【NeurIPS 2019】7篇自动化神经网络搜索(NAS)论文简读
【导读】Neural Architecture Search(NAS),即自动化神经网络搜索,虽然早被谷歌在2017 年提出,直到今年才大行其道,屡屡在顶会舞台亮相。笔者从刚刚公布的NuerIPS 2019 接收名单里,找出已经公开了论文的7 篇文章,根据发布时间排序,并做简短的解读。
作者:陈美济
学校:兰州大学
1.《自动化神经网络搜索用于深度主动学习》以色列理工学院
推荐指数:★★☆☆☆
Deep Active Learning with a NeuralArchitecture Search
https://arxiv.org/abs/1811.07579
简介:深度主动学习着力解决数据缺少标注的问题,主动从大量未标注的数据中检索已标注数据来进行训练。深度主动学习的潜力巨大,比如放射显影图像需要专业的医学诊断,这样的数据很难大规模标注。先前的研究中,针对特定任务,神经网络结构是固定的,主要聚焦于有效的检索机制。本文提出的主动学习策略是,在学习过程同时在线搜索神经网络结构,即结构随学习过程一起变化。作者对比了三种已知的检索方法(softmax 响应,蒙特卡洛dropout,及核心集合),加入NAS 之后效果远超固定网络结构的方法。
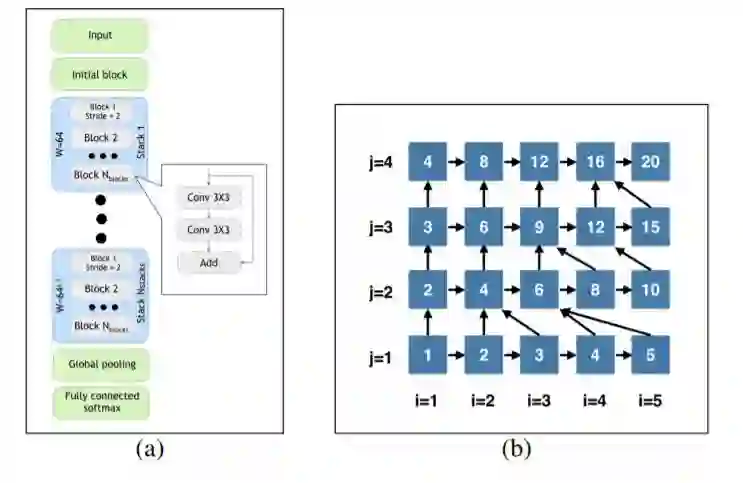
短评:本文将NAS 搜索和主动学习耦和,交叉进行,提升了现有主动学习的的水平,结合点比较好。但NAS 方法比较朴素,只用于这个特定任务和数据集。搜索空间是堆叠相同block 的方式,而block 用了ResNet 基本单元。可变部分是block 个数和stack 个数,空间比较有限。验证每个结构的能力用了early stopping,只训练了50 个epoch。
2.《DetNAS:目标检测主干网搜索》中科院,旷视
推荐指数:★★★★☆
DetNAS: Backbone Search for ObjectDetection
https://arxiv.org/abs/1903.10979
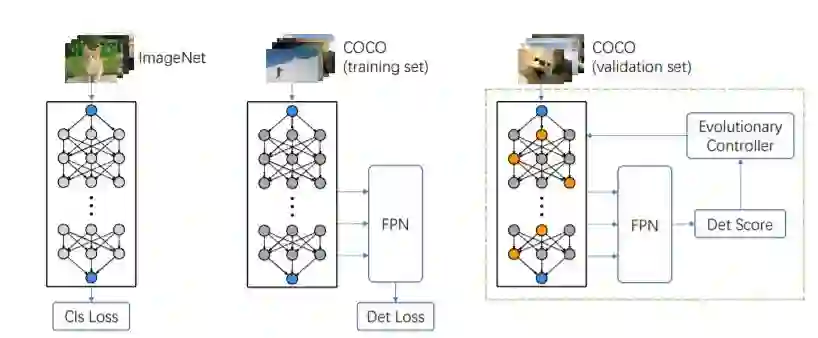
简介:目标检测一般使用分类的主干网,文章认为从分类迁移到检测可能是次优,所以提出设计直接服务于检测的网络。本文基于单次训练超网(one-shot supernet),提出检测主干网搜索方案:超网在ImageNet 上做预训练,检测任务上做精调,然后在训练后的超网中进行搜索,用检测任务作为评价指标。最后结果在COCO 数据集上以更少的FLOPs 超过了ResNet-50/101。可以看出,ImageNet 仍然是迁移能力很强的数据集。如果超网直接从COCO 来训练,结果是不是会更好呢?文章也做了对比实验,相同训练成本下,ImageNet 预训练还是占优。
短评:NAS 用于OD 是众望所归,本文是目标检测领域一篇NAS 力作,也是旷视先前工作SPOS 的延续。优点在于复用了给分类训练的超网,然后接入固定的检测后端FPN 在COCO上做精调训练。最后搜索过程用了主流方法之一演化算法,以COCO 为验证集来评估模型性能。虽然目前还是集中于主干网,但为以后主干和后端同时搜索奠定了基础。
3.《可变换结构搜索用于网络剪枝》悉尼科技大学,百度研究院
推荐指数:★★★☆☆
Network Pruning via TransformableArchitecture Search
https://arxiv.org/abs/1905.09717
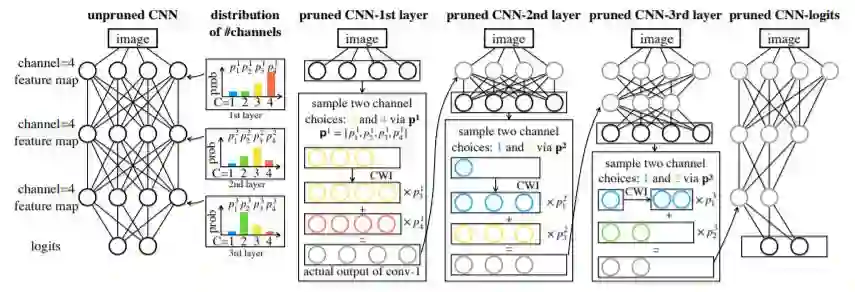
