个复杂的预训练目标;在跨模态设置中具有文本引导的zero-shot泛化的能力。
因此,全新的图像-文本预训练模型SimVLM与现有的VLP模型的区别:
(1)只使用了单一的预训练损失,是当前最简化的VLP模型
(2)只使用了弱监督,极大地降低了对预训练数据的要求
(3)使生成模型具备了极强的零样本能力,包含零样本跨模态迁移和开放式视觉问答(VQA)
2. Mothed
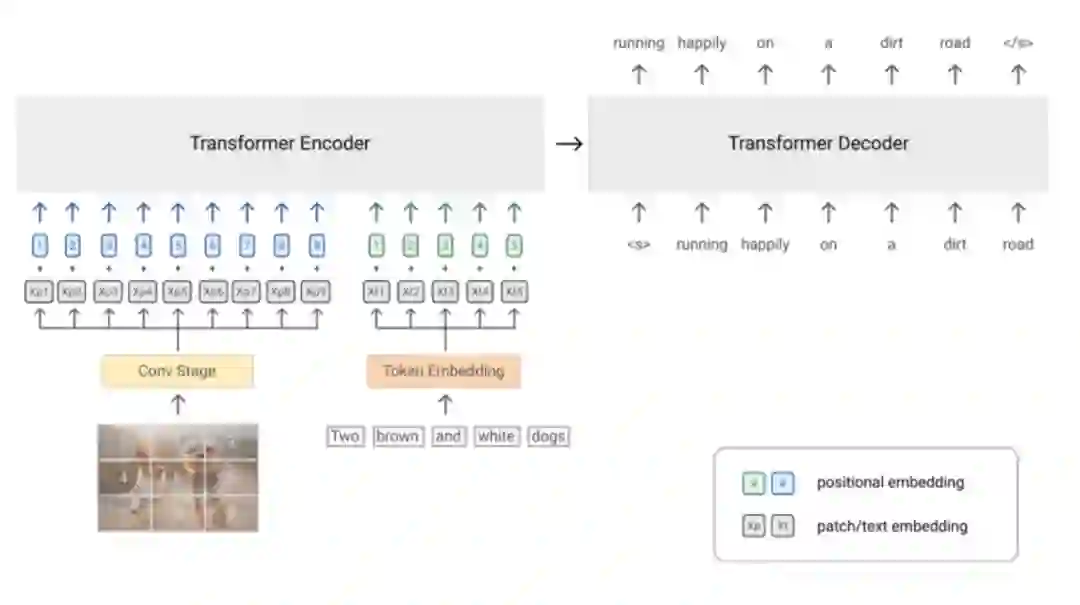
2.1 Objective
它使用前缀语言建模(PrefixLM)的单一目标,进行端到端训练。它不仅可以像GPT-3那样自然地执行文本生成,而且还可以像BERT那样以双向的方式处理上下文信息。
PrefixLM不同于标准的LM,它允许对前缀序列进行双向注意,并且只对剩余的token进行单向的注意。在预训练过程中,随机选择长度为Tp的token的前缀序列从输入序列中截断。
图像可以被视为其文本描述的前缀。因此,对于给定的图像-文本对,作者将一定长度的图像特征序列置于文本序列之前,并强制模型对长度为Tp的前缀进行采样,来计算文本数据的LM损失。
它采用了ViT/CoAtNet的结构,直接将原始图像作为输入。这样的模型也适合大规模的数据,并很容易与PrefixLM目标兼容。
对于视觉模态,作者将图片分成了多个patch,然后flatten成一维序列(这一步就类似视觉Transformer的预处理)。
对于文本模态,作者使用可学习的embed层将单词进行embedding。
为了保留位置信息,作者分别为图像和文本输入添加了两个可训练的一维位置编码向量,并另外为Transformer层内的图像patch添加了二维相对注意力。
