CVPR2020:基于元学习的泛化人脸识别

【摘要】人脸识别模型通常需要部署在未知的场景中,识别未知的人群,这对模型的泛化性能带来了极大挑战。为解决该技术难题,自动化所郭建珠博士、朱翔昱副研究员和雷震研究员等人构建了基于元学习的泛化人脸识别框架,通过使模型学习跨场景的元知识,提升模型在未知场景下的泛化性。相关成果被CVPR2020录用为Oral论文。
近些年得益于深度学习的发展,人脸识别性能在一些通用测试集上得到了极大提升,然而这些测试集与训练集有着类似的数据分布。当识别模型部署在实际场景中时,由于目标场景与训练集数据分布不一致,模型的性能会显著下降。并且目标场景通常是未知的,数据亦不可获取,无法使用目标场景的数据对模型进行微调。针对这个挑战,研究团队提出了泛化人脸识别问题:在目标场景未知的条件下,如何设计一个有效的训练策略或方法,让模型能在未知场景下取得较好的泛化性,如图1所示。
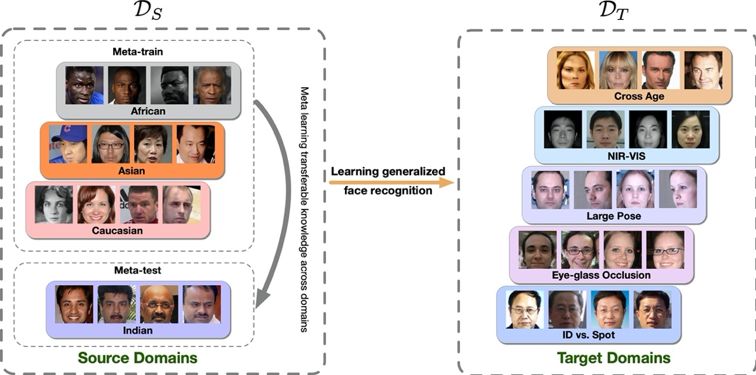
图1. 泛化人脸识别
针对泛化人脸识别问题,团队提出了一种基于元学习的人脸识别框架MFR(Meta Face Recognition)。MFR主要包括三部分:
(1)跨域采样;(2)多域分布优化;
(3)元优化
整体的框架如图2所示。

图2. MFR框架
首先,跨域采样是为了模拟训练场景和测试场景的分布偏差,每次迭代时,根据训练集的域标签,将训练集分为元训练域和元测试域,并在两个域中分别采样一定人数。
其次,在多域分布优化中,团队使用了三种损失函数,包括难样本损失、软分类损失和域对齐损失,来学习具有判别性和域不变性的人脸表征。
最后,元优化通过三个步骤对模型进行优化:
元训练:对元训练域进行优化,并得到梯度更新后的模型参数;
元测试:在元测试域上,对元训练更新后的模型参数进行二次更新;
对元优化和元测试的损失进行加权,对原始模型的参数进行梯度反传更新。
元优化的示意图如图3所示。
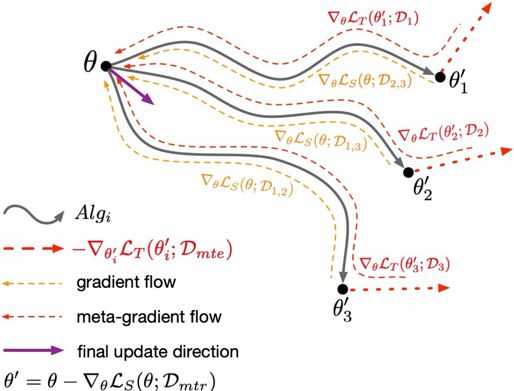
图3. 元优化
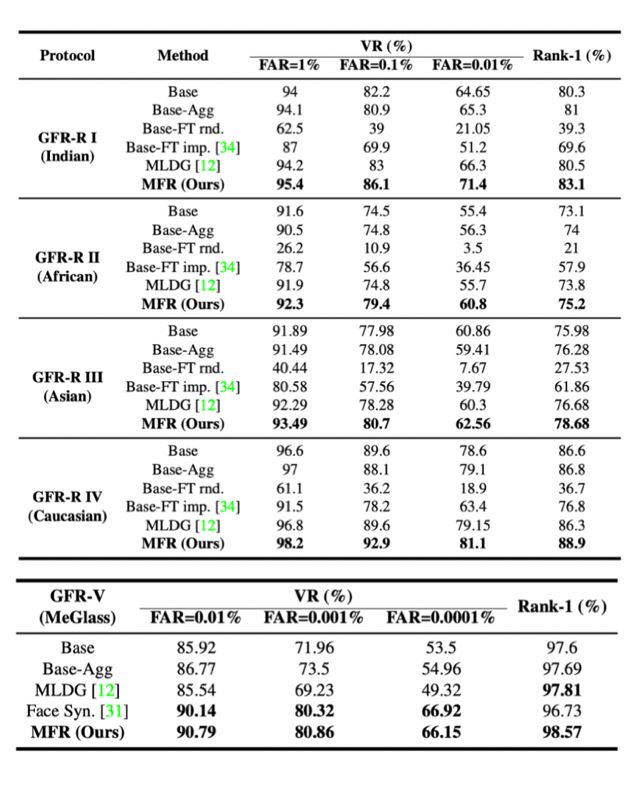
为了验证模型的泛化性,团队提出了两个不同难度的测试协议,如表1所示。一个是跨种族(印度人、非洲人、亚洲人,高加索人)测试协议GFR-R;另一个是跨场景测试协议GFR-V,其更接近实际场景,也更具挑战性。在协议中,目标域的数据在训练中是未知的,用于模拟未知的应用场景。通过表2可以看出,通过元学习,本方法在跨种族和跨场景的测试中均取得了最好的性能。
表1. GFR-R跨人种测试协议和GFR-V跨域测试协议
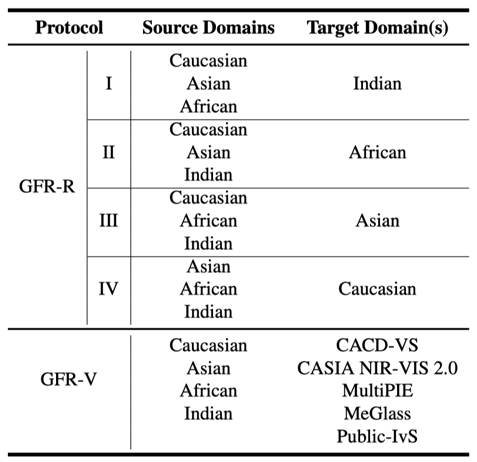
表2. GFR-R跨人种测试协议和GFR-V跨域测试协议结果。
https://arxiv.org/abs/2003.07733
(也可点击下方阅读原文进入)
生物识别与安全技术研究中心(CBSR)在人脸识别领域一直走在世界前列。中心发表过百余篇人脸识别相关国际论文,计算机视觉、人脸识别著作10部,在计算机视觉和人脸识别核心技术竞赛中10多次夺冠。设计了世界上第一个大型边检通关系统,在深圳-香港边检运行至今。设计实施了世界上第一个人脸识别人证票核验系统,在2008北京奥运实施。代表中国制定人脸识别ISO国际标准,制定了人脸识别中国国家标准、行业标准10多项。团队发布的CASIA-Webface人脸数据库成为人脸识别领域研究使用最广泛的数据库之一。






