全面超越BN/GN/LN/IN!归一化新方法BGN,解决因Batch Size大小带来的训练不稳定问题

极市导读
本文介绍了一篇在不增加新训练参数和引入额外计算的情况下,通过引入通道、高度和宽度维度来补偿,解决批量标准化(BGN)在小/超大Batch下BN的噪声/混淆统计计算问题的文章,作者详细分析了BGN的方法以及实验过程及结果。 >>12月10日(周四)极市直播|汤凯华:利用因果分析解决通用的长尾分布问题

1 简介
深度卷积神经网络(DCNNs)训练起来既困难又耗时。规范化是一种有效的解决方案。在以往的归一化方法中,批处理归一化(BN)在大、中批量处理中表现良好,对多个视觉任务具有很好的通用性,但在小批量处理中,其性能下降明显。
作者实验发现在超大Batch下BN会出现饱和(比如,Batch为128),并提出在小/超大Batch下BN的退化/饱和是由噪声/混淆的统计计算引起的。因此,在不增加新训练参数和引入额外计算的情况下,通过引入通道、高度和宽度维度来补偿,解决了批量标准化(BGN)在小/超大Batch下BN的噪声/混淆统计计算问题。
利用GN中的组方法和超参数G来控制统计计算所使用的特征实例的数量,从而对不同批量提供既无噪声也不混淆的统计量。实验结果证明BGN优于BN、IN、LN、GN以及PN;

