五分钟教你在Go-Bigger中设计自己的游戏AI智能体

多智能体对抗作为决策AI中重要的部分,也是强化学习领域的难题之一。
为丰富多智能体对抗环境,OpenDILab(开源决策智能平台)开源了一款趣味多智能体对抗竞技游戏环境——Go-Bigger。同时,Go-Bigger还可作为强化学习环境协助多智能体决策AI研究。
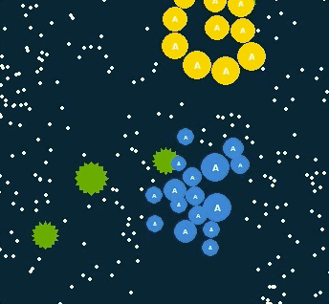
与风靡全球的agar.io、球球大作战等游戏类似,在Go-Bigger中,玩家(AI)控制地图中的一个或多个圆形球,通过吃食物球和其他比玩家球小的单位来尽可能获得更多重量,并需避免被更大的球吃掉。每个玩家开始仅有一个球,当球达到足够大时,玩家可使其分裂、吐孢子或融合,和同伴完美配合来输出博弈策略,并通过AI技术来操控智能体由小到大地进化,凭借对团队中多智能体的策略控制来吃掉尽可能多的敌人,从而让己方变得更强大并获得最终胜利。

Go-Bigger游戏环境演示图
DI
四类小球,挑战不同决策路径



孢子球
食物球


DI
团队紧密配合,实现合理重量传递
DI
支持RL环境,提供三种交互模式


可视化演示

DI
三步走,快速搭建强化学习baseline
步骤1:环境瘦身

人类视角的Go-Bigger

游戏引擎中的结构化信息
原始的游戏数据需要表达游戏内容,其数值范围波动便会较大(比如从几十到几万的球体大小),直接将这样的信息输入给神经网络会造成训练的不稳定,所以需要根据信息的具体特征进行一定的处理(比如归一化,离散化,取对数坐标等等)。
对于类别信息等特征,不能直接用原始的数值作为输入,常见的做法是将这样的信息进行独热编码,映射到一个两两之间距离相等的表示空间。

对于坐标等信息,使用绝对坐标会带来一些映射关系的不一致问题,相对坐标通常是更好的解决方式。






步骤2:基础算法选择
多模态观察空间:图像信息 + 单位属性信息 + 全局信息
离散动作空间:16维离散动作
奖励函数:稠密的奖励函数,且取值已经处理到[-1, 1]
终止状态:并无真正意义上的终止状态,仅限制比赛的最长时间


步骤3:定制训练流程

使用更高级的自我对战(Self-Play)算法(比如保存智能体的中间历史版本,或使用PFSP算法)
构建League Training流程,不同队伍使用不同的策略,不断进化博弈
设计基于规则的辅助机器人参与到训练中,帮助智能体发现弱点,学习新技能,可作为预训练的标签或League Training中的对手,也可构造蒸馏训练方法的老师,请玩家尽情脑洞
# 几个有意思的发现