简介:剪枝可以降低网络的过参数化。原有方法限制了宽度和深度,有结构限制。本文引入NAS 以后摆脱了这种限制,可以有更灵活的通道数和深度。具体地,剪枝网络是抽样K 个网络的叠加,网络参数和抽样分布的概率随剪枝网络训练(最小化其loss)一起更新,概率最大的参数即为最后剪枝模型的通道数和层数。如果各抽样网络通道数不同时,采取插值方式补齐。实验数据集是CIFAR-10/100,ImageNet,结果超过现有剪枝方法。
短评:NAS 用于剪枝,也是个不错的点。本文NAS 师法DARTS,基本思想相同,待剪枝的网络相当于超网,结构和参数一起优化,最后找出概率最大的那支。不同之处在于结构参数在DARTS 中是各个op 的参数,此处是channel size。
4.《SpArSe:用于受限资源微控制器的稀疏网络结构搜索》ARM ML 研究院,普林斯顿大学
推荐指数:★★★☆☆
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
https://arxiv.org/abs/1905.12107
简介:广泛的IoT 设备使用微控制器MCU 作为运算单元,因为计算、存储、功耗资源的限制,神经网络模型需要做专门针对性的设计。本文将设计问题考虑为多目标优化过程(验证集精度、模型大小、内存占用),其中内存占用是根据输入和各层权重估算得到的。IoT 端内存有两个核心限制条件,模型参数量不能超过ROM 容量,中间层最大运算结果不能超过RAM 容量,本文对两个条件都做了相应的处理。另外搜索空间表示为DAG,允许灵活的深度、宽度和连接。卷积运算操作有普通卷积、可分离卷积、另外单独定义了深度降采样卷积。优化过程为贝叶斯方法(MOBO)。
短评:NAS 用于受限资源场景,为IoT 服务,是大趋势和方向。不止IoT 设备,移动端也是受限资源问题,所以使用多目标优化是很自然的。本文使用了贝叶斯方法(优化过程)、模型态射(morphism,用于最大程度地参数共享)、剪枝(非结构化剪枝用稀疏可变Dropout,结构化剪枝用贝叶斯压缩),和传统方法比结果也取得SOTA,属于在没有防空的领域,用NAS 完胜是合理的。
5. 《高效的前向结构搜索》卡耐基梅隆大学,微软研究院
推荐指数:★★★☆☆
Efficient Forward Architecture Search
https://arxiv.org/abs/1905.13360
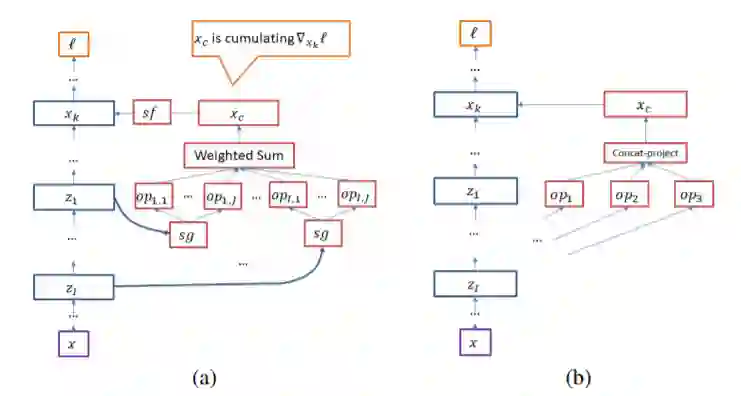
简介:本文提出叫做Petridish 的NAS 方法,对已有网络层上迭代式增加短连接,脱胎于集成学习中的梯度提升(Gradient boosting)。命名为“前向”是与固定搜索空间的逆推最优模型方法(比如DARTS )的“反向”以示区别。原先的NAS 选择不同的block,相当于选择不同的特征,本文方法是选择不同的层间连接和选择特征揉在一起,分别使用弱学习(weaking learning)和模型训练(model training)来解。所有可能的连接是加权在一起优化的,每一步选其中一个子集。文章还实验对比了主流的两种搜索空间下的表现,即相同cell 堆叠的SS,和更宏观的由不同block 组合的SS。实验数据集采用CIFAR-10 ,并迁移到ImageNet,但未达到NAS 模型的SOTA。
短评:灵活连接在权重共享型NAS 当中是个不好解决的问题,本文引入集成学习的方法做了有意义的尝试。但结果目前看还不太理想。文中坦承方法中最关键的点是分摊(amortization),即weak learning 和模型训练的成本有固定的比例。
6.《含专家经验的神经网络搜索》阿里巴巴集团
推荐指数:★★★☆☆