这些设置减轻了目标检测的需求,并允许模型利用大规模的弱标记数据集,作者使用大规模的带噪声的图像-文本数据从头开始对所有模型参数进行预训练这对zero-shot泛化有更好的效果。
3. Experiment
3.1 数据集、基线、评估指标
3.1.1 数据集
在pretrained的部分,作者对图像文本和仅文本输入两种类型的数据进行预训练。对于联合视觉和语言数据,利用了ALIGN数据集(包含大约1.8B个有噪声的图像-文本对)。对于仅文本的数据集,采用了 Colossal Clean Crawled Corpus (C4)数据集。总共包含4,096 image-text pairs (ALIGN) and 512 text-only documents (C4)。
在finetune的部分,模型在六个视觉语言基准上进行了微调和评估,包括三个区别性任务:VQA v2、SNLI-VE和NLVR2;以及三个生成任务:CoCo Caption,NoCaps和Multi30k。同时作者还研究了它的zero-shot泛化和在单模态任务上的性能。
为了检验视觉语言预训练的质量,我们首先将SimVLM与最先进的(SOTA) VLP方法(包括LXMERT、VL-T5、UNITER、OSCAR、Villa、SOHO、UNIMO和VinVL)在流行的多模态任务上进行比较。
3.2 实验结果
3.2.1 主实验结果
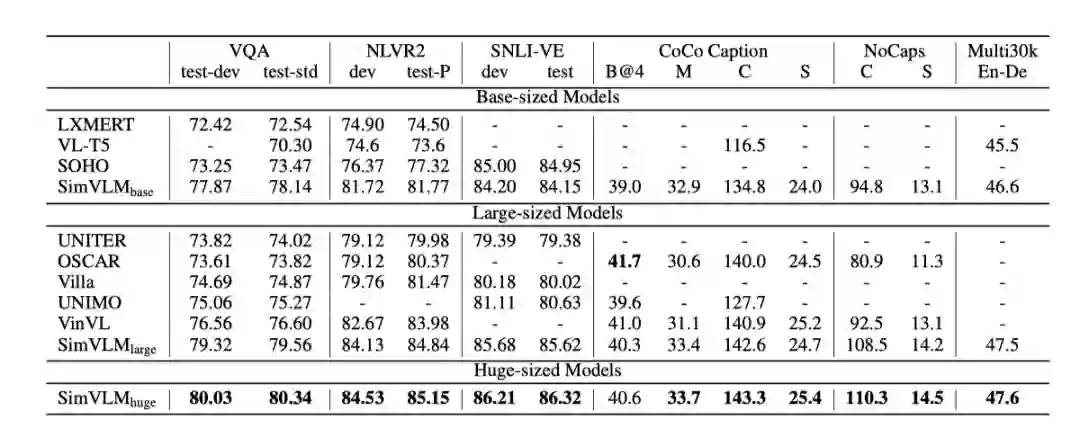
对于判别任务,SimVLM在使用更少容量的情况下已经超过了之前所有的方法,SimVLM-huge相比之前的SOTA (VinVL)获得了近4分的绝对分数提升,使VQA上的单模型性能首次超过80%。此外,SimVLM在NLVR2和SNLI-VE上的性能也始终优于先前的方法,说明它处理更复杂的视觉-语言推理的能力。