该方法在图像分类、神经结构搜索(NAS),对抗的学习,小样本学习以及无监督学习领域适应(UDA)都有很好的性能、鲁棒性。例如,在ImageNet上训练设置Batch=2进行训练ResNet-50,BN的Top1准确率为66.512%,BGN的Top1准确率为76.096%,精度有显著的提高。
2 相关工作总结
批处理归一化(BN)是早期提出的一种归一化方法,也是应用最为广泛的方法。BN利用计算出的均值和方差对特征图进行归一化,再对归一化后的特征图进行重新缩放和移位,以保证DCNN的表征能力。同时,在BN的基础上,提出了许多其他任务的归一化方法。
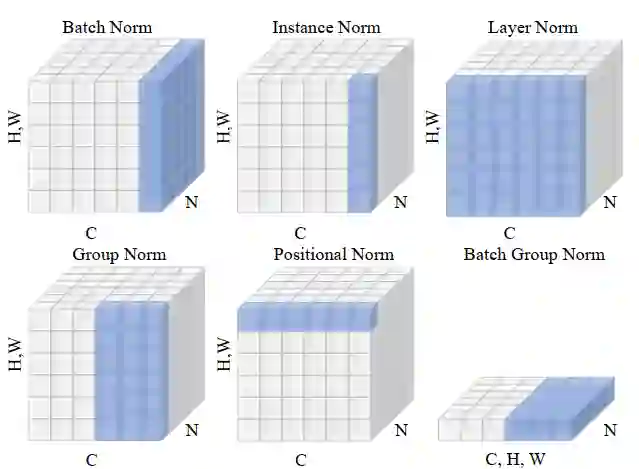
层归一化-LN:用于计算递归神经网络沿通道的统计量;
权值归一化-WN:来参数化权值向量,用于监督图像识别、生成建模和深度强化学习;
切分归一化-DN:提出包含BN和LN层的归一化层,作为图像分类、语言建模和超分辨率的特例;
实例归一化-IN:为了进一步快速风格化,提出了IN层,主要用于图像分割迁移,其中统计量由高度和宽度维度计算得到;
组归一化-GN:对通道进行分组,统计每个分组通道的高度和宽度,增强对批量大小的稳定性;
位置归一化-PN:提出了位置归一化算法来计算生成网络沿信道维数的统计量;
其他相关归一化的改进比如:
EvalNorm、
Moving Average BN、
Adaptive Normalization、
Square LN、
Decorrelated BN、
Spectral Normalization、
BatchInstance Normalization(BIN)、
Switchable Normalization(SN)、
Meta Normalization、
Kalman Normalization(KN)
等等,
这里不再赘述,感兴趣的朋友可以寻找相关论文进行研究。
在这些归一化方法中,BN通常可以在中、大批量中取得良好的性能。然而,在小批量它的性能便会下降比较多;GN在不同的Batch Size下具有较大的稳定性,而GN在中、大Batch Size下的性能略差于BN。其他归一化方法,包括IN、LN和PN在特定任务中表现良好,但在其他视觉任务中泛化性比较差。
批处理组标准化(BGN)是参数和计算效率高。我们都知道Mini-Batch训练通常可以执行比Single Batch和All Batch训练效果要好,Single Batch训练可以表输出嘈杂的梯度,而All Batch梯度训练可能不行(每个图像梯度和不同的方向,因此,添加都表明梯度混淆)。
受此启发,作者认为归一化统计计算中的特征实例数量也应该适中,即BN在小批/超大批上的性能下降/饱和是由于统计计算的噪声/混乱造成的。因此,BGN被提出,通过Group技术来提升Batch Size在BN在小/极端大的性能。这里BGN将通道、高度和宽度三个维度合并为一个新维度,将新维度划分为特征组,计算整个小批和特征组的统计量。
3 BGN方法
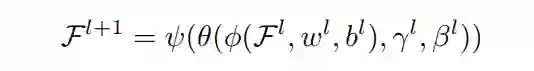
-
1)、将特征图划分为特征组; -
2)、计算各特征组的均值和方差统计量; -
3)、利用计算出的统计量对各特征组进行归一化; -
4)、对归一化特征图进行重新缩放和移位,保持DCNN的表示能力。
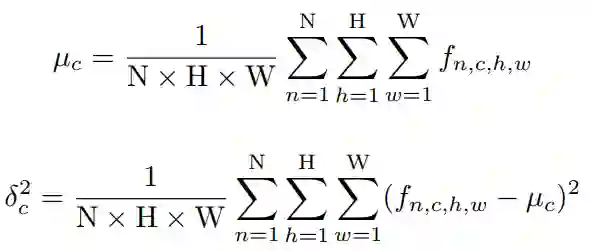
将Feature map归一化为:
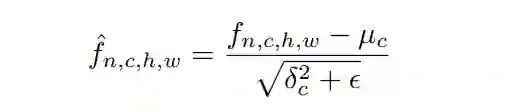
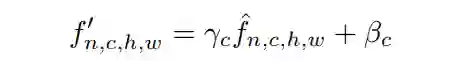
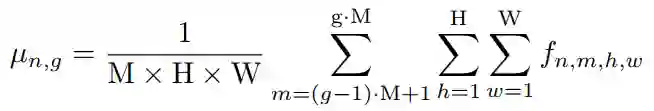
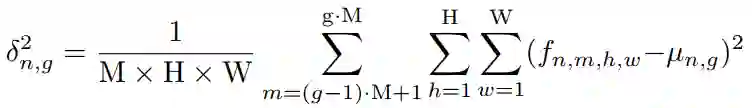
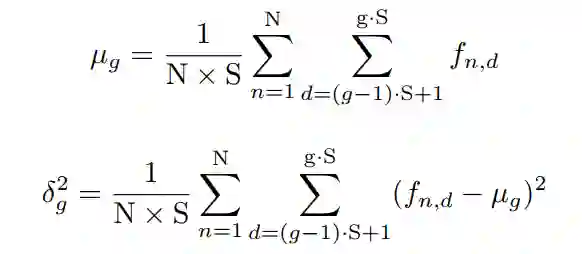
4. 实验
4.1、ImageNet上使用ResNet-50进行图像分类