XNAS: Neural Architecture Search with Expert Advice
https://arxiv.org/abs/1906.08031
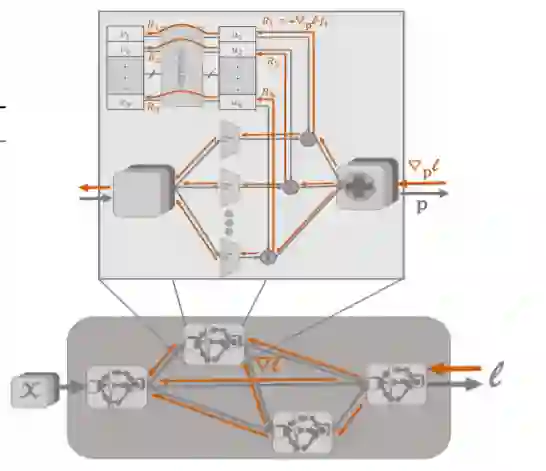
简介:本文将NAS 看作是持续学习中的选择任务。持续学习的主要思想是,世界(数据分布)一直在变,每次做得不要比平均水平差,和最好的专家相比有所差距,所谓后悔(regret)一点,这是当下知识和未知未来情形的差距,是必须要付的代价。学习目标是最小化reget ,其代表方法是PEA(用专家经验预测)。标题中X 指EXpert。具体地,将DARTS 的搜索空间看作是PEA 的选择空间,在优化过程中用专家经验(reward)对搜索空间做剪裁(清除弱的专家)从而提高稳定性,提升搜索效率。这里reward 的概念可以类比强化学习中的PG。
短评:本文是DARTS 和持续学习(online learning)的交叉应用,属于组合式创新。结合点新颖,效果也比较好,CIFAR-10 上达到1.6% 的错误率,同量级上比现有NAS 模型更优,在ImageNet 上5M 参数量模型也有76%,属于比较好的结果。
7. 《高效的用于目标检测的通道级神经网络搜索》中国科学院大学,商汤,智能感知与计算研究中心
推荐指数:★★★☆☆
Efficient Neural ArchitectureTransformation Search in Channel-Level for Object Detection
https://arxiv.org/abs/1909.02293
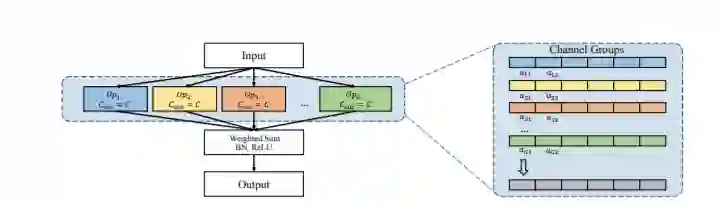
简介:本文提出叫做NATS 的方法,在复用现有分类网络模型结构和权重基础上,为目标检测做变形设计。主要利用空洞卷积dilation(dx,dy)的特性,在不改变权重的情况下,将普通卷积转化为多个不同channel 输出的子空洞卷积,最后在channel 层面做结构优化,优化方法为GD。
短评:本文是DARTS 的细化,将op 级推进到channel 级,并用于OD ,且是对主干网的搜索,效果比ResNet50主干网模型在COCO 数据集上平均提升1 个点左右。复用分类结构和巧妙使用dilation,可以视为一种对已有模型的优化方法。
总结
以上就是NeurIPS 2019 公布的7 篇NAS 论文简要分析。由于DARTS 的开源,掀起了一波NAS 热潮,在相关领域的研究者结合原有方法和DARTS,在不同任务(主动学习、IoT、目标检测、剪枝)上做了跟进。值得注意的是DetNAS,将One-Shot 路线应用于目标检测,这是一个标志性事件,笔者大胆预测NAS 将会是未来视觉等各分领域的SOTA 收割机。
小米AutoML 团队招聘
掌握NAS 技术最好的方法,并不是一篇篇撸paper,闷头实现,而是加入最前沿的已经有积累的团队,快速切入,一起攻占深度学习下半场制高点。笔者实习的小米AutoML 团队从今年初提出了MoreMNAS和FALSR,到最近在两个月间发布的三部曲FairNAS,MoGA,SCARLET,对原有技术不断迭代更新,成果连连,引起了业界的广泛关注。好消息是团队最近正在大力招聘中,有意向的同学请注明暗号“专知”,发简历给zhangbo11@xiaomi.com,社招/校招/实习均可,具体JD 可查看阅读原文。
7篇论文便捷下载:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“NAS” 就可以获取论文下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~



