

摘要
以全数字化、人工智能辅助指挥和控制以及使用无人系统为特征的未来战争场景,将对作战行动的节奏产生巨大影响。因此,他们将使军事决策周期面临更大的时间压力。建模和仿真与先进的人工智能技术相结合,将成为未来决策支持系统的关键推动力。这些系统将支持军事决策者评估威胁以及为自己的部队制定和评估最佳行动方案。 AI 研究公司在民用领域的最新进展,例如 DeepMind 的 AlphaStar,已将先进的深度强化学习技术应用于星际争霸 II 等热门游戏,以训练 RL 智能体制定击败对手的卓越策略。
本文介绍了德国陆军概念与能力发展中心和空中客车公司进行的一项研究的结果。该研究的目的是评估如何调整和使用上述机器学习技术来训练能够在战斗模拟(“ReLeGSim”)中充当营长的 RL 智能体。在此模拟的每个时间步中,RL 智能体可以向可用的单位发送命令或请求多域火力支援。 “ReLeGSim”在单个平台级别模拟每个连/单位和火力支援要素的行为和战斗损耗。然后它将反馈(所谓的奖励)返回给 RL 智能体,以评估和改进其在训练周期中的行为。也可以选择多个训练有素的 RL 智能体,让它们在联盟系统中相互对抗,以进一步改进它们。
经过这样的训练,RL 智能体可以应用于实际场景。由此产生的战略可以作为决策周期中可能的行动方案,并向营指挥官提出。
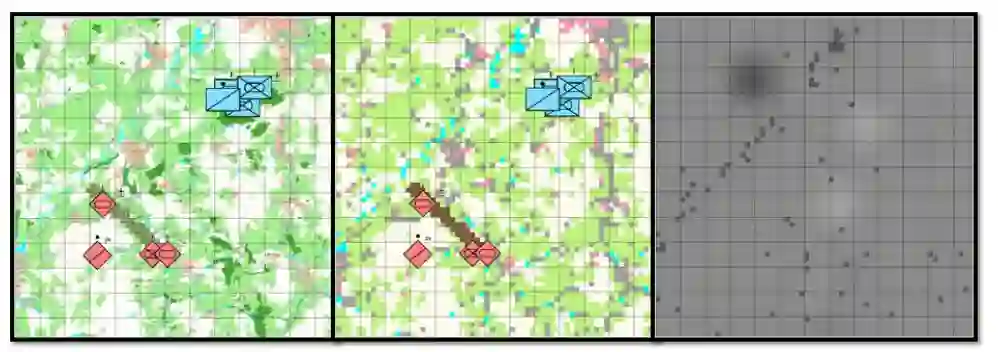
图 3-1:ReLeGSim 光栅化过程。开放街道地图(左)、栅格化地形(中)、高程模型(右)
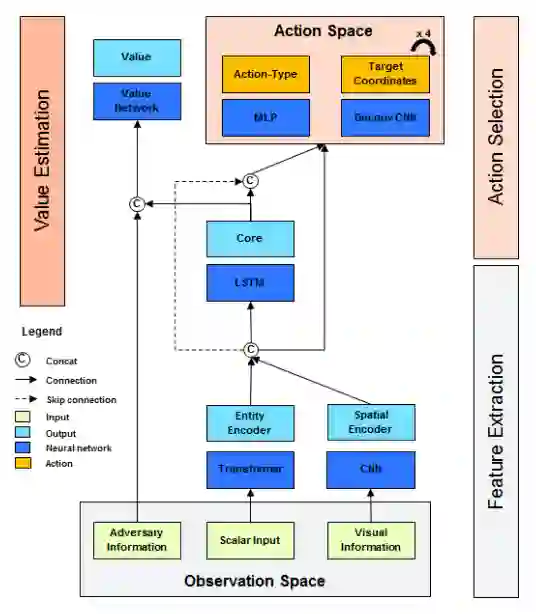
图3-2:ReLeGs AI架构

图4-2:CNN自动编码器/解码器《战争迷雾》
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年4月17日

相关VIP内容
相关资讯