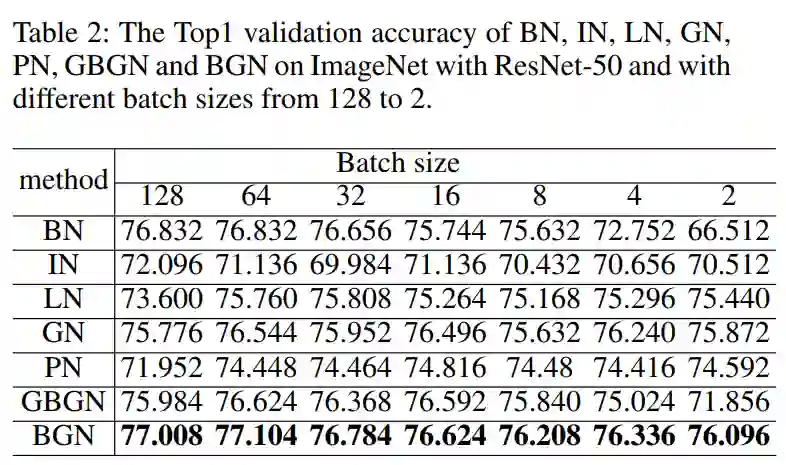
通过以上可以看到,所提出的BGN在不同批处理规模下的性能优于之前所有的方法,包括BN、IN、LN、GN、PN和GBGN。
具体来说,BN在大批量下接近BGN的性能,然而,它的性能在小批量下迅速下降。GBGN是针对小批量尺寸提出的,但在批量尺寸为2时,其性能比BGN低4.24%,说明引入整个通道、高度和宽度尺寸来补偿噪声统计计算的重要性。在ImageNet分类上总体表现不佳。
LN、GN和PN的平均Top1精度分别为75.191%、76.073%和74.167%,而提出的BGN的平均Top1精度更高,为76.594%。
4.2、利用NAS对CIFAR-10进行图像分类

通过上表可以看到IN和LN不收敛,而BGN显著优于GN和PN,同时也优于BN。

通过上表可以看到IN、LN和PN的收敛性不强,而BGN的性能明显优于GN,BGN的性能略逊于BN。
因此,在神经结构搜索阶段使用BN作为归一化层比较具有优势。
4.3、对抗性训练
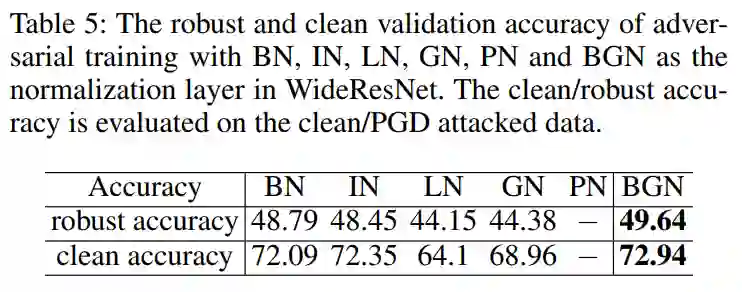
在对抗网络的训练中,Robust精度比Clean精度更重要。PN存在收敛困难,不能收敛。BGN在一定范围内优于BN和IN,显著优于LN和GN。
4.4、少样本学习

可以看到,BGN略优于BN,但显著优于IN、LN、GN和PN,说明BGN在标签数据非常有限的情况下具有普遍性。
4.5、Office-31无监督领域适应实验
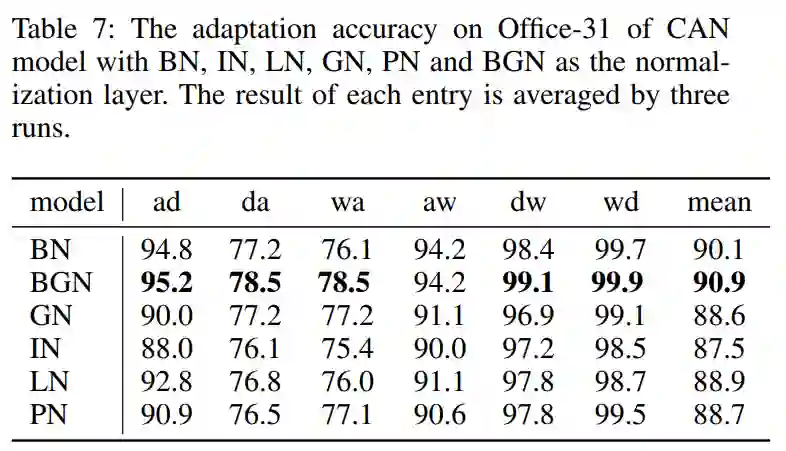
可以看到,BGN在大多数适应任务中优于其他归一化层,特别是wa,准确率提高了1.6%。
参考
推荐阅读




