韩松等人提出NN设计新思路:训练一次,全平台应用
选自arXiv
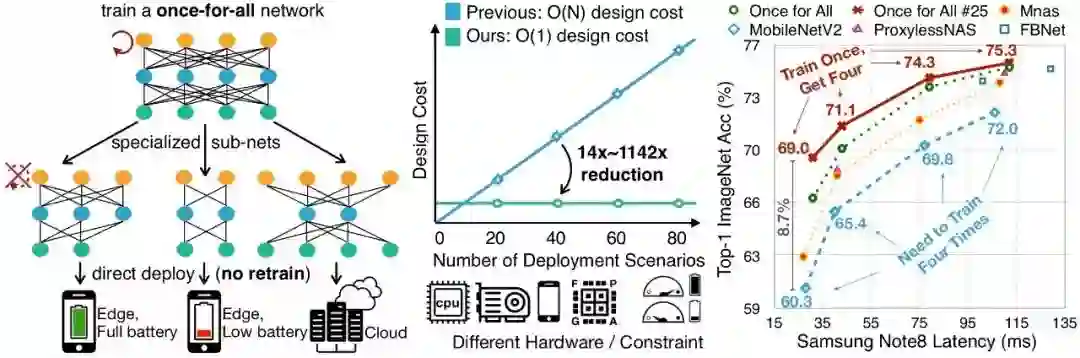
本文将介绍麻省理工学院与 MIT-IBM Watson AI Lab 的研究者提出的一种「一劳永逸」方法。通过分离模型训练与架构搜索过程,该方法能极大降低神经网络模型设计部署成本。

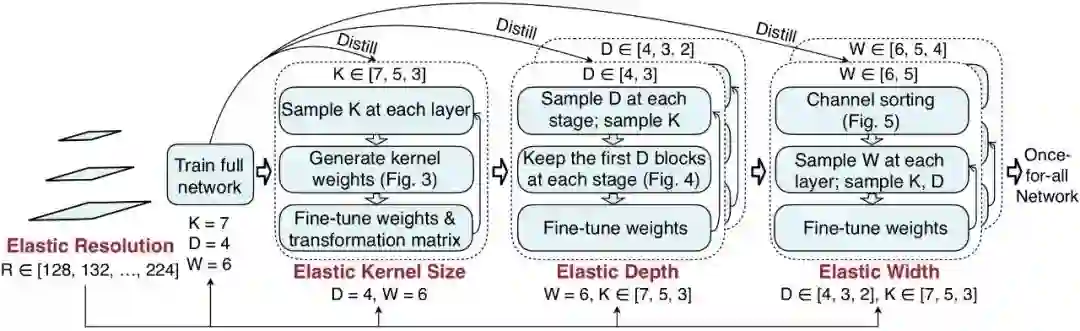
弹性分辨率(图 2)。为了支持弹性分辨率,研究者在训练模型时为每批训练数据采样了不同的图像大小。
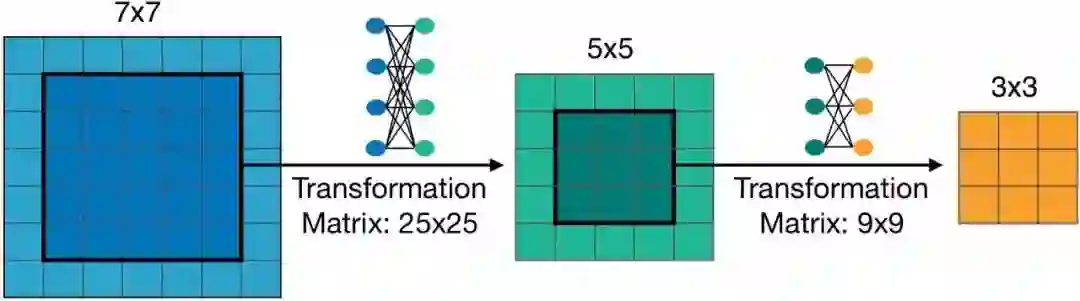
弹性核大小(图 3)。研究者在共享核权重时引入了核变换矩阵。具体而言,就是在不同的块上使用不同的核变换。在每个块中,核变换矩阵在不同的通道之间共享。
弹性深度(图 4)。为了在原本有 N 个块的阶段得到有 D 个块的子网络,首先保留前 D 个块,再跳过后面的 N-D 个块。最后,前 D 个块的权重在大型和小型模型之间共享。
弹性宽度(图 5)。宽度的意思是通道数量。研究者为每一层都提供了选择不同通道扩展比的灵活性。
知识蒸馏(图 2)。研究者既使用了训练数据给出的硬标签,也使用了在训练 OFA 网络时通过训练完整网络所得到的软标签。



登录查看更多
相关内容

Arxiv
7+阅读 · 2018年1月23日
Arxiv
3+阅读 · 2017年12月28日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年1月23日
Arxiv
3+阅读 · 2017年12月28日