对于包括图像标题和图像转换在内的生成任务,SimVLM还使用原始的微调技术进行了很大的改进。在CoCo字幕的公开“Karpathy”5k测试分割以及NoCaps基准测试中,我们的模型在4个指标中的3个优于使用更复杂的CIDEr优化强化学习方法训练的之前的方法。最后,SimVLM对于Multi30k从英语到德语的图像翻译也是有效的。
这些实验表明,模型可以无缝地插入到训练前微调范式中,使用极简的训练和微调程序,具有卓越的性能。
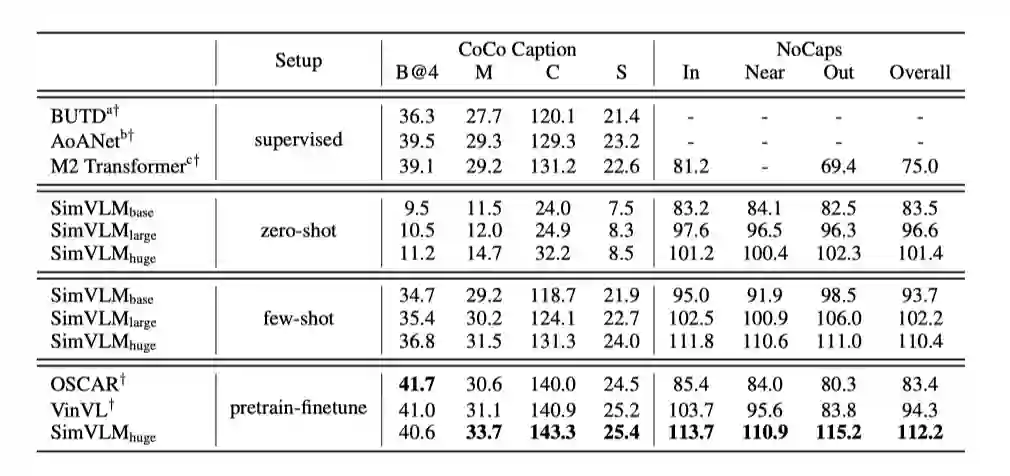
3.2.2 Zero-Shot Image Caption
3.2.3 Zero-Shot Cross-Modality Transfer
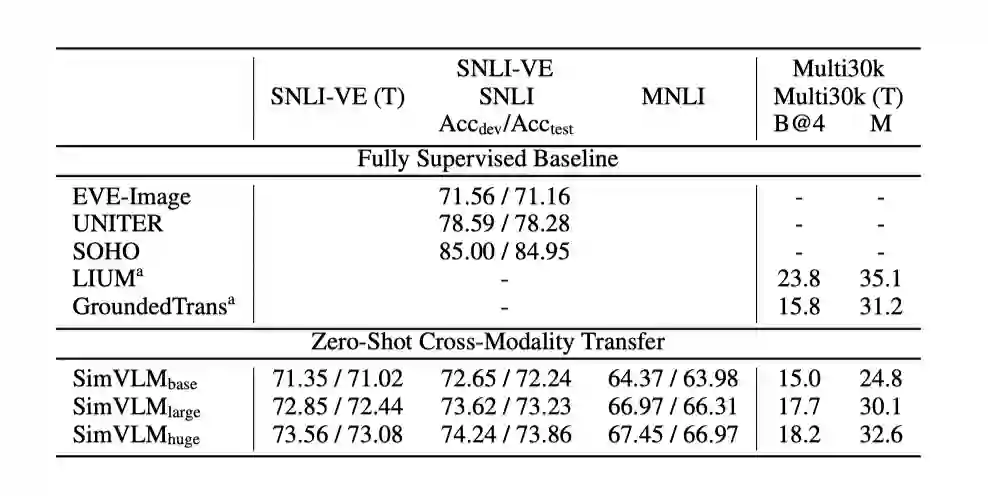

从实验结果和case分析中我们可以看出,模型可以达到不错的实验效果,还能生成德语描述,同时实现跨语言和跨模态转移。
3.2.4 Zero-Shot VQA
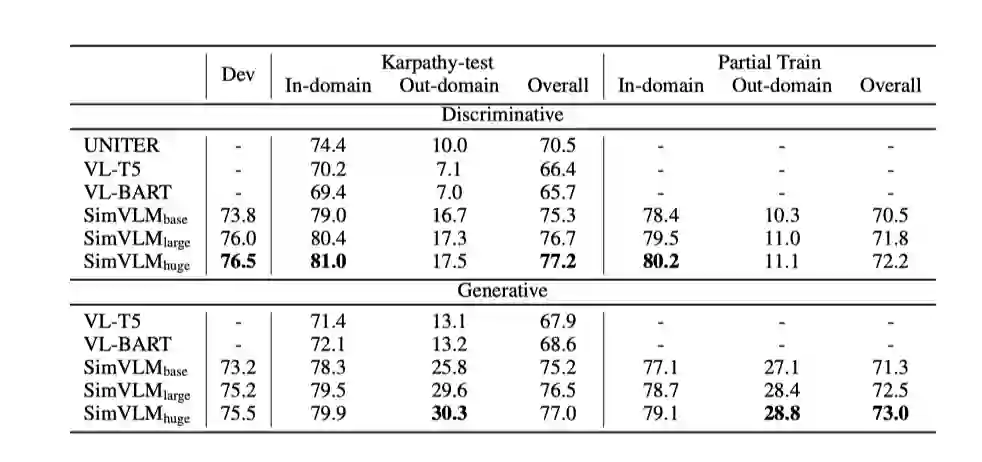

从实验结果和case分析可以看出,SimVLM的在zero-shot VQA任务上相比其他预训练模型也表现出更加强大的性能。
在这项工作中,作者提出了一个简单而有效的视觉语言预训练框架。与以往使用目标检测和多个辅助损失的工作不同,我们的模型将整个图像作为patch处理,并使用单个前缀语言建模目标进行端到端训练。
该模型优于现有的VLP模型,并在6个VL基准测试上实现了SOTA性能,而无需额外的数据或任务特定的设置。此外,它在视觉语言理解中获得了更强的泛化性能,支持zero-shot图像字幕和开放式VQA。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


